You might also like
- The Best Sports Training Book Ever - D.B. HammerDocument136 pagesThe Best Sports Training Book Ever - D.B. HammerJaron Kung100% (3)
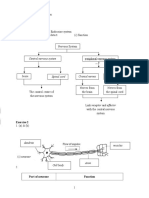
- The Nervous System Flashcards - QuizletDocument11 pagesThe Nervous System Flashcards - QuizletDani AnyikaNo ratings yet
- Neural NetworksDocument57 pagesNeural Networksalexaalex100% (1)
- Charotar University of Science and Technology Faculty of Technology and EngineeringDocument10 pagesCharotar University of Science and Technology Faculty of Technology and EngineeringSmruthi SuvarnaNo ratings yet
- Computer Architecture Comparch Unit Two PowerpointDocument51 pagesComputer Architecture Comparch Unit Two PowerpointKirubel MulugetaNo ratings yet
- Notes of ANNDocument35 pagesNotes of ANNSahil GoyalNo ratings yet
- Memory Foundations and Applications (Bennett L. Schwartz)Document1,039 pagesMemory Foundations and Applications (Bennett L. Schwartz)thaicet1No ratings yet
- Artificial Neural NetworksDocument57 pagesArtificial Neural NetworksUI19EC21 Talluri issakuNo ratings yet
- Artificial Neural NetworksDocument24 pagesArtificial Neural Networkspunita singhNo ratings yet
- Advances in DIP: (Fuzzy, Artificial Neural Networks, Expert System and Image Segmentation)Document67 pagesAdvances in DIP: (Fuzzy, Artificial Neural Networks, Expert System and Image Segmentation)Farid_ZGNo ratings yet
- Child Development A Cultural Approach 2nd Edition Arnett Test Bank 1Document117 pagesChild Development A Cultural Approach 2nd Edition Arnett Test Bank 1joshua100% (36)
- Multilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksFrom EverandMultilayer Perceptron: Fundamentals and Applications for Decoding Neural NetworksNo ratings yet
- Bio Inspired Computing: Fundamentals and Applications for Biological Inspiration in the Digital WorldFrom EverandBio Inspired Computing: Fundamentals and Applications for Biological Inspiration in the Digital WorldNo ratings yet
- ML Ch-4 Artificial Neural NetworkDocument54 pagesML Ch-4 Artificial Neural NetworkNasis DerejeNo ratings yet
- CH 9: Connectionist ModelsDocument35 pagesCH 9: Connectionist ModelsAMI CHARADAVANo ratings yet
- Aditya Jain NN AssignmentDocument13 pagesAditya Jain NN AssignmentAditya JainNo ratings yet
- Chapter 5 1Document35 pagesChapter 5 1Dewanand GiriNo ratings yet
- ML Unit-3-1 Material WORDDocument16 pagesML Unit-3-1 Material WORDafreed khanNo ratings yet
- Artifical Neural NetworkDocument7 pagesArtifical Neural NetworkAby MathewNo ratings yet
- Unit 1Document9 pagesUnit 1keerthipraneetha0No ratings yet
- Neural NetworkDocument6 pagesNeural NetworkNiraj AcharyaNo ratings yet
- Module 5 AIML NotesDocument77 pagesModule 5 AIML Notesbabureddybn262003No ratings yet
- Artificial Intelligence Artificial Neural Networks - : IntroductionDocument43 pagesArtificial Intelligence Artificial Neural Networks - : IntroductionRawaz AzizNo ratings yet
- UNIT II Basic On Neural NetworksDocument36 pagesUNIT II Basic On Neural NetworksPoralla priyankaNo ratings yet
- AITools Unit-4Document25 pagesAITools Unit-4SivaNo ratings yet
- Unit I Architecture of Neural NetworkDocument74 pagesUnit I Architecture of Neural NetworkDSYMEC224Trupti BagalNo ratings yet
- Lecture-02: PGDDS 202Document15 pagesLecture-02: PGDDS 202Lony IslamNo ratings yet
- ANN (Perceptron and Multilayerd Perceptron)Document29 pagesANN (Perceptron and Multilayerd Perceptron)ANMOL SINGHNo ratings yet
- AI ProjectDocument29 pagesAI ProjectFighter Ops GamingNo ratings yet
- Implementation of Single Layer Perceptron Model Using MATLABDocument5 pagesImplementation of Single Layer Perceptron Model Using MATLABChriz AlducciniNo ratings yet
- Artificial Neural Network TutorialDocument8 pagesArtificial Neural Network Tutorialshanigondal126No ratings yet
- Perceptron: Single Layer Neural NetworkDocument14 pagesPerceptron: Single Layer Neural NetworkGayuNo ratings yet
- Neural NetworkDocument16 pagesNeural NetworkYawar AliNo ratings yet
