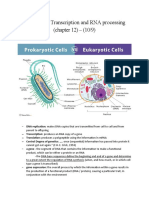
You might also like
- Gene ExpressionDocument19 pagesGene Expressionkvicto100% (1)
- Chapter IV Introduction To Bacterial Genetics-1Document67 pagesChapter IV Introduction To Bacterial Genetics-1temesgensemahegn55No ratings yet
- SYBT TranscriptionDocument69 pagesSYBT TranscriptionMeir SabooNo ratings yet
- Coursenotesdomain 4 InformationDocument29 pagesCoursenotesdomain 4 Informationapi-300668314No ratings yet
- Science FairDocument41 pagesScience FairSafanaNo ratings yet
- Microbial GeneticsDocument17 pagesMicrobial Geneticsزين العابدين محمد عويش مشريNo ratings yet
- Chapter 2 ExamKrackers Biomolecules GeneticsDocument8 pagesChapter 2 ExamKrackers Biomolecules GeneticsPatricia CosNo ratings yet
- DNA Transcription - Learn Science at ScitableDocument4 pagesDNA Transcription - Learn Science at ScitableSheryl Lin Dayrit DolorNo ratings yet
- Transcriprion ManuscriptDocument14 pagesTranscriprion ManuscriptAsif AhmedNo ratings yet
- How The Genes Are Regulated & Expressed?: AssignmentDocument17 pagesHow The Genes Are Regulated & Expressed?: AssignmentSuraiya Siraj NehaNo ratings yet
- Replication - Transcription - TranslationDocument75 pagesReplication - Transcription - TranslationJason FryNo ratings yet
- Replication, Transcription, Translation and Its Regulation: By, University of Agricultural Sciences, DharwadDocument42 pagesReplication, Transcription, Translation and Its Regulation: By, University of Agricultural Sciences, DharwadTabada NickyNo ratings yet
- Molecular BiologyDocument9 pagesMolecular Biologyrifat RasheedNo ratings yet
- Section 4Document8 pagesSection 4Aaron RajeshNo ratings yet
- PDF 20230417 225731 0000Document27 pagesPDF 20230417 225731 0000Maye JorcaNo ratings yet
- Microbiology With Diseases by Body System 4Th Edition Bauman Solutions Manual Full Chapter PDFDocument30 pagesMicrobiology With Diseases by Body System 4Th Edition Bauman Solutions Manual Full Chapter PDFlloydkieran71epfi100% (10)
- Microbiology With Diseases by Body System 4th Edition Bauman Solutions ManualDocument9 pagesMicrobiology With Diseases by Body System 4th Edition Bauman Solutions Manualzacharymeliora0h86100% (31)
- Microbiology With Diseases by Body System 4th Edition Bauman Solutions ManualDocument39 pagesMicrobiology With Diseases by Body System 4th Edition Bauman Solutions Manualcharles90br100% (13)
- Chapter 12 Biol1010 Notes-1-1Document4 pagesChapter 12 Biol1010 Notes-1-1yazst.julienNo ratings yet
- Cell Biology: InstructorDocument20 pagesCell Biology: Instructorahmed mediaNo ratings yet
- DNA Central Dogma ExplainedDocument19 pagesDNA Central Dogma ExplainedVerlyn Mae L. MatituNo ratings yet
- Different TranscriptionDocument3 pagesDifferent TranscriptionAznoer RanNo ratings yet
- Transcription WorkingDocument51 pagesTranscription Workingapi-3858544No ratings yet
- How Cells Work: The Central DogmaDocument18 pagesHow Cells Work: The Central DogmaJocelyn Diaz AbangNo ratings yet
- Information Transfer: Central Dogma of Molecular BiologyDocument22 pagesInformation Transfer: Central Dogma of Molecular BiologyAvirup RayNo ratings yet
- Bacterial Genetics in 40 CharactersDocument14 pagesBacterial Genetics in 40 Charactersعلي الكوافيNo ratings yet
- Central Dogma FlowDocument8 pagesCentral Dogma FlowAvirup RayNo ratings yet
- Genetics Exam ReviewerDocument9 pagesGenetics Exam ReviewerEysi BarangganNo ratings yet
- What Is DNADocument5 pagesWhat Is DNA꧁༒૮αll ʍ૯ ૨αj༒꧂No ratings yet
- Dna Repl Molecular GeneticsDocument8 pagesDna Repl Molecular GeneticsAmna NawazNo ratings yet
- BIOLOGY PROJECT TranslationDocument24 pagesBIOLOGY PROJECT Translationaryan1906mishraNo ratings yet
- TranscriptionDocument25 pagesTranscriptionYamunaa ElencovanNo ratings yet
