You might also like
- Advance Cluster - Classification: Ha Le Hoai TrungDocument50 pagesAdvance Cluster - Classification: Ha Le Hoai TrungPhuong Nguyen Thi BichNo ratings yet
- ClassificationDocument58 pagesClassificationlekhaNo ratings yet
- Evaluation Method HoldoutDocument14 pagesEvaluation Method Holdoutjemal yahyaaNo ratings yet
- Model Evaluation and SelectionDocument37 pagesModel Evaluation and SelectionSmitNo ratings yet
- 2 Supervised LearningDocument52 pages2 Supervised LearningAhlam AzamNo ratings yet
- Lecture 01-Model Selection and EvaluationDocument29 pagesLecture 01-Model Selection and Evaluationmah dltNo ratings yet
- CST 42315 Dam - L9 1Document15 pagesCST 42315 Dam - L9 1Kay KhineNo ratings yet
- Presentation On ClassificationDocument18 pagesPresentation On Classificationsree vishnupriyqNo ratings yet
- ML Model EvaluationDocument17 pagesML Model EvaluationSTYXNo ratings yet
- Module 5 Advanced Classification TechniquesDocument40 pagesModule 5 Advanced Classification TechniquesSaurabh JagtapNo ratings yet
- Model Evaluation and SelectionDocument41 pagesModel Evaluation and SelectionDev kartik AgarwalNo ratings yet
- Accuracy MeasuresDocument61 pagesAccuracy MeasuresSanoop MallisseryNo ratings yet
- Lecture 3 1611410001002Document51 pagesLecture 3 1611410001002amrasirahNo ratings yet
- Lecture 2 Classifier Performance MetricsDocument60 pagesLecture 2 Classifier Performance Metricsiamboss086No ratings yet
- 8c - Model Evaluation and SelectionDocument15 pages8c - Model Evaluation and SelectionZafar IqbalNo ratings yet
- Data Mining Models and Evaluation TechniquesDocument59 pagesData Mining Models and Evaluation Techniquesspsberry8No ratings yet
- Lecture 16Document36 pagesLecture 16Abood FazilNo ratings yet
- Data Mining: Practical Machine Learning Tools and TechniquesDocument73 pagesData Mining: Practical Machine Learning Tools and TechniquesArvindNo ratings yet
- CSC4316 9Document40 pagesCSC4316 9Jamil SalisNo ratings yet
- Classification 2Document18 pagesClassification 2pppchan23100No ratings yet
- 15 dm2 Imbalanced Learning 2022 23Document35 pages15 dm2 Imbalanced Learning 2022 23nimraNo ratings yet
- Classification EvaluationDocument28 pagesClassification EvaluationKathy KgNo ratings yet
- Chap3 Part1 ClassificationDocument38 pagesChap3 Part1 Classificationhoucem.swissiNo ratings yet
- Cross-Validation and Model SelectionDocument46 pagesCross-Validation and Model Selectionneelam sanjeev kumarNo ratings yet
- DM - Ch4 - Classification (Part1)Document20 pagesDM - Ch4 - Classification (Part1)C.RadhiyaDeviNo ratings yet
- Chapter 5 Evaluation MetricsDocument18 pagesChapter 5 Evaluation Metricsliyu agyeNo ratings yet
- CSO504 Machine Learning: Evaluation and Error Analysis Validation and Regularization Koustav Rudra 22/08/2022Document28 pagesCSO504 Machine Learning: Evaluation and Error Analysis Validation and Regularization Koustav Rudra 22/08/2022Being IITianNo ratings yet
- Estimating The Predictive Accuracy of ADocument10 pagesEstimating The Predictive Accuracy of AMiguel pilamungaNo ratings yet
- Predictive Accuracy EvaluationDocument13 pagesPredictive Accuracy EvaluationSarFaraz Ali MemonNo ratings yet
- Tutorial 6 Evaluation Metrics For Machine Learning Models: Classification and Regression ModelsDocument22 pagesTutorial 6 Evaluation Metrics For Machine Learning Models: Classification and Regression ModelsWenbo PanNo ratings yet
- Univt - IVDocument72 pagesUnivt - IVmananrawat537No ratings yet
