You might also like
- Chapter 9Document13 pagesChapter 9Mao Han100% (2)
- Process Design AssignmentDocument2 pagesProcess Design Assignmentcarlme012132100% (5)
- R12 Extend Oracle Applications Customizing OA Framework Applications Ed1 Student Guide - Volume 1 PDFDocument494 pagesR12 Extend Oracle Applications Customizing OA Framework Applications Ed1 Student Guide - Volume 1 PDFmariocelisNo ratings yet
- Chapter 3 - Introduction To Optimization Modeling: Answer: CDocument6 pagesChapter 3 - Introduction To Optimization Modeling: Answer: CRashaNo ratings yet
- Lutron Controls CatalogDocument72 pagesLutron Controls CatalogAcxel D. CastilloNo ratings yet
- Assignment 2Document5 pagesAssignment 2Rohith DuvasiNo ratings yet
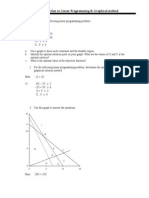
- 33707graphical MethodDocument4 pages33707graphical MethodMehak KalraNo ratings yet
- Matlec 9Document4 pagesMatlec 9darancibNo ratings yet
- 07 Exam1 SolutionDocument9 pages07 Exam1 SolutionChemical Engineering100% (1)
- Transportation AssignmentDocument28 pagesTransportation AssignmentMaaz KaziNo ratings yet
- MS&E 111 Lab Exam, ENGR 62, StanfordDocument5 pagesMS&E 111 Lab Exam, ENGR 62, StanfordsuudsfiinNo ratings yet
- Listado de Juegos Nintendo Switch y Links de Descargas PDFDocument21 pagesListado de Juegos Nintendo Switch y Links de Descargas PDFErnestoNo ratings yet
- Group - 9 - Sec - B - IQDM - Merton - Truck - CompanyDocument8 pagesGroup - 9 - Sec - B - IQDM - Merton - Truck - CompanyMANVENDRA SINGH PGP 2019-21 BatchNo ratings yet
- Lesson Special Cases in Transportation ProblemsDocument8 pagesLesson Special Cases in Transportation ProblemsDebjeet BhowmikNo ratings yet
- Ch8 LPDocument17 pagesCh8 LPYusuf HusseinNo ratings yet
- Chapra 15Document3 pagesChapra 15Patrick M JaneNo ratings yet
- Energy Economics (Peter M. Schwarz) (Z-Lib - Org) - Pages-69-75Document7 pagesEnergy Economics (Peter M. Schwarz) (Z-Lib - Org) - Pages-69-75ilia movasatianNo ratings yet
- Wind Screen WipersDocument7 pagesWind Screen Wiperszac18992No ratings yet
- LP Introduction and Graphical Method-2021Document36 pagesLP Introduction and Graphical Method-2021Shrinidhi HariharasuthanNo ratings yet
- Optimization MethodsDocument62 pagesOptimization MethodsDiego Isla-LópezNo ratings yet
- Economics of Strategy (ECON 4550) - Maymester 2014 "Linear Programming"Document26 pagesEconomics of Strategy (ECON 4550) - Maymester 2014 "Linear Programming"Subrata BagchiNo ratings yet
- Lagrange - Economy ExercisesDocument2 pagesLagrange - Economy ExercisesEduardo Lugo DiazNo ratings yet
- Transportation Assignment 3Document28 pagesTransportation Assignment 3Kenneth RonoNo ratings yet
- Bertossi 1987Document11 pagesBertossi 1987Benjamin NaulaNo ratings yet
- MB0048 - Answer-Set2 - Operations ResearchDocument15 pagesMB0048 - Answer-Set2 - Operations ResearchBoban JayanNo ratings yet
- MATH 1003 Calculus and Linear Algebra (Lecture 8) : Albert KuDocument22 pagesMATH 1003 Calculus and Linear Algebra (Lecture 8) : Albert KuMFong ThongNo ratings yet
- Model Solutions For Homework Assignment 1 CS798: 1 NoteDocument7 pagesModel Solutions For Homework Assignment 1 CS798: 1 NoteAbhishek ParmarNo ratings yet
- Mathematics For Economics 2marksDocument4 pagesMathematics For Economics 2marksjacqulineinbarajNo ratings yet
- A Branch-and-Cut-and-Price Algorithm For A Fingerprint-Template Compression ApplicationDocument8 pagesA Branch-and-Cut-and-Price Algorithm For A Fingerprint-Template Compression ApplicationDiego RuedaNo ratings yet
- Adjustable Robust Counterpart OptimDocument12 pagesAdjustable Robust Counterpart Optimvladimir_559023867No ratings yet
- Vanessa-Linear ProgrammingDocument13 pagesVanessa-Linear ProgrammingVanessa PallarNo ratings yet
- Ansys TopoptDocument10 pagesAnsys TopoptnetkasiaNo ratings yet
- Ex1 RegressionDocument6 pagesEx1 RegressionNikitasNo ratings yet
- HW 3Document4 pagesHW 3Hassan GDOURANo ratings yet
- Modelling Network Constrained Economic Dispatch ProblemsDocument6 pagesModelling Network Constrained Economic Dispatch ProblemsNguyễn HồngNo ratings yet