- Regulation of Gene ExpressionDocument7 pagesRegulation of Gene ExpressionGodwin UnimashiNo ratings yet
- TranscriptionDocument4 pagesTranscriptionkaiaNo ratings yet
- Structure of DNA Science Presentation in Light Blue Green Lined Style 20240314 1Document26 pagesStructure of DNA Science Presentation in Light Blue Green Lined Style 20240314 1leighariazbongsNo ratings yet
- Molecular Biology Module 2 OverviewDocument15 pagesMolecular Biology Module 2 OverviewNanette MangloNo ratings yet
- Gene Expression: Dr. Nor'Aishah HasanDocument57 pagesGene Expression: Dr. Nor'Aishah HasanLutfil HadiNo ratings yet
- FALLSEM2023-24 BBIT307L TH VL2023240100207 2023-04-26 Reference-Material-IDocument29 pagesFALLSEM2023-24 BBIT307L TH VL2023240100207 2023-04-26 Reference-Material-IDrishti BisuiNo ratings yet
- Gene Concept EvolutionDocument20 pagesGene Concept Evolutionshahena sNo ratings yet
- Gene Expression Central DogmaDocument7 pagesGene Expression Central DogmaSualeha FatimaNo ratings yet
- Pro TranscriptionDocument20 pagesPro TranscriptionnitralekhaNo ratings yet
- Biochem 14 Chap 24Document60 pagesBiochem 14 Chap 24'chaca' Dian Catur PermatasariNo ratings yet
- Science Finals Reviewer: Nucleic Acid and Their Connection With Inheritance (E-Book Pages 261-262)Document5 pagesScience Finals Reviewer: Nucleic Acid and Their Connection With Inheritance (E-Book Pages 261-262)Mareck VerdanNo ratings yet
- BIO353 Lecture 10 mRNA SplicingDocument8 pagesBIO353 Lecture 10 mRNA SplicingMina KoçNo ratings yet
- BCH 323 NotesDocument41 pagesBCH 323 NotesvictorNo ratings yet
- Anatomy of A GeneDocument33 pagesAnatomy of A GenemskikiNo ratings yet
- 05-02-Genetika MikroorganismeDocument48 pages05-02-Genetika MikroorganismeKinad DanikNo ratings yet
- Differential GENE EXPRESSIONDocument20 pagesDifferential GENE EXPRESSIONUsama ElahiNo ratings yet
- DNA-Genes, Transcription, Translation and Inheritance ExplainedDocument2 pagesDNA-Genes, Transcription, Translation and Inheritance ExplainedLouis AmorNo ratings yet
- ESCI 2nd QTRDocument8 pagesESCI 2nd QTRBye Not thisNo ratings yet
- H2 Biology - Notes On Organisation and Control of Prokaryotic and Eukaryotic GenomesDocument15 pagesH2 Biology - Notes On Organisation and Control of Prokaryotic and Eukaryotic GenomesSefLRho100% (5)
- Gene Expression (Autosaved)Document39 pagesGene Expression (Autosaved)Mohammad RameezNo ratings yet
- Unit: 07: Mechanism of Cellular Differentiation / Differential Gene ExpressionDocument76 pagesUnit: 07: Mechanism of Cellular Differentiation / Differential Gene ExpressionMuhammad SibtainNo ratings yet
- Central Dogma: Dna ReplicationDocument18 pagesCentral Dogma: Dna ReplicationAkhil KumarNo ratings yet
- Lecture 2 - Transcription and RNA ProcessingDocument22 pagesLecture 2 - Transcription and RNA ProcessingErika KulićNo ratings yet
- Technological Institute of The Philippines 363 P. Casal ST., Quiapo, ManilaDocument6 pagesTechnological Institute of The Philippines 363 P. Casal ST., Quiapo, ManilaGellene GarciaNo ratings yet
- 4 Gene ExpressionDocument35 pages4 Gene ExpressionThảo ThảoNo ratings yet
- Chapter 6Document69 pagesChapter 6علوم طبية AUG 2020No ratings yet
- Transcription in ProkaryotesDocument18 pagesTranscription in ProkaryotesPrakash100% (1)
- Identification of General Transcription Factor-Two-E and Mediator Complex Interactions in The Context of Pre-Initiation Complex FormationDocument83 pagesIdentification of General Transcription Factor-Two-E and Mediator Complex Interactions in The Context of Pre-Initiation Complex Formationmunevver099kandemirNo ratings yet
- Genetic Regulation of Fixcion of NitrogenDocument11 pagesGenetic Regulation of Fixcion of NitrogenDiegoNo ratings yet
