You might also like
- Accelaration of Geared SystemDocument10 pagesAccelaration of Geared SystemLegendaryN100% (1)
- Survey On Unsupervised Learning in Datamining: S.Uma Parameswari, B.JayanthiDocument8 pagesSurvey On Unsupervised Learning in Datamining: S.Uma Parameswari, B.JayanthigeraltNo ratings yet
- Tugas 1 (Membangkitkan 500 Data) : Nama: Iswardhani Ariyanti NIM: L1B017035 Prodi: Budidaya PerairanDocument29 pagesTugas 1 (Membangkitkan 500 Data) : Nama: Iswardhani Ariyanti NIM: L1B017035 Prodi: Budidaya PerairanAriyanti ArinNo ratings yet
- Clustering Part-1Document48 pagesClustering Part-1SANJIDA AKTERNo ratings yet
- Stat 5 Measures of VariabilityDocument27 pagesStat 5 Measures of VariabilitymariellamoniquefloresNo ratings yet
- CH 4 V 2Document6 pagesCH 4 V 2oadqrwrmzkrsykmvctNo ratings yet
- Evaluation - Exercise R1Document1 pageEvaluation - Exercise R1Juliana CabreraNo ratings yet
- Starlift MetricDocument2 pagesStarlift MetricCralesNo ratings yet
- X LCB UCB FX: Mean: N2Document6 pagesX LCB UCB FX: Mean: N2Gina MayoresNo ratings yet
- SPSS - Ew AsigesDocument10 pagesSPSS - Ew AsigesBAGAS PUTRA PRATAMANo ratings yet
- The SIM2D ProcedureDocument30 pagesThe SIM2D ProceduremasterfreecssNo ratings yet
- Book 1Document4 pagesBook 1PalakNo ratings yet
- Ley de Hooke - RemovedDocument8 pagesLey de Hooke - RemovedJoelly Solis RamirezNo ratings yet
- PerhitunganDocument3 pagesPerhitunganGalang Wicaksono MuktiNo ratings yet
- Statistika ADocument3 pagesStatistika Aazzahranabila1408No ratings yet
- Crystalline Size and StrainDocument10 pagesCrystalline Size and StrainAd HasNo ratings yet
- ProperDivisors PDFDocument3 pagesProperDivisors PDFStephen BankesNo ratings yet
- Uji Analisis Statistik EksDocument1 pageUji Analisis Statistik Ekssixth sanseNo ratings yet
- Topic 8: SPC: Mean Value of First Subgroup (Document4 pagesTopic 8: SPC: Mean Value of First Subgroup (Azlie AzizNo ratings yet
- Hujan Rancangan Analitis Kala Ulang 100 TahunDocument24 pagesHujan Rancangan Analitis Kala Ulang 100 TahunArthur Aditya YohanisNo ratings yet
- Cutoff - F.Y. B.TECH (MALE) - AY - 2021Document1 pageCutoff - F.Y. B.TECH (MALE) - AY - 2021DiNo ratings yet
- Critical Behaviour of Anisotropic Spiral Self Avoiding WalksDocument5 pagesCritical Behaviour of Anisotropic Spiral Self Avoiding WalksFrontiersNo ratings yet
- University of Jordan School of Engineering Department of Mechanical Engineering Mechanical Vibrations Lab Mass-Spring SystemDocument9 pagesUniversity of Jordan School of Engineering Department of Mechanical Engineering Mechanical Vibrations Lab Mass-Spring Systemmazen ashaNo ratings yet
- Activity 5 and 6 KANADocument8 pagesActivity 5 and 6 KANAmikebascones22No ratings yet
- Soal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NDocument12 pagesSoal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NJohanAzrulFaridNo ratings yet
- Statistics AssignmentDocument7 pagesStatistics AssignmentAbdullateef AdedoyinNo ratings yet
- Soal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NDocument13 pagesSoal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NMalim Muhammad SiregarNo ratings yet
- Curah Hujan Gumbel PrintDocument3 pagesCurah Hujan Gumbel PrintDila DilaNo ratings yet
- Lampiran ValiditasDocument20 pagesLampiran ValiditasSiti Maulid dinaNo ratings yet
- Case Study On: Real FoodsDocument21 pagesCase Study On: Real Foodskkraja9No ratings yet