- Bmath 2 PDFDocument8 pagesBmath 2 PDFRobert Jayson UyNo ratings yet
- Optimization of Wet Multi-Disk Clutch Based On Improved Genetic AlgorithmDocument4 pagesOptimization of Wet Multi-Disk Clutch Based On Improved Genetic AlgorithmkazdanoNo ratings yet
- ACC 307 - Note To ClassDocument5 pagesACC 307 - Note To Classjimoh kamiludeenNo ratings yet
- Multi-Objective Optimization of Automotive Front Rail Based On Surrogate Model and NSGA-IIDocument10 pagesMulti-Objective Optimization of Automotive Front Rail Based On Surrogate Model and NSGA-IIhaceneNo ratings yet
- Sample Final Examination Questions IE406 - Introduction To Mathematical Programming Dr. RalphsDocument10 pagesSample Final Examination Questions IE406 - Introduction To Mathematical Programming Dr. RalphsLuis IvanNo ratings yet
- Applied Topology OptimizationDocument1 pageApplied Topology OptimizationRohit GadekarNo ratings yet
- Application of Linear Programming-1Document19 pagesApplication of Linear Programming-1Abdul SattarNo ratings yet
- Carga de Bolas - Molino KopperDocument4 pagesCarga de Bolas - Molino KopperIngridkfer100% (1)
- sn1 BDocument8 pagessn1 BJose Aris SholehuddinNo ratings yet
- M02 Helb5053 01 Se C02Document30 pagesM02 Helb5053 01 Se C02Abid Siddiq MurtazaiNo ratings yet
- Re-Exam Solutions v2Document4 pagesRe-Exam Solutions v2Anushree JainNo ratings yet
- CH 04Document21 pagesCH 04amanraaj100% (1)
- IOR Assignment 1Document3 pagesIOR Assignment 1jenny henlynNo ratings yet
- 2001-Problemas Capítulo 1, Edgar, Himmelblau, LasdonDocument9 pages2001-Problemas Capítulo 1, Edgar, Himmelblau, LasdonItzel NavaNo ratings yet
- Ch8 LPDocument17 pagesCh8 LPparavpNo ratings yet
- Linear ProgrammingDocument17 pagesLinear ProgrammingAdeola DamilolaNo ratings yet
- 12 Linear ProgrammingDocument12 pages12 Linear ProgrammingHarsh Ravi0% (2)
- Problem FormulationDocument5 pagesProblem FormulationSudeesh SudevanNo ratings yet
- MB0048 (3) - 1 Operation ResearchDocument13 pagesMB0048 (3) - 1 Operation ResearchRaushan RatneshNo ratings yet
- Mini Projet en AnglaisDocument17 pagesMini Projet en AnglaisHammoutene MohamedNo ratings yet
- MSD Tutorial 1 ArialDocument3 pagesMSD Tutorial 1 Arialaaroncete14No ratings yet
- Linear Programming For OptimizationDocument9 pagesLinear Programming For Optimizationاحمد محمد ساهيNo ratings yet
- Transportation Problem A Special Case For Linear Programming Problems PDFDocument36 pagesTransportation Problem A Special Case For Linear Programming Problems PDFCaz Tee-NahNo ratings yet
- Advanced Opensees Algorithms, Volume 1: Probability Analysis Of High Pier Cable-Stayed Bridge Under Multiple-Support Excitations, And LiquefactionFrom EverandAdvanced Opensees Algorithms, Volume 1: Probability Analysis Of High Pier Cable-Stayed Bridge Under Multiple-Support Excitations, And LiquefactionNo ratings yet
- Mission: Gravity: Results From Timing A Falling RockDocument2 pagesMission: Gravity: Results From Timing A Falling RocksuudsfiinNo ratings yet
- How To Keep A Lab BookDocument1 pageHow To Keep A Lab BooksuudsfiinNo ratings yet
- Week+2+Pre LabDocument1 pageWeek+2+Pre LabsuudsfiinNo ratings yet
- Lab Book CheckDocument1 pageLab Book ChecksuudsfiinNo ratings yet
- Lab Report Mission GravityDocument5 pagesLab Report Mission GravitysuudsfiinNo ratings yet
- Mission: Delivery: "Measure What Is Measurable, and Make Measurable What Is Not So."Document1 pageMission: Delivery: "Measure What Is Measurable, and Make Measurable What Is Not So."suudsfiinNo ratings yet
- Technology and SocietyDocument1 pageTechnology and SocietysuudsfiinNo ratings yet
- Bibliography For Untitled at 10-28-13, 05-12PMDocument2 pagesBibliography For Untitled at 10-28-13, 05-12PMsuudsfiinNo ratings yet
- fypANG, ENGR 62, StanfordDocument35 pagesfypANG, ENGR 62, StanfordsuudsfiinNo ratings yet
- Shortest, ENGR 62, StanfordDocument3 pagesShortest, ENGR 62, StanfordsuudsfiinNo ratings yet
- Rev2, ENGR 62, StanfordDocument40 pagesRev2, ENGR 62, StanfordsuudsfiinNo ratings yet
- Technology and SocietyDocument1 pageTechnology and SocietysuudsfiinNo ratings yet
