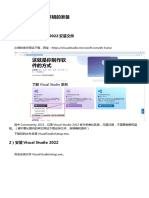
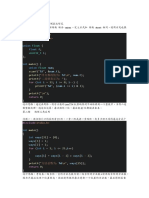
You might also like
- 船舶操縱 - 理論與實務 Ship ManeuveringDocument28 pages船舶操縱 - 理論與實務 Ship ManeuveringSTM Works50% (2)
- C程式設計語言基礎Document94 pagesC程式設計語言基礎Harry AngNo ratings yet
- 郝斌数据结构笔记Document68 pages郝斌数据结构笔记Adolph ChurchillNo ratings yet
- C语言程序设计 QfDocument147 pagesC语言程序设计 Qf王昱No ratings yet
- 11 22级程序设计 流类库与输入输出Document73 pages11 22级程序设计 流类库与输入输出lulu HanNo ratings yet
- C语言Document19 pagesC语言XHwNo ratings yet
- Cpe GuideDocument23 pagesCpe GuideWeng YanNo ratings yet
- 13Class 原始碼Document9 pages13Class 原始碼才阿No ratings yet
- 郝斌老师C语言大纲(2020年8月18日)Document43 pages郝斌老师C语言大纲(2020年8月18日)Adolph ChurchillNo ratings yet
- c語言學習Document221 pagesc語言學習tsaips81921No ratings yet
- 第8章 指针及其应用Document25 pages第8章 指针及其应用snow leeNo ratings yet
- 第1章 初识C++语言 (C++版)Document30 pages第1章 初识C++语言 (C++版)snow leeNo ratings yet
- 数据结构知识点全面总结 精华版Document29 pages数据结构知识点全面总结 精华版郑昊No ratings yet
- 第6章 函数和递归 (C++版)Document61 pages第6章 函数和递归 (C++版)snow leeNo ratings yet
- C语言程序设计2A(课次6 7结构体应用单链表)Document66 pagesC语言程序设计2A(课次6 7结构体应用单链表)Luo ZhanNo ratings yet
- Python 1Document34 pagesPython 1TONG HuangNo ratings yet
- 第一章计算机系统概论Document84 pages第一章计算机系统概论KeiraNo ratings yet
- 第01章Document26 pages第01章Chengxiang PengNo ratings yet
- 第十节课笔记Document11 pages第十节课笔记1170801585No ratings yet
- CPPDocument42 pagesCPPLin KenNo ratings yet
- 千锋 c语言之数据类型与语句Document74 pages千锋 c语言之数据类型与语句SenLNNo ratings yet
- 程序语言实验学习Document7 pages程序语言实验学习meiwanlanjunNo ratings yet
- C井 (sharp)Document138 pagesC井 (sharp)Rd WangNo ratings yet
- 施深鹏 实验三Document34 pages施深鹏 实验三shi spNo ratings yet
- 第3章 MATLAB程序设计Document48 pages第3章 MATLAB程序设计张浩象No ratings yet
- Dev C++ 01-16Document99 pagesDev C++ 01-16吳祁峰No ratings yet
- 第02章Document30 pages第02章Chengxiang PengNo ratings yet
- 《纯C论坛 电子杂志》第一期 (2006-12)Document89 pages《纯C论坛 电子杂志》第一期 (2006-12)xieyubo100% (5)
- C 基础课件和源代码(有Linux)Document595 pagesC 基础课件和源代码(有Linux)mthaiqiNo ratings yet
- 郝斌Java笔记Document113 pages郝斌Java笔记Adolph ChurchillNo ratings yet
- 施深鹏 实验4Document33 pages施深鹏 实验4shi spNo ratings yet
- 第03章Document30 pages第03章Chengxiang PengNo ratings yet
- 第2章 线性表Document90 pages第2章 线性表Faizul Haque NiloyNo ratings yet
- 第九届蓝桥杯大赛竞赛大纲(软件类)Document15 pages第九届蓝桥杯大赛竞赛大纲(软件类)vmmmzhuanyongNo ratings yet
- 1.array 定义在 中: C++ STL 序列式容器Document18 pages1.array 定义在 中: C++ STL 序列式容器ekkopolarisNo ratings yet
- 第1章 Python语言基础Document77 pages第1章 Python语言基础俞路平No ratings yet
- Python课程配套完整版笔记Document228 pagesPython课程配套完整版笔记Lei QiNo ratings yet
- Python培训预备内容Document63 pagesPython培训预备内容geyunboNo ratings yet
- 第一次课(Python基本知识讲解)Document11 pages第一次课(Python基本知识讲解)braints481No ratings yet
- ML Ch02Document111 pagesML Ch02GodYanNo ratings yet
- 华为测试面试题目 (有答案)Document42 pages华为测试面试题目 (有答案)yue liuNo ratings yet
- 实验0 c语言实验Document2 pages实验0 c语言实验Changqing LinNo ratings yet
- 09 22级程序设计 模板和群体数据Document122 pages09 22级程序设计 模板和群体数据lulu HanNo ratings yet
- (New) c 模板元编程实战:一个深度学习框架的初步实现Document246 pages(New) c 模板元编程实战:一个深度学习框架的初步实现bjfx88521No ratings yet
- 数据结构复习要点 (整理版)Document13 pages数据结构复习要点 (整理版)郑昊No ratings yet
- Hcm 编译原理 第11讲 语法制导翻译 20221010Document79 pagesHcm 编译原理 第11讲 语法制导翻译 20221010qiaoaikuNo ratings yet