- A R T I F I C I A L N e U R A L N e T W o R K SDocument27 pagesA R T I F I C I A L N e U R A L N e T W o R K SHarleen VirkNo ratings yet
- Artificial Neural Network: Synapses Weight The Individual Parts of InformationDocument8 pagesArtificial Neural Network: Synapses Weight The Individual Parts of InformationMaryam FarisNo ratings yet
- Fundamentals of Neural NetworksDocument24 pagesFundamentals of Neural NetworksManasranjan SahuNo ratings yet
- 17 C - Artificial Neural Networks - 1Document40 pages17 C - Artificial Neural Networks - 1Pratik RajNo ratings yet
- Group5 ProjectDocument CI 1081234315399613Document10 pagesGroup5 ProjectDocument CI 1081234315399613BellaNo ratings yet
- InTech-Introduction To The Artificial Neural Networks PDFDocument17 pagesInTech-Introduction To The Artificial Neural Networks PDFalexaalexNo ratings yet
- Artificial Neural Network Lecture 1Document9 pagesArtificial Neural Network Lecture 1Prince GodsplanNo ratings yet
- Artificial Intelligence in Robotics-21-50Document30 pagesArtificial Intelligence in Robotics-21-50Mustafa AlhumayreNo ratings yet
- Artificial Neural NetworksDocument43 pagesArtificial Neural NetworksIEC2020034No ratings yet
- DL Lab Assignment - AND GATEDocument4 pagesDL Lab Assignment - AND GATEProfessor ExeNo ratings yet
- Program Name: B.Tech Cse Course Name: Machine Learning Neural NetworksDocument17 pagesProgram Name: B.Tech Cse Course Name: Machine Learning Neural NetworksAastha KohliNo ratings yet
- Neural Networks NotesDocument22 pagesNeural Networks NoteszomukozaNo ratings yet
- Networks. These Are Formed From Trillions of Neurons (NerveDocument14 pagesNetworks. These Are Formed From Trillions of Neurons (NervePratiksha KambleNo ratings yet
- Neural NetworksDocument37 pagesNeural NetworksOmiarNo ratings yet
- 5 1 Neural NetworksDocument60 pages5 1 Neural NetworksDaystar YtNo ratings yet
- Artificial Neural NetworksDocument49 pagesArtificial Neural NetworksKinya KageniNo ratings yet
- Lecure 1 - IntroductionDocument45 pagesLecure 1 - Introductionvandunggroup5526No ratings yet
- Artificial Neural NetworkDocument20 pagesArtificial Neural NetworkYash PatelNo ratings yet
- Lec 12 - ANNDocument18 pagesLec 12 - ANN14 Asif AkhtarNo ratings yet
- DSS Chapter 6Document7 pagesDSS Chapter 6Mohamed Omar HalaneNo ratings yet
- Neural NetworkDocument29 pagesNeural NetworkEsha NawazNo ratings yet
- Unit 1: 1. Introduction To Artificial Neural NetworkDocument17 pagesUnit 1: 1. Introduction To Artificial Neural Networkjai geraNo ratings yet
- ASC Unit IDocument32 pagesASC Unit Iyou • were • trolledNo ratings yet
- Unit 2 Machine Learning NotesDocument25 pagesUnit 2 Machine Learning NotesRADHARAPU DIVYA PECNo ratings yet
- PraloyDocument19 pagesPraloysujit_royNo ratings yet
- Neural Network: BY, Deekshitha J P Rakshitha ShankarDocument27 pagesNeural Network: BY, Deekshitha J P Rakshitha ShankarDeekshitha J PNo ratings yet
- Unit 2Document18 pagesUnit 2Nitya ShuklaNo ratings yet
- Artificial Neural NetworkDocument9 pagesArtificial Neural Networkjyoti singhNo ratings yet
- CC511 Week 5 - 6 - NN - BPDocument62 pagesCC511 Week 5 - 6 - NN - BPmohamed sherifNo ratings yet
- Lec 21Document42 pagesLec 21ABHIRAJ ENo ratings yet
- 1.introduction To Artificial Neural Networks (ANNs)Document2 pages1.introduction To Artificial Neural Networks (ANNs)koezhuNo ratings yet
- Feedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsFrom EverandFeedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsNo ratings yet
- Unit 5Document45 pagesUnit 5Yasub DemissieNo ratings yet
- Unit 1hisDocument20 pagesUnit 1hisabebaw ataleleNo ratings yet
- 01-Finding A Niche With Examples Profitable Niches ProvidedDocument1 page01-Finding A Niche With Examples Profitable Niches ProvidedKirubel MulugetaNo ratings yet
- Chapter 6 HistoryDocument31 pagesChapter 6 HistoryKirubel Mulugeta100% (3)
- Peoples and Cultures in Ethiopia and The Horn: Chapter TwoDocument25 pagesPeoples and Cultures in Ethiopia and The Horn: Chapter TwoYasub Demissie100% (1)
