You might also like
- Module Four, Part Three: Sample Selection in Economic Education Research Using StataDocument24 pagesModule Four, Part Three: Sample Selection in Economic Education Research Using Stataabraham admassieNo ratings yet
- Aea Cookbook Econometrics Module 4Document80 pagesAea Cookbook Econometrics Module 4shadayenpNo ratings yet
- fitriantoAMS125 128 2014Document8 pagesfitriantoAMS125 128 2014Yeni RahkmawatiNo ratings yet
- Makalah Matematika EkonomiDocument11 pagesMakalah Matematika Ekonomimeidy adelinaNo ratings yet
- Regression Explained SPSSDocument23 pagesRegression Explained SPSSAngel Sanu100% (1)
- Applied Economics Project OptionDocument5 pagesApplied Economics Project OptionCarlos NoyolaNo ratings yet
- Econometrics II Distance ModuleDocument97 pagesEconometrics II Distance ModuleBereket DesalegnNo ratings yet
- Ac 2012-3733: An Online Engineering Statics Problem Set SystemDocument9 pagesAc 2012-3733: An Online Engineering Statics Problem Set SystemJKF TestNo ratings yet
- Growing Growing Growing Unit PlanDocument22 pagesGrowing Growing Growing Unit Planapi-250461623100% (1)
- ProblemSet1 CorrectionDocument7 pagesProblemSet1 CorrectionMarcelo MirandaNo ratings yet
- Ballard JohnsonDocument37 pagesBallard JohnsonMirja DjokovicNo ratings yet
- PISA2018 - Technical Report Chapter 16 Background QuestionnairesDocument42 pagesPISA2018 - Technical Report Chapter 16 Background QuestionnairesJORGE GARCIA GARCIANo ratings yet
- GretlDocument83 pagesGretlKanat ÇırpNo ratings yet
- G4-M2-A Newsletter FinalDocument2 pagesG4-M2-A Newsletter Finalapi-328647093No ratings yet
- Ebook - Econometrics Handbook PDFDocument317 pagesEbook - Econometrics Handbook PDFDebapriya SamalNo ratings yet
- How To Learn COMSOLDocument16 pagesHow To Learn COMSOLShivang SharmaNo ratings yet
- Farhad Salih Ahmed (Esam)Document8 pagesFarhad Salih Ahmed (Esam)bawanlavaNo ratings yet
- CGE Classroom ExcelDocument39 pagesCGE Classroom ExcelPaf Veterans-FamiliesNo ratings yet
- Cstrtqmath 2Document57 pagesCstrtqmath 2IHSteacherNo ratings yet
- First Project Final ReportDocument9 pagesFirst Project Final ReportFrancisco PinhoNo ratings yet
- Aea Cookbook Econometrics Module 1Document117 pagesAea Cookbook Econometrics Module 1shadayenpNo ratings yet
- Release Questions CSTDocument27 pagesRelease Questions CSTapi-133916648No ratings yet
- 6349 19351 1 PBDocument12 pages6349 19351 1 PBJohannes Marc OtaydeNo ratings yet
- Algebra 2 - CaliDocument27 pagesAlgebra 2 - Caliapi-228595495No ratings yet
- Branches of Statistics, Data Types, and GraphsDocument6 pagesBranches of Statistics, Data Types, and Graphsmusicoustic1No ratings yet
- SolutuionDocument14 pagesSolutuionMehmet Ekin0% (1)
- C DEA: Ategorical Variables inDocument18 pagesC DEA: Ategorical Variables indiego_coqueroNo ratings yet
- Example Metrics - Final Assignment - WS1920 - SHDocument9 pagesExample Metrics - Final Assignment - WS1920 - SHNinò GogsaNo ratings yet
- TMFSJ Grade 7 Unit Rates Unit PlanDocument13 pagesTMFSJ Grade 7 Unit Rates Unit Planapi-351865218No ratings yet
- Edps 652 Test Review of Keymath 3 (Melissa Martin)Document17 pagesEdps 652 Test Review of Keymath 3 (Melissa Martin)api-290174387No ratings yet
- American Economic Association The American Economic ReviewDocument5 pagesAmerican Economic Association The American Economic ReviewMariamNo ratings yet
- The Effect of Hands On EquationsDocument31 pagesThe Effect of Hands On EquationsDiegoNo ratings yet
