You might also like
- Voices in Harmony ProgramDocument4 pagesVoices in Harmony ProgramagnesmalkNo ratings yet
- Data Mining Project Shivani PandeyDocument40 pagesData Mining Project Shivani PandeyShivich10100% (1)
- Aquatic EcosystemsDocument16 pagesAquatic Ecosystemsapi-323141584No ratings yet
- Predictive Modeling Business Report.Document31 pagesPredictive Modeling Business Report.Paras K100% (1)
- Problem 2 - Survey: Importing Nessceary LibrariesDocument10 pagesProblem 2 - Survey: Importing Nessceary LibrariesBhagyaSree JNo ratings yet
- Cluster AnalysisDocument38 pagesCluster AnalysisShiva KumarNo ratings yet
- Shatter City by Scott Westerfeld ExtractDocument29 pagesShatter City by Scott Westerfeld ExtractAllen & Unwin44% (18)
- ShipCraft 1 - German Pocket Battleships PDFDocument35 pagesShipCraft 1 - German Pocket Battleships PDFthingus50% (2)
- Customer Churn Prediction in Telecom Industry: Sourav Sarkar (Group 7)Document30 pagesCustomer Churn Prediction in Telecom Industry: Sourav Sarkar (Group 7)prince2venkat100% (1)
- Cluster Training PDF (Compatibility Mode)Document21 pagesCluster Training PDF (Compatibility Mode)Sarbani DasguptsNo ratings yet
- Mathworksheets4 22Document9 pagesMathworksheets4 22api-233717707No ratings yet
- Exploratory Data Analysis Stephan Morgenthaler (2009)Document12 pagesExploratory Data Analysis Stephan Morgenthaler (2009)s8nd11d UNI100% (2)
- Data Preprocessing - Data CleaningDocument29 pagesData Preprocessing - Data CleaningtierSarge100% (1)
- Explorotary Data AnalysisDocument30 pagesExplorotary Data AnalysisSanjaya Kumar KhadangaNo ratings yet
- Research StudyDocument30 pagesResearch StudyCherish Nymph Maniquez CelestinoNo ratings yet
- Data MiningDocument53 pagesData MiningMysti QueNo ratings yet
- Data Visualisation With TableauDocument26 pagesData Visualisation With TableauVaibhav BhatnagarNo ratings yet
- The Agikuyu Concept of God and Understanding of The Triune GodDocument8 pagesThe Agikuyu Concept of God and Understanding of The Triune GodDominic M NjugunaNo ratings yet
- Data Visualization Using Seaborn - Towards Data ScienceDocument31 pagesData Visualization Using Seaborn - Towards Data ScienceudaNo ratings yet
- CBSE Class 6 Maths Question Paper SA 2 2013Document2 pagesCBSE Class 6 Maths Question Paper SA 2 2013SujeshNo ratings yet
- Making Sense of Data I: A Practical Guide to Exploratory Data Analysis and Data MiningFrom EverandMaking Sense of Data I: A Practical Guide to Exploratory Data Analysis and Data MiningNo ratings yet
- Cluster Analysis: Concepts and Techniques - Chapter 7Document60 pagesCluster Analysis: Concepts and Techniques - Chapter 7Suchithra SalilanNo ratings yet
- Answer Key-Ecommercial ExamDocument9 pagesAnswer Key-Ecommercial ExamDonita Ginia AcuinNo ratings yet
- Supervised Learning-1Document37 pagesSupervised Learning-1Pandu KNo ratings yet
- Capstone Project - Final SubmissionDocument36 pagesCapstone Project - Final Submissionanoop kNo ratings yet
- Data Science Course ContentDocument4 pagesData Science Course ContentTR HarishNo ratings yet
- Introduction To Data Mining: Dr. Dipti Chauhan Assistant Professor SCSIT, SUAS IndoreDocument16 pagesIntroduction To Data Mining: Dr. Dipti Chauhan Assistant Professor SCSIT, SUAS IndoreroochinNo ratings yet
- Dealing With Missing Data in Python PandasDocument14 pagesDealing With Missing Data in Python PandasSelloNo ratings yet