- IP II Chapter FourDocument20 pagesIP II Chapter FourKirubel MulugetaNo ratings yet
- IP II Chapter ThreeDocument60 pagesIP II Chapter ThreeKirubel MulugetaNo ratings yet
- IP II Chapter TwoDocument40 pagesIP II Chapter TwoKirubel MulugetaNo ratings yet
- ST, Marry University Advanced Database Systems: Chapter OneDocument68 pagesST, Marry University Advanced Database Systems: Chapter OneKirubel MulugetaNo ratings yet
- Advanced Database Systems: Chapter 3:query Processing and EvaluationDocument36 pagesAdvanced Database Systems: Chapter 3:query Processing and EvaluationKirubel MulugetaNo ratings yet
- ADB - CH2 - Advanced SQLDocument60 pagesADB - CH2 - Advanced SQLAbenezer TeshomeNo ratings yet
- Computer Architecture Comparch Unit One PowerpointDocument54 pagesComputer Architecture Comparch Unit One PowerpointKirubel MulugetaNo ratings yet
- Advanced Database Systems: Chapter 4: Transaction ManagementDocument78 pagesAdvanced Database Systems: Chapter 4: Transaction ManagementKirubel MulugetaNo ratings yet
- SciPoultryAndMeatProcessing - Barbut - 03 Structure & Physiology - v01 PDFDocument42 pagesSciPoultryAndMeatProcessing - Barbut - 03 Structure & Physiology - v01 PDFalberto.afonso3748No ratings yet
- 23 Nervous System: Encounter The PhenomenonDocument5 pages23 Nervous System: Encounter The PhenomenonJasmine AlsheikhNo ratings yet
- Lab 8 The Nervous SystemDocument15 pagesLab 8 The Nervous Systemcindy tranNo ratings yet
- Module 2 Physical and Motor Development of Children and AdolescentDocument13 pagesModule 2 Physical and Motor Development of Children and Adolescentjaz bazNo ratings yet
- I. Physical Growth and Development in InfancyDocument3 pagesI. Physical Growth and Development in InfancyBernadette Ignacio CasiliNo ratings yet
- The Anatomy of The BrainDocument30 pagesThe Anatomy of The BrainCala WritesNo ratings yet
- Neuroscience Science of TheDocument60 pagesNeuroscience Science of TheALA Meditation - Relaxing MusicNo ratings yet
- Hes 006 Term 2Document18 pagesHes 006 Term 2Crishel Anne Cristobal100% (1)
- CHP 7 Class 10Document13 pagesCHP 7 Class 10sourabh nuwalNo ratings yet
- Neurotransmitters - QuizizzDocument6 pagesNeurotransmitters - QuizizzushduNo ratings yet
- Psychology and Life 20th Edition Gerrig Test BankDocument50 pagesPsychology and Life 20th Edition Gerrig Test BankquwirNo ratings yet
- Answer Chapter 2Document10 pagesAnswer Chapter 2Zailinda ZakariaNo ratings yet
- Lecture Outline: See Separate Powerpoint Slides For All Figures and Tables Pre-Inserted Into Powerpoint Without NotesDocument119 pagesLecture Outline: See Separate Powerpoint Slides For All Figures and Tables Pre-Inserted Into Powerpoint Without Notesellie marcusNo ratings yet
- Jellyfish Nervous SystemDocument5 pagesJellyfish Nervous Systembrain-neuroscience research teamNo ratings yet
- Genral Motor Function, SC and Muscle SpindlesDocument41 pagesGenral Motor Function, SC and Muscle SpindlesnoufNo ratings yet
- Animal Tissue - DPPsDocument27 pagesAnimal Tissue - DPPsMd FaijalNo ratings yet
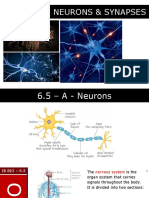
- 6.5 Neurons SynapsesDocument57 pages6.5 Neurons SynapsesTae Soo LeeNo ratings yet
- 08 Intro Nervous System Coloring BookDocument4 pages08 Intro Nervous System Coloring BookArmy JmNo ratings yet
- Psy Chapter 2Document146 pagesPsy Chapter 2OceanNo ratings yet
- Biology M9 Life Support SystemsDocument30 pagesBiology M9 Life Support SystemsRichele FloresNo ratings yet
- Final NeuronotesDocument16 pagesFinal Neuronotesapi-479939114No ratings yet
- Chap-21 Neural Control and CordinationDocument48 pagesChap-21 Neural Control and CordinationMANIK CHHABRANo ratings yet
- 5Document2 pages5Academic ServicesNo ratings yet
- BIBLIOGRAFIE Neural Conduction Synaptic TransmisionDocument16 pagesBIBLIOGRAFIE Neural Conduction Synaptic TransmisionMirela GiurgeaNo ratings yet
- NMS Physiology PDFDocument502 pagesNMS Physiology PDFPrabjot SehmiNo ratings yet
- Interactive Action PotentialsDocument7 pagesInteractive Action PotentialsNESLEY REANNE VILLAMIELNo ratings yet