- DM - ModelEvaluation CH 3Document14 pagesDM - ModelEvaluation CH 3Hasset Tiss Abay GenjiNo ratings yet
- Maths For Chemists: Module I - Quantitative Chemistry: UnitsDocument6 pagesMaths For Chemists: Module I - Quantitative Chemistry: UnitsNicholas OwNo ratings yet
- KNN ALGORITHM IN MACHINELEARNINGDocument10 pagesKNN ALGORITHM IN MACHINELEARNINGnithinmamidala999No ratings yet
- Combining Classifiers: OutlineDocument15 pagesCombining Classifiers: Outlinejawad_shahNo ratings yet
- Lesson 2-Error EstimationDocument14 pagesLesson 2-Error EstimationNarnah Adanse Qwehku JaphethNo ratings yet
- Clustering - KNNDocument10 pagesClustering - KNNSiddharth DoshiNo ratings yet
- Chapter 4 EconometricDocument32 pagesChapter 4 EconometricmukeshNo ratings yet
- Model EvaluationDocument80 pagesModel EvaluationDeva Hema DNo ratings yet
- Permutational Non-Parametric Tests: "There Are Two Kinds of Statistics, The Kind You Look Up and The Kind You Make Up."Document8 pagesPermutational Non-Parametric Tests: "There Are Two Kinds of Statistics, The Kind You Look Up and The Kind You Make Up."Roberto García AguilarNo ratings yet
- Final Exam ReviewDocument46 pagesFinal Exam ReviewBalamurugan KarnanNo ratings yet
- Confusion Matrix: Dr. P. K. ChaurasiaDocument13 pagesConfusion Matrix: Dr. P. K. Chaurasiaaimsneet7No ratings yet
- Cross-Validation in Machine LearningDocument18 pagesCross-Validation in Machine LearningPriya dharshini.GNo ratings yet
- Stat Q4 Mod 4 Test Statistic On Population Mean - Removed - RemovedDocument17 pagesStat Q4 Mod 4 Test Statistic On Population Mean - Removed - RemovedAmos AJNo ratings yet
- L9 Model AssessmentDocument26 pagesL9 Model AssessmentHieu Tien TrinhNo ratings yet
- Machine Learning and Data Mining: Introduction to (Học máy và Khai phá dữ liệu)Document26 pagesMachine Learning and Data Mining: Introduction to (Học máy và Khai phá dữ liệu)Lộc SẹoNo ratings yet
- Chi Square TestDocument16 pagesChi Square TestdaveasuNo ratings yet
- Program 9 (KNN) 2020Document55 pagesProgram 9 (KNN) 2020Vijay Sathvika BNo ratings yet
- Assignment 3Document8 pagesAssignment 3mohamedmariam490No ratings yet
- Model Evaluation: Dr.K.Murugan Assistant Professor Senior VIT, VelloreDocument29 pagesModel Evaluation: Dr.K.Murugan Assistant Professor Senior VIT, VelloreChidvi ReddyNo ratings yet
- Model Evaluation and SelectionDocument22 pagesModel Evaluation and SelectiondiscodancerhasanNo ratings yet
- Kami Export - 13. Model EvaluationDocument25 pagesKami Export - 13. Model EvaluationYENI SRI MAHARANI -100% (1)
- 10 - T DistDocument44 pages10 - T DistPriyanka RavaniNo ratings yet
- Classification: Basic Concepts, Decision Trees, and Model EvaluationDocument46 pagesClassification: Basic Concepts, Decision Trees, and Model EvaluationAbdul AowalNo ratings yet
- Accuracy and Error MeasuresDocument46 pagesAccuracy and Error Measuresbiswanath dehuriNo ratings yet
- 9ph0 03 Ms Nov 2021 Edexcel A Level PhysicsDocument20 pages9ph0 03 Ms Nov 2021 Edexcel A Level PhysicssenseiNo ratings yet
- Statistical Analysis (T-Test)Document61 pagesStatistical Analysis (T-Test)Symoun BontigaoNo ratings yet
- w5 ClassificationDocument34 pagesw5 ClassificationSwastik SindhaniNo ratings yet
- SLG 28.2 - Procedure in Doing A Test For A MeanDocument7 pagesSLG 28.2 - Procedure in Doing A Test For A Meanrex pangetNo ratings yet
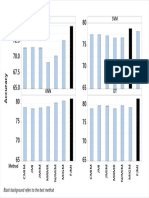
- FJMI Acc 1Document1 pageFJMI Acc 1CSSCTube FCITubeNo ratings yet