- StatistikDocument12 pagesStatistikNaylin Ni'mahNo ratings yet
- Stat - Tugas 3 - Wina Tika Gustiani (2009076)Document4 pagesStat - Tugas 3 - Wina Tika Gustiani (2009076)winatikaNo ratings yet
- Meam 601 Activity 5 Yamuta, Adonis Jeff E.Document3 pagesMeam 601 Activity 5 Yamuta, Adonis Jeff E.Jeff YamsNo ratings yet
- Naldo 5-230 Pa10-1Document4 pagesNaldo 5-230 Pa10-1Angel NaldoNo ratings yet
- Experiment 3 Kinematics and Kinerics of MachinesDocument8 pagesExperiment 3 Kinematics and Kinerics of Machinesuzair jahanzebNo ratings yet
- STATISTICS Part 2 (ECON 106) AssignmentDocument18 pagesSTATISTICS Part 2 (ECON 106) AssignmentAishe SarkarNo ratings yet
- Cirrus Design Section 5 SR22 Performance DataDocument23 pagesCirrus Design Section 5 SR22 Performance DataDon BachnerNo ratings yet
- Quantitative Techniques and Management Applications Assignment-1 Arnab Kumar MandalDocument7 pagesQuantitative Techniques and Management Applications Assignment-1 Arnab Kumar MandalArnab MandalNo ratings yet
- Generating A Primes Using PartitionsDocument9 pagesGenerating A Primes Using PartitionskuayakuiNo ratings yet
- X-Ray Diffraction: Lab ReportDocument16 pagesX-Ray Diffraction: Lab ReportFikan Mubarok RohimsyahNo ratings yet
- An Introduction To JPEG Compression Using Matlab: Arno Swart 28th October 2003Document5 pagesAn Introduction To JPEG Compression Using Matlab: Arno Swart 28th October 2003infiniti47No ratings yet
- Welcome To "Rte-Book1Ddeltanorm - XLS" Calculator For 1D Subaerial Fluvial Fan-Delta With Channel of Constant WidthDocument23 pagesWelcome To "Rte-Book1Ddeltanorm - XLS" Calculator For 1D Subaerial Fluvial Fan-Delta With Channel of Constant WidthsteveNo ratings yet
- 20 - 1 - ML - Unsup - 01 - Partition Based - KmeansDocument20 pages20 - 1 - ML - Unsup - 01 - Partition Based - KmeansMohitKhemkaNo ratings yet
- 1e.beam Exapnder: Equipment & Procedure EquipmentDocument2 pages1e.beam Exapnder: Equipment & Procedure EquipmentaMtrinityNo ratings yet
- Lampiran Data Uji Anova Dan Uji BNTDocument5 pagesLampiran Data Uji Anova Dan Uji BNTMuhibuddin100% (1)
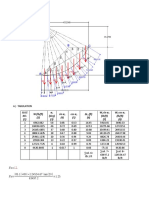
- Slice NO. (1) W (lb/ft) (2) α (deg) (3) sin α (4) cos α (5) ΔL (ft) (6) W sin α (lb/ft) (7) W cos α (lb/ft)Document1 pageSlice NO. (1) W (lb/ft) (2) α (deg) (3) sin α (4) cos α (5) ΔL (ft) (6) W sin α (lb/ft) (7) W cos α (lb/ft)Shainee Delle PalmeraNo ratings yet
- Controller Computerconstr. Engineer Promedio: Suma Total CuadradosDocument4 pagesController Computerconstr. Engineer Promedio: Suma Total Cuadradosmaria paola ramirezNo ratings yet
- Lampiran Glukosa DarahDocument4 pagesLampiran Glukosa DarahefendiNo ratings yet
- Agnes - MGT 181 - Activity 3 - Week4-5Document3 pagesAgnes - MGT 181 - Activity 3 - Week4-5JessaNo ratings yet
- Quiz Calculation SheetDocument17 pagesQuiz Calculation SheetKazueNo ratings yet
- Student Scores in EDA Quiz 1: 1) Find The Measures of Variation For The Ungrouped DataDocument7 pagesStudent Scores in EDA Quiz 1: 1) Find The Measures of Variation For The Ungrouped Datamoy balgosNo ratings yet
- StatistikDocument8 pagesStatistikJuwanda Try RahmadNo ratings yet
- Ex - No (2) : The Slider-Crank and Scotch-Yoke MechanismDocument12 pagesEx - No (2) : The Slider-Crank and Scotch-Yoke MechanismMasoud doskiNo ratings yet
- Soal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NDocument11 pagesSoal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NHabibullah HabiNo ratings yet
