You might also like
- International Commercial Agency Contract Template SampleDocument6 pagesInternational Commercial Agency Contract Template SampleladyreveurNo ratings yet
- Air Ticket ReservationDocument28 pagesAir Ticket ReservationPK STUDIO HD0% (1)
- THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"From EverandTHE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE: "THE STEP BY STEP GUIDE FOR SUCCESSFUL IMPLEMENTATION OF DATA LAKE-LAKEHOUSE-DATA WAREHOUSE"Rating: 3 out of 5 stars3/5 (1)
- DBMS MaterialDocument70 pagesDBMS MaterialMitesh PujaraNo ratings yet
- Abinitio Scenarios QuestionDocument33 pagesAbinitio Scenarios QuestionAashrita VermaNo ratings yet
- Reactive Spring X PDFDocument246 pagesReactive Spring X PDFThomas YatesNo ratings yet
- Database FundamentalsDocument38 pagesDatabase FundamentalshkgraoNo ratings yet
- Database Systems Explained: Data, Information, Design and ManagementDocument33 pagesDatabase Systems Explained: Data, Information, Design and ManagementNeil Basabe100% (1)
- SQL Injection StrategiesDocument211 pagesSQL Injection StrategiesMireyNo ratings yet
- Chap 1 - Fundamentals of Database SystemsDocument48 pagesChap 1 - Fundamentals of Database SystemsNakachew Aschalew100% (1)
- Qlikview Tips TricksDocument189 pagesQlikview Tips TricksRajesh Pillai100% (1)
- Lecture 4 - Process Design and Analysis (Lecturer)Document73 pagesLecture 4 - Process Design and Analysis (Lecturer)DibyeshNo ratings yet
- Lecture 4 - Process Design and Analysis (Lecturer)Document73 pagesLecture 4 - Process Design and Analysis (Lecturer)DibyeshNo ratings yet
- Lecture 4 - Process Design and Analysis (Lecturer)Document73 pagesLecture 4 - Process Design and Analysis (Lecturer)DibyeshNo ratings yet
- Airline Reservation SystemDocument13 pagesAirline Reservation SystemInpreet KaurNo ratings yet
- DBMS Project ReportDocument24 pagesDBMS Project Reportericmsc84% (38)
- ABAP Predefined Types and Database ObjectsDocument27 pagesABAP Predefined Types and Database ObjectsAles Kosi100% (2)
- Unit I - Introduction To DatabaseDocument31 pagesUnit I - Introduction To DatabaseGaurav Patni100% (1)
- Chapter 1 - Introduction To Database SystemDocument27 pagesChapter 1 - Introduction To Database SystemsfdNo ratings yet
- Good Database Design Will Get You Through PoorDocument50 pagesGood Database Design Will Get You Through PoorKofiNo ratings yet
- Relational Database Management Systems: UNIT-1Document120 pagesRelational Database Management Systems: UNIT-1Srinivas KanakalaNo ratings yet
- Database SystemsDocument104 pagesDatabase SystemsLanreFalolaNo ratings yet
- CUAP DBMS Notes Unit11Document31 pagesCUAP DBMS Notes Unit11sahil rajNo ratings yet
- DBMS Unit 1Document28 pagesDBMS Unit 1Dr. Durga Prasad DogiparthiNo ratings yet
- Chapter-1 Notes - IntroductionDocument17 pagesChapter-1 Notes - IntroductionAdfar RashidNo ratings yet
- 1 IntroductionDocument28 pages1 IntroductionYubaraj MallaNo ratings yet
- Database Management: Dr. Md. Rakibul Hoque University of DhakaDocument57 pagesDatabase Management: Dr. Md. Rakibul Hoque University of DhakaShahriar HaqueNo ratings yet
- Database Management Systems (CS251)Document28 pagesDatabase Management Systems (CS251)Devika HarikrishnanNo ratings yet