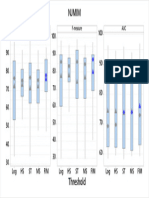
- NJMIMDocument1 pageNJMIMCSSCTube FCITubeNo ratings yet
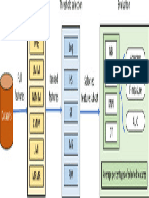
- FrameworkDocument1 pageFrameworkCSSCTube FCITubeNo ratings yet
- Bayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument17 pagesBayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarCSSCTube FCITubeNo ratings yet
- 01 IntroDocument37 pages01 IntroJyothi JyoNo ratings yet
- Analysis of Thermal BridgesDocument64 pagesAnalysis of Thermal BridgesGuillermo Durán Moro100% (2)
- Q3 Grade 8 Week 6Document15 pagesQ3 Grade 8 Week 6aniejeonNo ratings yet
- Lecture Three: Regular Expression (RE)Document2 pagesLecture Three: Regular Expression (RE)Colmain NassiriNo ratings yet
- Exponential Functions 4b PDFDocument2 pagesExponential Functions 4b PDFIrish GelNo ratings yet
- Assebly Lab PrintDocument19 pagesAssebly Lab PrintPRATIK_DARBHE100% (2)
- The Effect of Bidding Success in Construction BiddingDocument15 pagesThe Effect of Bidding Success in Construction BiddingshajbabyNo ratings yet
- Unit-2 Propositional Logic and Predicate LogicDocument15 pagesUnit-2 Propositional Logic and Predicate LogicPriyank PatelNo ratings yet
- Scarani - Quantum Physics With PolarizationDocument21 pagesScarani - Quantum Physics With Polarizationj.emmett.dwyer1033No ratings yet
- Strength of Materials Pytel and Singer Chapter 6 Solution ManualDocument179 pagesStrength of Materials Pytel and Singer Chapter 6 Solution Manualbenny narrido92% (13)
- Is 15372 2003Document11 pagesIs 15372 2003BaskarNo ratings yet
- Abstract Algebra PDFDocument102 pagesAbstract Algebra PDFalin444444100% (2)
- Tree Traversals (Inorder, Preorder and Postorder)Document16 pagesTree Traversals (Inorder, Preorder and Postorder)Ganesan SriramajayamNo ratings yet
- TrigonometryDocument32 pagesTrigonometrySriram_V100% (1)
- Introduction To Geometric Dimensioning and TolerancingDocument14 pagesIntroduction To Geometric Dimensioning and Tolerancingtushk20No ratings yet
- Crystal Structure (21!10!2011)Document71 pagesCrystal Structure (21!10!2011)Swetha PrasadNo ratings yet
- Tarski's Theory of TruthDocument10 pagesTarski's Theory of TruthHoward Mok100% (2)
- W.D .Gaan Full Study ContentDocument2 pagesW.D .Gaan Full Study ContentAabhasNo ratings yet
- Handbook of Quantitative Methods For Educational Research PDFDocument404 pagesHandbook of Quantitative Methods For Educational Research PDFOanh Nguyễn100% (1)
- Ch03 Sample Test QuestionsDocument5 pagesCh03 Sample Test QuestionsEmmanuel Peña FloresNo ratings yet
- Program 2Document11 pagesProgram 2Bhaskar DhoundiyalNo ratings yet
- Chapter 1 SupplementDocument5 pagesChapter 1 SupplementZoe MNo ratings yet
- Dynamic Stiffness and Damping of Piles Novak1974 PDFDocument25 pagesDynamic Stiffness and Damping of Piles Novak1974 PDFLucas MartinsNo ratings yet
- Chapter 7 Triangles Ex 7Document24 pagesChapter 7 Triangles Ex 7Himanshu JethwaniNo ratings yet
- OpDocument88 pagesOpMahmud Rahman BizoyNo ratings yet
- Programming Homework P1Document1 pageProgramming Homework P1mostar99994No ratings yet
- 04302522Document6 pages04302522proteccionesNo ratings yet
- Six Leg RobotDocument13 pagesSix Leg Robotramesh2184No ratings yet
- Clock ProblemsDocument2 pagesClock ProblemskennethNo ratings yet
- Soal Ujian Mat Diskrit 3Document1 pageSoal Ujian Mat Diskrit 3Media MaxNo ratings yet
- Geometric and Arithmetic Sequences NotesDocument1 pageGeometric and Arithmetic Sequences NotesDominique RussoNo ratings yet