- CTF编码课件Document72 pagesCTF编码课件Yue PanNo ratings yet
- CDocument120 pagesCapi-3758631No ratings yet
- 第5章 数组 (C++版)Document100 pages第5章 数组 (C++版)snow leeNo ratings yet
- 实习笔记 2017112101 陈博文Document14 pages实习笔记 2017112101 陈博文BoneChenNo ratings yet
- Day04【Idea、方法】Document25 pagesDay04【Idea、方法】季南城No ratings yet
- JavaDocument511 pagesJavaFrank LeiNo ratings yet
- c01-chap0-1-程序设计引言quickIntro-sy - 副本Document71 pagesc01-chap0-1-程序设计引言quickIntro-sy - 副本曾育群No ratings yet
- C语言习题解答和上机指导 人民邮电出版社 黄昌伟 彭正文 主编 13052844Document128 pagesC语言习题解答和上机指导 人民邮电出版社 黄昌伟 彭正文 主编 13052844poorkids pkNo ratings yet
- 1 Python基础课件Document53 pages1 Python基础课件brianNo ratings yet
- 千锋 c语言之数组Document6 pages千锋 c语言之数组SenLNNo ratings yet
- abaqus inp教程Document15 pagesabaqus inp教程Feng LinNo ratings yet
- 7Document27 pages7PonyNo ratings yet
- 第五章Document69 pages第五章snow leeNo ratings yet
- Mag 202916Document8 pagesMag 202916snow leeNo ratings yet
- 初赛答案Document3 pages初赛答案snow leeNo ratings yet
- 复赛试题Document2 pages复赛试题snow leeNo ratings yet
- 第8章 指针及其应用Document25 pages第8章 指针及其应用snow leeNo ratings yet
- 【BT教育】2024年《五色框架-战略》-关注公众号【李彬教你考注会 】Document74 pages【BT教育】2024年《五色框架-战略》-关注公众号【李彬教你考注会 】snow leeNo ratings yet
- 第8章 C++实用技巧与模版库Document50 pages第8章 C++实用技巧与模版库snow leeNo ratings yet
- 初赛答案Document2 pages初赛答案snow leeNo ratings yet
- 第5章 数组 (C++版)Document100 pages第5章 数组 (C++版)snow leeNo ratings yet
- 13一等奖冲刺 贪心法 主讲:杜瑜皓Document88 pages13一等奖冲刺 贪心法 主讲:杜瑜皓snow leeNo ratings yet
- 第4章 循环结构 (C++版)Document90 pages第4章 循环结构 (C++版)snow leeNo ratings yet
- 第3章 选择结构 (C++版)Document54 pages第3章 选择结构 (C++版)snow leeNo ratings yet
- 第6章 函数和递归 (C++版)Document61 pages第6章 函数和递归 (C++版)snow leeNo ratings yet
- 第2章 简单程序设计 (C++版)Document97 pages第2章 简单程序设计 (C++版)snow leeNo ratings yet
- 第4章 第3-4节 图论算法 (C++版)Document45 pages第4章 第3-4节 图论算法 (C++版)snow leeNo ratings yet
- 第4章 第1-2节 图论算法 (C++版)Document20 pages第4章 第1-2节 图论算法 (C++版)snow leeNo ratings yet
- 第5章 搜索与回溯算法 (C++版)Document48 pages第5章 搜索与回溯算法 (C++版)snow leeNo ratings yet
- 第3章 第3节 堆及其应用 (C++版)Document56 pages第3章 第3节 堆及其应用 (C++版)snow leeNo ratings yet
- 12一等奖冲刺 数据结构 主讲:吉如一 (加微信youbaoaixuexi)Document88 pages12一等奖冲刺 数据结构 主讲:吉如一 (加微信youbaoaixuexi)snow leeNo ratings yet
- 台湾人四百年史Document1,584 pages台湾人四百年史snow leeNo ratings yet
- 第3章 第1-2节 树及二叉树 (C++版)Document72 pages第3章 第1-2节 树及二叉树 (C++版)snow leeNo ratings yet
- 第2章 队列 (C++版)Document20 pages第2章 队列 (C++版)snow leeNo ratings yet
- 第7章 分治算法 (C++版)Document27 pages第7章 分治算法 (C++版)snow leeNo ratings yet
- 15一等奖冲刺 树与图 主讲:吉如一Document111 pages15一等奖冲刺 树与图 主讲:吉如一snow leeNo ratings yet
- 深圳企业变更材料搜索指引Document3 pages深圳企业变更材料搜索指引snow leeNo ratings yet
- 求己斋回忆录Document132 pages求己斋回忆录snow leeNo ratings yet
- 豐臣秀吉侵略朝鮮:日、朝、明三國軍中之疾疫、情蒐與通訊Document42 pages豐臣秀吉侵略朝鮮:日、朝、明三國軍中之疾疫、情蒐與通訊snow leeNo ratings yet
- 马克思 印度史编年稿Document227 pages马克思 印度史编年稿snow leeNo ratings yet
- 突厥汗国与隋唐关系史研究 (吴玉贵)Document476 pages突厥汗国与隋唐关系史研究 (吴玉贵)snow leeNo ratings yet
- 蒋经国传(江南)Document515 pages蒋经国传(江南)snow leeNo ratings yet
- 資工系學群CDocument12 pages資工系學群CDanielNo ratings yet
- 矩阵理论知识点总结Document158 pages矩阵理论知识点总结Gori LLLlaNo ratings yet
- UntitledDocument6 pagesUntitled九禮48蕭鈺永MichaelNo ratings yet
- ItcDocument3 pagesItcapi-3722545No ratings yet
- 2025 HkdseDocument5 pages2025 HkdseWeiNo ratings yet