- CH 1Document19 pagesCH 1Ashenafi EliasNo ratings yet
- DBMSDocument70 pagesDBMSGitte DnyaneshwarNo ratings yet
- DBMS Unit 1,2 Notes - R21Document105 pagesDBMS Unit 1,2 Notes - R21eswar pNo ratings yet
- HW-1 Answers DBMT KeyDocument9 pagesHW-1 Answers DBMT Keykarthikeyan RNo ratings yet
- Unit 1 - Week1-Text LearningDocument7 pagesUnit 1 - Week1-Text LearningaaquibcaptainamericaNo ratings yet
- Information Technology: Chapter TwoDocument56 pagesInformation Technology: Chapter TwoĒrmias ÁlemayehuNo ratings yet
- Mit Database NotesDocument703 pagesMit Database NotesGrant DuncanNo ratings yet
- Database Management system chapter oneDocument137 pagesDatabase Management system chapter onemehari kirosNo ratings yet
- Database Management SystemsDocument191 pagesDatabase Management SystemsGangaa Shelvi100% (1)
- 1 Introduction To Database SystemsDocument50 pages1 Introduction To Database SystemsMiya SamaNo ratings yet
- Chapter 1 Introduction To DBMS PDFDocument6 pagesChapter 1 Introduction To DBMS PDFVidhyaNo ratings yet
- Unit - 1 Introduction To Database Management SystemDocument20 pagesUnit - 1 Introduction To Database Management Systemhabib0999No ratings yet
- DBMS Ctevt StudentsDocument230 pagesDBMS Ctevt StudentsDeepena PrykNo ratings yet
- Fundamentals of Database Management Systems (Cosc2041) : Introduction Database Management System Compiled By: Debritu ADocument20 pagesFundamentals of Database Management Systems (Cosc2041) : Introduction Database Management System Compiled By: Debritu ADinksrawNo ratings yet
- MIS: Database, Lecture-1Document81 pagesMIS: Database, Lecture-1Sunjida EnamNo ratings yet
- Database Management System Module 1 OverviewDocument21 pagesDatabase Management System Module 1 OverviewTanai ThrineshNo ratings yet
- To Databases: Data BasesDocument22 pagesTo Databases: Data BasesPrashant RawasNo ratings yet
- Unit 1dbmsDocument41 pagesUnit 1dbmssohangashiranaNo ratings yet
- Chapter One 1. Data: CH-1: DatabaseDocument9 pagesChapter One 1. Data: CH-1: DatabasertyiookNo ratings yet
- Chapter 1Document9 pagesChapter 1eyasuNo ratings yet
- DatabaseDocument22 pagesDatabaseErmyas YirsawNo ratings yet
- Chapter One Introduction To Database Concepts: Data, Information, Information SystemDocument24 pagesChapter One Introduction To Database Concepts: Data, Information, Information SystemDagimb BekeleNo ratings yet
- Database Management System UNIT-1Document199 pagesDatabase Management System UNIT-10fficial SidharthaNo ratings yet
- DBMSDocument52 pagesDBMSjjs17No ratings yet
- Mis - Data Files and DatabasesDocument40 pagesMis - Data Files and DatabasesSaikatiNo ratings yet
- Dbms NotesDocument84 pagesDbms NotesJugal K Sewag100% (1)
- Quiz DatabaseDocument3 pagesQuiz DatabaseKawai NezukoNo ratings yet
- A Brief History of Database SystemsDocument4 pagesA Brief History of Database SystemsFawad Masood100% (1)
- Database Management System OverviewDocument70 pagesDatabase Management System OverviewDeekonda AshwiniNo ratings yet
- Databases and Database Users: ImportanceDocument36 pagesDatabases and Database Users: ImportanceRajesh KumarNo ratings yet
- DB Lecture Note All in ONEDocument229 pagesDB Lecture Note All in ONESmachew GedefawNo ratings yet