- Soal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NDocument11 pagesSoal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NDwiky Rahmad DarmawanNo ratings yet
- Soal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NDocument11 pagesSoal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NariNo ratings yet
- Soal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NDocument11 pagesSoal 32 Data Induk Penelitian B Data Posttest K Panjang Kelas K 1 + 3,3 Log NRamdani HidayatNo ratings yet
- Fractal - FCL Staking CalculatorDocument22 pagesFractal - FCL Staking CalculatorcoldspiritNo ratings yet
- Solution To Selected Question in Quantitative MethodDocument11 pagesSolution To Selected Question in Quantitative MethodAdekoya AdeniyiNo ratings yet
- 3.4. Sharpening Spatial FilteringDocument45 pages3.4. Sharpening Spatial FilteringSANJIDA AKTERNo ratings yet
- 3.3. Smoothing Spatial FilteringDocument60 pages3.3. Smoothing Spatial FilteringSANJIDA AKTERNo ratings yet
- 1.1. Introduction To DIPDocument61 pages1.1. Introduction To DIPSANJIDA AKTERNo ratings yet
- 8.1. Image CompressionDocument121 pages8.1. Image CompressionSANJIDA AKTERNo ratings yet
- Wordembed v2.0Document46 pagesWordembed v2.0SANJIDA AKTERNo ratings yet
- TSP Using GADocument10 pagesTSP Using GASANJIDA AKTERNo ratings yet
- RNN, LSTM, GruDocument36 pagesRNN, LSTM, GruSANJIDA AKTERNo ratings yet
- CSE 4237 SoftCom SolutionsDocument115 pagesCSE 4237 SoftCom SolutionsSANJIDA AKTERNo ratings yet
- Hyperparameters and ParametersDocument8 pagesHyperparameters and ParametersSANJIDA AKTERNo ratings yet
- OptimizerDocument2 pagesOptimizerSANJIDA AKTERNo ratings yet
- Parameter CalculationDocument10 pagesParameter CalculationSANJIDA AKTERNo ratings yet
- Introduction To Neural NetworkDocument17 pagesIntroduction To Neural NetworkSANJIDA AKTERNo ratings yet
- Lecture 1-2Document47 pagesLecture 1-2SANJIDA AKTERNo ratings yet
- Lecture 12 - Small Scale FadingDocument32 pagesLecture 12 - Small Scale FadingSANJIDA AKTERNo ratings yet
- Clustering Part-1Document48 pagesClustering Part-1SANJIDA AKTERNo ratings yet
- Lecture 5 - HandoffDocument25 pagesLecture 5 - HandoffSANJIDA AKTERNo ratings yet
- PerceptronDocument26 pagesPerceptronSANJIDA AKTERNo ratings yet
- Linear Regression & SVMDocument33 pagesLinear Regression & SVMSANJIDA AKTERNo ratings yet
- Lecture 11 - Large Scale Propagation ModelDocument20 pagesLecture 11 - Large Scale Propagation ModelSANJIDA AKTERNo ratings yet
- Lecture 7 - TrunkingDocument25 pagesLecture 7 - TrunkingSANJIDA AKTERNo ratings yet
- Lecture 5 - HandoffDocument25 pagesLecture 5 - HandoffSANJIDA AKTERNo ratings yet
- MLT NotesDocument17 pagesMLT NotessakshamNo ratings yet
- 8 - Logistic - Regression - Multiclass - Ipynb - ColaboratoryDocument6 pages8 - Logistic - Regression - Multiclass - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Intrusion Detection Using Decision Tree ApproachDocument28 pagesIntrusion Detection Using Decision Tree ApproachbhattajagdishNo ratings yet
- Syllabus - Data Mining Solution With WekaDocument5 pagesSyllabus - Data Mining Solution With WekaJaya WijayaNo ratings yet
- KRAI PracticalDocument14 pagesKRAI PracticalContact VishalNo ratings yet
- ST1 4483 8995 Capstone PPT TemplateDocument10 pagesST1 4483 8995 Capstone PPT Template360mostafasaifNo ratings yet
