
100% found this document useful (1 vote)
372 views57 pagesPattern Matching in Digital Forensics
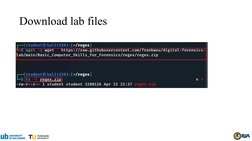
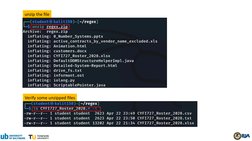
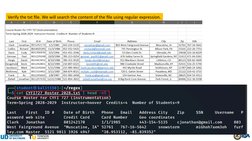
This document provides an overview of using regular expressions to search for patterns in digital evidence. It discusses different types of patterns that can be matched, such as personal information, usernames/passwords, source code, network information, and file names. It then demonstrates how to write regular expressions to match names, phone numbers, emails, passwords, source code, websites, IP addresses, MAC addresses, and patterns from a pcap file. The document shows examples of simple patterns as well as more complex patterns using features like character classes, quantifiers, word boundaries, grouping, backreferences, lookarounds, and other regex syntax.
Uploaded by
wanCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
100% found this document useful (1 vote)
372 views57 pagesPattern Matching in Digital Forensics
This document provides an overview of using regular expressions to search for patterns in digital evidence. It discusses different types of patterns that can be matched, such as personal information, usernames/passwords, source code, network information, and file names. It then demonstrates how to write regular expressions to match names, phone numbers, emails, passwords, source code, websites, IP addresses, MAC addresses, and patterns from a pcap file. The document shows examples of simple patterns as well as more complex patterns using features like character classes, quantifiers, word boundaries, grouping, backreferences, lookarounds, and other regex syntax.
Uploaded by
wanCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd





![A simple pattern of all names
Frank_Xu
Frank
Xu
One
Uppercase
1-10
Lowercase
One
Uppercase
1-10
Lowercase
[A-Z]
[a-z]
Sp](https://screenshots.scribd.com/Scribd/252_100_85/141/667747564/9.jpeg)


























































