- Data, fields, records and files explainedDocument6 pagesData, fields, records and files explainedaim_nainaNo ratings yet
- Database Design Concepts Introduction NotesDocument42 pagesDatabase Design Concepts Introduction NotesmunatsiNo ratings yet
- Databases - Lecture 1Document21 pagesDatabases - Lecture 1thelangastamperNo ratings yet
- Chapter 1Document53 pagesChapter 1mekuriameku99No ratings yet
- Database Basics IntroductionDocument20 pagesDatabase Basics IntroductionshanutinkuNo ratings yet
- Module 1Document111 pagesModule 1Ronit ReddyNo ratings yet
- Chapter 1 - Introduction To Database NotesDocument12 pagesChapter 1 - Introduction To Database NotesDibyeshNo ratings yet
- Database fundamentals and componentsDocument8 pagesDatabase fundamentals and componentsramaNo ratings yet
- DB Lecture Chapter 1-3Document58 pagesDB Lecture Chapter 1-3Gemechis GurmesaNo ratings yet
- DBMS Unit-1Document38 pagesDBMS Unit-1prabandha puttiNo ratings yet
- DBMS - Chapter 1Document45 pagesDBMS - Chapter 1Harapriya MohantaNo ratings yet
- MarketingDocument20 pagesMarketingDibyeshNo ratings yet
- Organisational Structures 2Document17 pagesOrganisational Structures 2DibyeshNo ratings yet
- My Routine 2001123 Winter Nov 23 to Apr 24Document232 pagesMy Routine 2001123 Winter Nov 23 to Apr 24DibyeshNo ratings yet
- Operations MgtDocument16 pagesOperations MgtDibyeshNo ratings yet
- Project ManagementPre Board QuestionDocument9 pagesProject ManagementPre Board QuestionDibyeshNo ratings yet
- Global EnvironmentDocument13 pagesGlobal EnvironmentDibyeshNo ratings yet
- Lecture 2 Company and Marketing Strategy (Lecturer) 130612 - July 2013Document63 pagesLecture 2 Company and Marketing Strategy (Lecturer) 130612 - July 2013DibyeshNo ratings yet
- Lecture 2 Company and Marketing Strategy (Lecturer) 130612 - July 2013Document63 pagesLecture 2 Company and Marketing Strategy (Lecturer) 130612 - July 2013DibyeshNo ratings yet
- Organisational Structures 2Document17 pagesOrganisational Structures 2DibyeshNo ratings yet
- PM - Unit 3Document5 pagesPM - Unit 3DibyeshNo ratings yet
- Chapter 2Document63 pagesChapter 2DibyeshNo ratings yet
- Brief History of e CommerceDocument10 pagesBrief History of e CommerceDibyeshNo ratings yet
- Sale of Goods LawDocument7 pagesSale of Goods LawStefan Pius DsouzaNo ratings yet
- Supplementary Reading and Study Materials CH 2 Company and Marketing StrategyDocument1 pageSupplementary Reading and Study Materials CH 2 Company and Marketing StrategyDibyeshNo ratings yet
- Agency AgreementDocument3 pagesAgency AgreementkmNo ratings yet
- Case Study Enterprise-Rent-A-Car-Edition-17-Full - RevisedDocument5 pagesCase Study Enterprise-Rent-A-Car-Edition-17-Full - RevisedDibyeshNo ratings yet
- Lecture 7 - Supply Chain Management StudentDocument15 pagesLecture 7 - Supply Chain Management StudentDibyeshNo ratings yet
- Lecture 8 - Demand Management StudentDocument55 pagesLecture 8 - Demand Management StudentDibyeshNo ratings yet
- Lecture 8 - Demand Management StudentDocument55 pagesLecture 8 - Demand Management StudentDibyeshNo ratings yet
- Tutorial 7 - Supply Chain Management (Student)Document4 pagesTutorial 7 - Supply Chain Management (Student)DibyeshNo ratings yet