- Data Visualization EbookDocument15 pagesData Visualization EbookBittu RanaNo ratings yet
- Entrep Week 2 Day 2 The Selling ProcessDocument10 pagesEntrep Week 2 Day 2 The Selling ProcessARLENE AQUINONo ratings yet
- Problem Statement - Foodhub: ContextDocument5 pagesProblem Statement - Foodhub: ContextJeffNo ratings yet
- Data Mining: M.P.Geetha, Department of CSE, Sri Ramakrishna Institute of Technology, CoimbatoreDocument115 pagesData Mining: M.P.Geetha, Department of CSE, Sri Ramakrishna Institute of Technology, CoimbatoreGeetha M PNo ratings yet
- FinalPaper SalesPredictionModelforBigMartDocument14 pagesFinalPaper SalesPredictionModelforBigMartGuru KowshikNo ratings yet
- Data Science Interview Preparation (#DAY 14)Document11 pagesData Science Interview Preparation (#DAY 14)ARPAN MAITYNo ratings yet
- Market Basket AnalysisDocument12 pagesMarket Basket AnalysisRohit SinghNo ratings yet
- Feature Selection Techniques in ML With Python-1Document7 pagesFeature Selection Techniques in ML With Python-1Дхиа ЕддинеNo ratings yet
- Overview of Data Analytics Lifecycle: Unit 2Document100 pagesOverview of Data Analytics Lifecycle: Unit 2Arunkumar GopuNo ratings yet
- Knime Project ReportDocument12 pagesKnime Project ReportAnsh RohatgiNo ratings yet
- Exploratory Data Analysis - Komorowski PDFDocument20 pagesExploratory Data Analysis - Komorowski PDFEdinssonRamosNo ratings yet
- Class Assignment 1 For Business AnalyticsDocument5 pagesClass Assignment 1 For Business AnalyticsBandita ParidaNo ratings yet
- Statistical Analysis 1Document94 pagesStatistical Analysis 1ShutDownNo ratings yet
- DATA MINING Chapter 1 and 2 Lect SlideDocument47 pagesDATA MINING Chapter 1 and 2 Lect SlideSanjeev ThakurNo ratings yet
- Predicting The Churn in Telecom IndustryDocument9 pagesPredicting The Churn in Telecom Industrystruggler17No ratings yet
- Program Data Mining With Business Analytics PDFDocument5 pagesProgram Data Mining With Business Analytics PDFAntonio AlvarezNo ratings yet
- Group Assignment - Data MiningDocument28 pagesGroup Assignment - Data MiningSimran SahaNo ratings yet
- 00 Course Data VisualizationDocument15 pages00 Course Data VisualizationNicholasRaheNo ratings yet
- Chapter 14 - Cluster Analysis: Data Mining For Business IntelligenceDocument31 pagesChapter 14 - Cluster Analysis: Data Mining For Business IntelligencejayNo ratings yet
- Machine Learning Project ReportDocument4 pagesMachine Learning Project ReportAshish100% (1)
- Week3 Logistic Regression Post PDFDocument110 pagesWeek3 Logistic Regression Post PDFYecheng Caroline LiuNo ratings yet
- Paper 4-Churn Prediction in Telecommunication PDFDocument3 pagesPaper 4-Churn Prediction in Telecommunication PDFOzioma IhekwoabaNo ratings yet
- 2 Forecast AccuracyDocument26 pages2 Forecast Accuracynatalie clyde matesNo ratings yet
- Data Mining FullDocument19 pagesData Mining FullTejaswini ReddyNo ratings yet
- PG Program Dsba ClassroomDocument16 pagesPG Program Dsba ClassroomAJAY SNo ratings yet
- Machine Learning GLDocument25 pagesMachine Learning GLrheaNo ratings yet
- DataScientist v2Document14 pagesDataScientist v2Hero NemoNo ratings yet
- Clustering: ISOM3360 Data Mining For Business AnalyticsDocument28 pagesClustering: ISOM3360 Data Mining For Business AnalyticsClaire LeeNo ratings yet
- Final Marketing Analysis PresentationDocument535 pagesFinal Marketing Analysis PresentationJasdeep SinghNo ratings yet