- Technology and SocietyDocument1 pageTechnology and SocietysuudsfiinNo ratings yet
- ps1, ENGR 62, StanfordDocument3 pagesps1, ENGR 62, StanfordsuudsfiinNo ratings yet
- ps2, ENGR 62, StanfordDocument3 pagesps2, ENGR 62, StanfordsuudsfiinNo ratings yet
- Practice Midterm, ENGR 62, StanfordDocument2 pagesPractice Midterm, ENGR 62, StanfordsuudsfiinNo ratings yet
- LCS, ENGR 62, StanfordDocument1 pageLCS, ENGR 62, StanfordsuudsfiinNo ratings yet
- Matching BFS, ENGR 62, StanfordDocument1 pageMatching BFS, ENGR 62, StanfordsuudsfiinNo ratings yet
- Finger Print RecognitionDocument56 pagesFinger Print RecognitionOmar MahmoodNo ratings yet
- Configuring 4500X Cisco Virtual Switch SystemDocument5 pagesConfiguring 4500X Cisco Virtual Switch SystemLucas ZuluagaNo ratings yet
- Automatic TransmissionDocument426 pagesAutomatic Transmissionjesus quevedoNo ratings yet
- In-Machine Measuring System 2 Operation ManualDocument47 pagesIn-Machine Measuring System 2 Operation ManualLeadec LumelNo ratings yet
- Techno Economic Access of TechnologyDocument10 pagesTechno Economic Access of TechnologyDr. Ir. R. Didin Kusdian, MT.No ratings yet
- Manual de RouterDocument32 pagesManual de RouterRhoteram Vikku100% (1)
- 0 - Using Machine Learning To Solve Ordinary Differential EquationsDocument14 pages0 - Using Machine Learning To Solve Ordinary Differential EquationsAyush jhaNo ratings yet
- Trajectory Planning: Robotics 1Document30 pagesTrajectory Planning: Robotics 1KOTIKA SOMA RAJUNo ratings yet
- Rumah TanggaDocument38 pagesRumah Tanggasandi pranataNo ratings yet
- As 2645-1987 Information Processing - Documentation Symbols and Conventions For Data Program and System FlowcDocument7 pagesAs 2645-1987 Information Processing - Documentation Symbols and Conventions For Data Program and System FlowcSAI Global - APACNo ratings yet
- Freshers Job Interview Questions and Answers How Should Fresh Graduates PracticeDocument2 pagesFreshers Job Interview Questions and Answers How Should Fresh Graduates Practicechelsea@stamfordbridgeNo ratings yet
- HW1Document3 pagesHW1nakuteliduNo ratings yet
- SRM Company Profile (Autosaved) PDFDocument13 pagesSRM Company Profile (Autosaved) PDFAbhishek SinghNo ratings yet
- CiscoLive 2020 Barcelona - Advanced IPv6 Routing and Services LabDocument157 pagesCiscoLive 2020 Barcelona - Advanced IPv6 Routing and Services LabJeff JeffsonNo ratings yet
- On Stopwords, Filtering and Data Sparsity For Sentiment Analysis of TwitterDocument8 pagesOn Stopwords, Filtering and Data Sparsity For Sentiment Analysis of TwitterSun TheNo ratings yet
- MPC2550 SMDocument1,169 pagesMPC2550 SMCristian TempyNo ratings yet
- SIGMA CatalogueDocument8 pagesSIGMA CataloguekylegazeNo ratings yet
- Metode Penelitan Chapter 4Document31 pagesMetode Penelitan Chapter 4Michael HarisNo ratings yet
- Android XML Layouts - A Study of Viewgroups and Views For UI Design in Android ApplicationDocument17 pagesAndroid XML Layouts - A Study of Viewgroups and Views For UI Design in Android ApplicationNajmi khan KhanNo ratings yet
- 18 - ERP and SCM Systems IntegrationDocument22 pages18 - ERP and SCM Systems IntegrationAdarsh KambojNo ratings yet
- QTP - Vbscript Interview Questions and Answers: Length of The StringDocument6 pagesQTP - Vbscript Interview Questions and Answers: Length of The StringPraveen KumarNo ratings yet
- Pantsandjacketslp OBENADocument6 pagesPantsandjacketslp OBENAPrayer ObenaNo ratings yet
- Project On BoatDocument26 pagesProject On Boatsagar.s0962No ratings yet
- Java Persistence API Jpa ExamDocument30 pagesJava Persistence API Jpa ExamwillycruiseNo ratings yet
- Lan-Based Library Management System of Cavite Bible Baptist Institution SchoolDocument6 pagesLan-Based Library Management System of Cavite Bible Baptist Institution SchoolKhim AlcoyNo ratings yet
- Hostel Management SystemDocument18 pagesHostel Management SystemNamrita Sundarraj50% (6)
- Compare Two CSV Files and Append Value Using AwkDocument6 pagesCompare Two CSV Files and Append Value Using AwkSamir BenakliNo ratings yet