- Lecture 8 - Demand Management StudentDocument55 pagesLecture 8 - Demand Management StudentDibyeshNo ratings yet
- 8 Transaction-ProcessingDocument55 pages8 Transaction-ProcessingDibyeshNo ratings yet
- Chapter 2.1-Data Modelling and ER DiagramsDocument16 pagesChapter 2.1-Data Modelling and ER DiagramsDibyeshNo ratings yet
- Identifying Relationship and Weak RelationshipDocument4 pagesIdentifying Relationship and Weak RelationshipDibyeshNo ratings yet
- Explanation of Slide 8Document5 pagesExplanation of Slide 8DibyeshNo ratings yet
- Data Warehouse 14regDocument2 pagesData Warehouse 14regPonni SNo ratings yet
- 2nd PUC Labmanual - FinalDocument58 pages2nd PUC Labmanual - FinalbhuvanalmathNo ratings yet
- From case frames to semantic frames: The development of Frame SemanticsDocument25 pagesFrom case frames to semantic frames: The development of Frame SemanticsWilliam BosichNo ratings yet
- Rules in Prolog: Student Name Student Roll # Program SectionDocument10 pagesRules in Prolog: Student Name Student Roll # Program Sectionchudyf100% (1)
- SQL Manual NewDocument26 pagesSQL Manual New035Neeraja Goli100% (1)
- Project On Hotel ManagementDocument40 pagesProject On Hotel Managementdiyapaliwal14100% (1)
- SystemGuide Transaction-SoftwareDocument59 pagesSystemGuide Transaction-SoftwareRSNo ratings yet
- C - SAC - 2221Q&A80 Dumps NWDocument18 pagesC - SAC - 2221Q&A80 Dumps NWRekhaNo ratings yet
- Windows Workflow Foundation (WF)Document31 pagesWindows Workflow Foundation (WF)Cao Xuan DuyNo ratings yet
- The Northwind DatabaseDocument3 pagesThe Northwind DatabaseSindi Yamileth Carranza CarranzaNo ratings yet
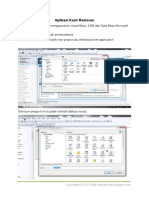
- Aplikasi Kasir RestoranDocument17 pagesAplikasi Kasir RestoranAsepNo ratings yet
- CV - Vo Thanh Phu - JavaDocument2 pagesCV - Vo Thanh Phu - JavaDUMP VNNo ratings yet
- Data Science MCQ Model Questions Sem 6 TYCS CS/IT DeptDocument7 pagesData Science MCQ Model Questions Sem 6 TYCS CS/IT DeptTF TECHNo ratings yet
- Server Side Scripting PHPDocument99 pagesServer Side Scripting PHPAspen ThrushNo ratings yet
- Database Management System Class 10 Question BankDocument56 pagesDatabase Management System Class 10 Question Banktfpalo4No ratings yet
- Introductory SessionDocument12 pagesIntroductory SessionAyush GuptaNo ratings yet
- Integrity ConstraintsDocument8 pagesIntegrity ConstraintsVAISHNAVI H ECE2019No ratings yet
- Masking Salesforce Via JDBC - Application SolutionsDocument3 pagesMasking Salesforce Via JDBC - Application SolutionsRajat SolankiNo ratings yet
- I/A Series Aim at Suite Aim Datalink, Version 2.5 User'S GuideDocument174 pagesI/A Series Aim at Suite Aim Datalink, Version 2.5 User'S GuidesaratchandranbNo ratings yet
- Artificial Intelligence in Knowledge Management Overview and TrendDocument8 pagesArtificial Intelligence in Knowledge Management Overview and Trendecsudca100% (1)
- NoSQL Doc DB LabDocument18 pagesNoSQL Doc DB LabNuwan ChamikaraNo ratings yet
- Java JDBC Database Access LabDocument27 pagesJava JDBC Database Access LabMSG CollegeNo ratings yet
- Ajay Kadiyala Resume 2023 PDFDocument6 pagesAjay Kadiyala Resume 2023 PDFviki awsacNo ratings yet