- Journal of Statistical Software: Multilevel IRT Modeling in Practice With The Package MlirtDocument16 pagesJournal of Statistical Software: Multilevel IRT Modeling in Practice With The Package MlirtabougaliaNo ratings yet
- Introduction and The Simple Linear Regression ModelDocument35 pagesIntroduction and The Simple Linear Regression ModelNazmul H. PalashNo ratings yet
- 2007 03 Multilevel ModellingDocument55 pages2007 03 Multilevel Modellingmahi52No ratings yet
- Practical - 8: Demonstration of Correlation and Regression Functions in ExcelDocument7 pagesPractical - 8: Demonstration of Correlation and Regression Functions in ExcelAbhiramNo ratings yet
- Multiple Regression Part 2Document7 pagesMultiple Regression Part 2kinhai_seeNo ratings yet
- Pisa Maths 1Document56 pagesPisa Maths 1innoformatifNo ratings yet
- Elements of Econometrics Exam CommentariesDocument4 pagesElements of Econometrics Exam CommentariesAlex Absalamov0% (1)
- Basic Excel MCMCDocument20 pagesBasic Excel MCMCaqp_peruNo ratings yet
- ps4 Fall2015Document8 pagesps4 Fall2015LuisSanchezNo ratings yet
- ECO308 - Week 1 - Lecture - NoteDocument8 pagesECO308 - Week 1 - Lecture - NoteAyinde Taofeeq OlusolaNo ratings yet
- Intermediate Microeconomics Calculus Module: RD THDocument5 pagesIntermediate Microeconomics Calculus Module: RD THCharlotteNo ratings yet
- Intermediate Microeconomics Calculus Module: RD THDocument5 pagesIntermediate Microeconomics Calculus Module: RD THCharlotteNo ratings yet
- Complete Template (Quanti)Document9 pagesComplete Template (Quanti)Erika ValderamaNo ratings yet
- Statistics of Management - Set - 1Document17 pagesStatistics of Management - Set - 1Asha JyothiNo ratings yet
- PISA Sample MathsDocument96 pagesPISA Sample MathsAditya SenthilNo ratings yet
- MODULE 1 Analyzing DistributionsDocument13 pagesMODULE 1 Analyzing Distributionsignaciopauldaniel19No ratings yet
- Matsudaira 2008Document22 pagesMatsudaira 2008Tuyến Võ ThịNo ratings yet
- BSC Mathematics Major With Finance Minor at Leeds University - Course DescriptionDocument6 pagesBSC Mathematics Major With Finance Minor at Leeds University - Course DescriptionVytautas KazlauskasNo ratings yet
- American Statistical AssociationDocument5 pagesAmerican Statistical AssociationshahriarsadighiNo ratings yet
- ASA University Bangladesh: Socio Economic Condition of ASAUB's StudentDocument17 pagesASA University Bangladesh: Socio Economic Condition of ASAUB's Studenttitas31No ratings yet
- International Journals Call For Paper HTTP://WWW - Iiste.org/journalsDocument12 pagesInternational Journals Call For Paper HTTP://WWW - Iiste.org/journalsAlexander DeckerNo ratings yet
- Bayesian Factor Analysis For Mixed Ordinal and Continuous ResponsesDocument16 pagesBayesian Factor Analysis For Mixed Ordinal and Continuous ResponseschrisNo ratings yet
- Exploring Radioactive Decay in ExcelDocument7 pagesExploring Radioactive Decay in ExcelBiancaMihalache100% (1)
- Decision - Table Based TestingDocument4 pagesDecision - Table Based TestingEditor IJRITCCNo ratings yet
- Dynamic Optimization, Second Edition: The Calculus of Variations and Optimal Control in Economics and ManagementFrom EverandDynamic Optimization, Second Edition: The Calculus of Variations and Optimal Control in Economics and ManagementRating: 3 out of 5 stars3/5 (3)
- Oxygen Cycle: PlantsDocument3 pagesOxygen Cycle: PlantsApam BenjaminNo ratings yet