- Artificial Neural Networks Kluniversity Course HandoutDocument18 pagesArtificial Neural Networks Kluniversity Course HandoutHarish ParuchuriNo ratings yet
- Cardio Fitness ProjectDocument1 pageCardio Fitness ProjectVijay ChikkiNo ratings yet
- Data Warehousing and Data MiningDocument14 pagesData Warehousing and Data MiningAbbas Hashmi75% (4)
- 365 Data Science R Course NotesDocument20 pages365 Data Science R Course NotesGopi SahaneNo ratings yet
- Data MiningDocument85 pagesData MiningAhmad100% (1)
- Data Mining Course OverviewDocument38 pagesData Mining Course OverviewQomindawoNo ratings yet
- Pima Indian Diabetes QuestionsDocument6 pagesPima Indian Diabetes QuestionsAMAN PRAKASHNo ratings yet
- Data Cleaning and DataminingDocument54 pagesData Cleaning and DataminingMohammad Gulam AhamadNo ratings yet
- KPMG Data Analytics - Task 1Document1 pageKPMG Data Analytics - Task 1Vandana Prajapati100% (1)
- Seminar Data MiningDocument10 pagesSeminar Data MiningSreedevi KovilakathNo ratings yet
- #Draft E-MAIL: Godehard - SFDocument6 pages#Draft E-MAIL: Godehard - SFPrabhav Garg100% (1)
- Data Science & Business Analytics: Formerly Pgp-BabiDocument16 pagesData Science & Business Analytics: Formerly Pgp-Babirishi kumar SrivastavaNo ratings yet
- ABEM Terraloc Pro User ManualDocument101 pagesABEM Terraloc Pro User ManualMichael KazindaNo ratings yet
- MTU16V4000DS2000 2000kW StandbyDocument4 pagesMTU16V4000DS2000 2000kW Standbyalfan nashNo ratings yet
- TLE6288R: Smart 6 Channel Peak & Hold SwitchDocument32 pagesTLE6288R: Smart 6 Channel Peak & Hold Switchjulio montenegroNo ratings yet
- Sensitivity AnalysisDocument26 pagesSensitivity Analysisebinsams007No ratings yet
- Ana Perić: Teaching ProfessionalDocument9 pagesAna Perić: Teaching ProfessionalSrdjan DjurdjevicNo ratings yet
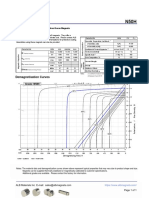
- N50H Grade Neodymium Magnets DataDocument1 pageN50H Grade Neodymium Magnets DataSteve HsuNo ratings yet
- p1648 شيفروليه كود مضاد للسرقة رمز أمان خاطئDocument4 pagesp1648 شيفروليه كود مضاد للسرقة رمز أمان خاطئemad AhmadNo ratings yet
- Toliss Airbus A319 V1.6 - Simulation ManualDocument57 pagesToliss Airbus A319 V1.6 - Simulation ManualAdrianoNo ratings yet
- The Letters of Christina RossettiDocument823 pagesThe Letters of Christina RossettiSun GrafixNo ratings yet
- RELIQUIA Asme PDFDocument1,450 pagesRELIQUIA Asme PDFFernando MuñozNo ratings yet
- Themes - Overview - iOS Human Interface GuidelinesDocument3 pagesThemes - Overview - iOS Human Interface Guidelineskhaled alahmadNo ratings yet
- Assignment 2 Course 4Document6 pagesAssignment 2 Course 4arbaan malikNo ratings yet
- MSDS Petron Diesel MaxDocument5 pagesMSDS Petron Diesel MaxDomsNo ratings yet
- CattsDocument39 pagesCattsMel SeoaneNo ratings yet
- Moving Iron Instruments: Type Iq 48 Iq Iq 96Document1 pageMoving Iron Instruments: Type Iq 48 Iq Iq 96AkmalNo ratings yet
- Auto-Tune 7.1.2 VST PC Notes: InstallationDocument4 pagesAuto-Tune 7.1.2 VST PC Notes: InstallationDeJa AustonNo ratings yet
- Standard Insurance Co., Inc. vs. CuaresmaDocument14 pagesStandard Insurance Co., Inc. vs. CuaresmaTJ Dasalla GallardoNo ratings yet
- Opito International GuidelinesDocument65 pagesOpito International GuidelinesKleine SterNo ratings yet
- UEW Referee Report Form - 67Document2 pagesUEW Referee Report Form - 67ambright mawunyoNo ratings yet
- Descriptive Geometry II: Jan 15/ 2022 Muhammed ADocument41 pagesDescriptive Geometry II: Jan 15/ 2022 Muhammed AHULE ADDIS ENTERTAINMENTNo ratings yet