- 11.1.proteins Interacting With DNA Turn Prokaryotic Genes On or Off in Response To Environmental ChangesDocument16 pages11.1.proteins Interacting With DNA Turn Prokaryotic Genes On or Off in Response To Environmental Changeshanatabbal19No ratings yet
- Transcription in Prokaryotes: Dindin H. Mursyidin Laboratory of Molecular Biology Lambung Mangkurat UniversityDocument39 pagesTranscription in Prokaryotes: Dindin H. Mursyidin Laboratory of Molecular Biology Lambung Mangkurat UniversityNadia Nur FitriaNo ratings yet
- 17 Control of Gene Expression in Prokaryotes-S PDFDocument8 pages17 Control of Gene Expression in Prokaryotes-S PDFHelp Me Study TutoringNo ratings yet
- Molecular Basis of Inheritance MCQsDocument23 pagesMolecular Basis of Inheritance MCQsUrja MoonNo ratings yet
- Eukaryotic TranscriptionDocument16 pagesEukaryotic TranscriptionKunal DuttaNo ratings yet
- Lac Operon - Genetics-Essentials-Concepts-and-ConnectionsDocument15 pagesLac Operon - Genetics-Essentials-Concepts-and-ConnectionsDiandra AnnisaNo ratings yet
- BIOCORE I Midterm II Study Guide: Gene ExpressionDocument44 pagesBIOCORE I Midterm II Study Guide: Gene ExpressionWarren EnglishNo ratings yet
- NCERT Exemplar For Class 12 Biology Chapter 6Document31 pagesNCERT Exemplar For Class 12 Biology Chapter 6Me RahaviNo ratings yet
- Stickleback GeneSwitches StudentDocument10 pagesStickleback GeneSwitches StudentHelp Me Study TutoringNo ratings yet
- Allosteric regulation overviewDocument7 pagesAllosteric regulation overviewANIS NURALYSA AFFENDINo ratings yet
- The Making of The Fittest: Evolving Switches, Evolving BodiesDocument13 pagesThe Making of The Fittest: Evolving Switches, Evolving BodiesZ. Miller07No ratings yet
- Biochemistry 7th Edition Campbell Test Bank DownloadDocument33 pagesBiochemistry 7th Edition Campbell Test Bank Downloaddaddockstudderyxeq100% (32)
- DNA TranscriptionDocument25 pagesDNA TranscriptionAkss ShauryaNo ratings yet
- Topic 4: Equilibrium Binding and Chemical KineticsDocument23 pagesTopic 4: Equilibrium Binding and Chemical KineticsBukti NegalNo ratings yet
- Galactose Metabolism in Saccharomyces CerevisiaeDocument12 pagesGalactose Metabolism in Saccharomyces CerevisiaeFarida RahayuNo ratings yet
- Lactoce OperonDocument26 pagesLactoce OperonnikhilsathwikNo ratings yet
- Molecular Regulation2Document24 pagesMolecular Regulation2Atharva PurohitNo ratings yet
- Computational Genomics and Molecular Biology HomeworkDocument13 pagesComputational Genomics and Molecular Biology HomeworkAnas TubailNo ratings yet
- Microbiology 1.7 Bacterial Genetics Dr. EuropaDocument9 pagesMicrobiology 1.7 Bacterial Genetics Dr. EuropaRyn ShadowNo ratings yet
- StudentDocument12 pagesStudent김예진No ratings yet
- Bio Practice Questions For Final Exam Biol 1101Document5 pagesBio Practice Questions For Final Exam Biol 1101Megadirectioner 21No ratings yet
- Regulación Por AtenuaciónDocument5 pagesRegulación Por AtenuaciónKaryme Aylín Martinez OliverosNo ratings yet
- FullDocument1,497 pagesFullSyasa PembayunNo ratings yet
- Gene Regulation in Eukaryotes: How Genes Are RegulatedDocument72 pagesGene Regulation in Eukaryotes: How Genes Are RegulatedVinod NNo ratings yet
- USF Genetics Unit 4 Exam ReviewDocument3 pagesUSF Genetics Unit 4 Exam ReviewEmma DanelloNo ratings yet
- Deciphering Gene Regulation in the Mal OperonDocument47 pagesDeciphering Gene Regulation in the Mal OperonGloria LiNo ratings yet
- CRISPR Guide Provides Overview of Genome Editing TechnologyDocument18 pagesCRISPR Guide Provides Overview of Genome Editing TechnologyThomasNo ratings yet
- Regulation of Lactose Metabolism (Positive and Negative) : Molecular Biology AssignmentDocument20 pagesRegulation of Lactose Metabolism (Positive and Negative) : Molecular Biology AssignmentswarNo ratings yet