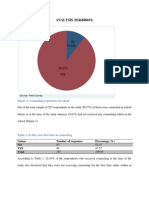
- ANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolDocument8 pagesANALYSIS (0246888691) : Figure 1: Counseling Experience in SchoolApam BenjaminNo ratings yet
- Lecture6 Module2 Anova 1Document10 pagesLecture6 Module2 Anova 1Apam BenjaminNo ratings yet
- Lecture8 Module2 Anova 1Document13 pagesLecture8 Module2 Anova 1Apam BenjaminNo ratings yet
- Multivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Document8 pagesMultivariate Analysis of Variance (MANOVA) : (Copy This Section To Methodology)Apam BenjaminNo ratings yet
- Cocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenDocument12 pagesCocoa (Theobroma Cacao L.) : Theobroma Cacao Also Cacao Tree and Cocoa Tree, Is A Small (4-8 M or 15-26 FT Tall) EvergreenApam BenjaminNo ratings yet
- Research ProposalDocument6 pagesResearch ProposalApam BenjaminNo ratings yet
- Nitrogen Cycle: Ecological FunctionDocument8 pagesNitrogen Cycle: Ecological FunctionApam BenjaminNo ratings yet
- Lecture7 Module2 Anova 1Document10 pagesLecture7 Module2 Anova 1Apam BenjaminNo ratings yet
- PLM IiDocument3 pagesPLM IiApam BenjaminNo ratings yet
- Lecture4 Module2 Anova 1Document9 pagesLecture4 Module2 Anova 1Apam BenjaminNo ratings yet
- ARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaDocument9 pagesARIMA (Autoregressive Integrated Moving Average) Approach To Predicting Inflation in GhanaApam BenjaminNo ratings yet
- Lecture5 Module2 Anova 1Document9 pagesLecture5 Module2 Anova 1Apam BenjaminNo ratings yet
- PLMDocument5 pagesPLMApam BenjaminNo ratings yet
- Finish WorkDocument116 pagesFinish WorkApam BenjaminNo ratings yet
- Hosmer On Survival With StataDocument21 pagesHosmer On Survival With StataApam BenjaminNo ratings yet
- Personal Information: Curriculum VitaeDocument6 pagesPersonal Information: Curriculum VitaeApam BenjaminNo ratings yet
- Regression Analysis of Road Traffic Accidents and Population Growth in GhanaDocument7 pagesRegression Analysis of Road Traffic Accidents and Population Growth in GhanaApam BenjaminNo ratings yet
- Banque AtlanticbanDocument1 pageBanque AtlanticbanApam BenjaminNo ratings yet
- A Study On School DropoutsDocument6 pagesA Study On School DropoutsApam BenjaminNo ratings yet
- How Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsDocument14 pagesHow Does Information Technology Impact On Business Relationships? The Need For Personal MeetingsApam BenjaminNo ratings yet
- Ajsms 2 4 348 355Document8 pagesAjsms 2 4 348 355Akolgo PaulinaNo ratings yet
- Trial Questions (PLM)Document3 pagesTrial Questions (PLM)Apam BenjaminNo ratings yet
- How To Write A Paper For A Scientific JournalDocument10 pagesHow To Write A Paper For A Scientific JournalApam BenjaminNo ratings yet
- l.4. Research QuestionsDocument1 pagel.4. Research QuestionsApam BenjaminNo ratings yet
- Asri Stata 2013-FlyerDocument1 pageAsri Stata 2013-FlyerAkolgo PaulinaNo ratings yet
- Creating STATA DatasetsDocument4 pagesCreating STATA DatasetsApam BenjaminNo ratings yet
- 6th Central Pay Commission Salary CalculatorDocument15 pages6th Central Pay Commission Salary Calculatorrakhonde100% (436)
- Project ReportsDocument31 pagesProject ReportsBilal AliNo ratings yet
- MSC Project Study Guide Jessica Chen-Burger: What You Will WriteDocument1 pageMSC Project Study Guide Jessica Chen-Burger: What You Will WriteApam BenjaminNo ratings yet