- Problem Sheet For Soft Computing AI and NN LabDocument6 pagesProblem Sheet For Soft Computing AI and NN Lab510618083 ABHIJNANMAITINo ratings yet
- Machine Learning TextbookDocument191 pagesMachine Learning TextbookKarthikaNo ratings yet
- Discriminant AnalysisDocument20 pagesDiscriminant AnalysisramanatenaliNo ratings yet
- Crime Prediction: Shivansh Pandey, Sahil Pratap Subodh Bansala, Shivam GoelDocument17 pagesCrime Prediction: Shivansh Pandey, Sahil Pratap Subodh Bansala, Shivam GoelShubhamMisraNo ratings yet
- AI and IoT Based Monitoring System For Increasing The Yield in Crop ProductionDocument5 pagesAI and IoT Based Monitoring System For Increasing The Yield in Crop ProductionMadhusudhan N MNo ratings yet
- Predicting Earthquakes Through Data MiningDocument10 pagesPredicting Earthquakes Through Data MiningARVIND100% (1)
- 2732 6870 2 LE Proof1Document11 pages2732 6870 2 LE Proof1NguyenVanHaiNo ratings yet
- Sentiment Analysis and Opinion Mining A SurveyDocument11 pagesSentiment Analysis and Opinion Mining A SurveyNishant JadhavNo ratings yet
- Classification of DataDocument14 pagesClassification of DataSukhman BrarNo ratings yet
- Time: 3 Hours Total Marks: 100: Printed Pages: 02 Sub Code: NCS702 Paper Id: 110714 Roll NoDocument2 pagesTime: 3 Hours Total Marks: 100: Printed Pages: 02 Sub Code: NCS702 Paper Id: 110714 Roll NoTushar GuptaNo ratings yet
- Supervised Learning Based Approach To Aspect Based Sentiment AnalysisDocument5 pagesSupervised Learning Based Approach To Aspect Based Sentiment AnalysisShamsul BasharNo ratings yet
- "Fake News" Is Not Simply False Information: A Concept Explication and Taxonomy of Online ContentDocument33 pages"Fake News" Is Not Simply False Information: A Concept Explication and Taxonomy of Online Contentفاطمة هاشم الأمينNo ratings yet
- Bhagavatula CV Jan2010Document48 pagesBhagavatula CV Jan2010Aman ChadhaNo ratings yet
- Auto InsuranceDocument19 pagesAuto InsuranceUmaNo ratings yet
- Classification of Eye Tracking Data Using A Convolutional Neural NetworkDocument6 pagesClassification of Eye Tracking Data Using A Convolutional Neural NetworkGaston VilchesNo ratings yet
- Performance Analysis of Data Mining Classification Method Using Naïve Bayes Algorithm To Predict Student Graduation TimelinessDocument4 pagesPerformance Analysis of Data Mining Classification Method Using Naïve Bayes Algorithm To Predict Student Graduation TimelinessInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Workshop Satellite Data Analysis and Machine Learning Classification With QGISDocument1 pageWorkshop Satellite Data Analysis and Machine Learning Classification With QGIShastoNo ratings yet
- Primer For Using XLminer and LightSIDE 2017 Anitesh BaruaDocument25 pagesPrimer For Using XLminer and LightSIDE 2017 Anitesh BaruagamallofNo ratings yet
- IME672 - Lecture 48Document21 pagesIME672 - Lecture 48Himanshu BeniwalNo ratings yet
- The Shape of Learning Curves: A Review: Tom Viering Marco LoogDocument46 pagesThe Shape of Learning Curves: A Review: Tom Viering Marco LoogWilder Gonzalez DiazNo ratings yet
- SVMDocument19 pagesSVMGobiNo ratings yet
- (23005319 - Acta Mechanica Et Automatica) Attribute Selection For Stroke PredictionDocument5 pages(23005319 - Acta Mechanica Et Automatica) Attribute Selection For Stroke PredictionSolomonNo ratings yet
- NeuroSolutions Infinity PDFDocument92 pagesNeuroSolutions Infinity PDFAmmarGhazaliNo ratings yet
- ML ProjectsDocument135 pagesML ProjectsSiva KumarNo ratings yet