You might also like
- TimeSeriesAnalysis&ItsApplications2e Shumway PDFDocument82 pagesTimeSeriesAnalysis&ItsApplications2e Shumway PDFClaudio Ramón Rodriguez Mondragón91% (11)
- Fundamentals of Biostatistics 8th Edition Rosner Solutions ManualDocument20 pagesFundamentals of Biostatistics 8th Edition Rosner Solutions Manualfarahcan2facaNo ratings yet
- Applied Calculus For Business Economics and The Social and Life Sciences 11th Edition Hoffmann Test BankDocument11 pagesApplied Calculus For Business Economics and The Social and Life Sciences 11th Edition Hoffmann Test Banktestbankloo100% (1)
- Solution Exercises 2011 PartIDocument27 pagesSolution Exercises 2011 PartIcecch001100% (1)
- Solutions Chapter 9Document34 pagesSolutions Chapter 9reloadedmemoryNo ratings yet
- Financial Accounting IFRS EditionDocument1 pageFinancial Accounting IFRS EditionAcho JieNo ratings yet
- Financial Accounting IFRS EditionDocument1 pageFinancial Accounting IFRS EditionAcho Jie100% (1)
- Tests of HypothesisDocument48 pagesTests of HypothesisDenmark Aleluya0% (1)
- Chapter 12Document38 pagesChapter 12Joseph Kandalaft100% (1)
- DNN Cluster S2 22 MidSem RegularDocument6 pagesDNN Cluster S2 22 MidSem RegularrahulsgaykeNo ratings yet
- Undergraduate Econometrics, 2 Edition-Chapter 11: Slide 11.1Document32 pagesUndergraduate Econometrics, 2 Edition-Chapter 11: Slide 11.1Acho JieNo ratings yet
- Undergraduate EconometricDocument34 pagesUndergraduate EconometricAcho JieNo ratings yet
- Fundamentals of Biostatistics 8th Edition Rosner Solutions ManualDocument25 pagesFundamentals of Biostatistics 8th Edition Rosner Solutions Manualmeseemssum.o3u6100% (41)
- Stata Lab4 2023Document36 pagesStata Lab4 2023Aadhav JayarajNo ratings yet
- Chapter 12 Homework Answer: T T+J TDocument3 pagesChapter 12 Homework Answer: T T+J TkNo ratings yet
- Beam by DiracDocument10 pagesBeam by DiracShubham GuptaNo ratings yet
- Beam de Ections by Discontinuity FunctionsDocument10 pagesBeam de Ections by Discontinuity FunctionsRamesh JangalaNo ratings yet
- Linear Algebraic Equations: N' Ax C A' NXN' C' nx1' X' nx1' LUDocument85 pagesLinear Algebraic Equations: N' Ax C A' NXN' C' nx1' X' nx1' LUThangadurai Senthil Ram PrabhuNo ratings yet
- Problema 6-23 ShigleyDocument7 pagesProblema 6-23 ShigleylosdesquiciadosNo ratings yet
- Learning Outcome 2 - Ac 2 (Analytical Methods)Document7 pagesLearning Outcome 2 - Ac 2 (Analytical Methods)Chan Siew ChongNo ratings yet
- Var SvarDocument31 pagesVar SvarEddie Barrionuevo100% (1)
- Divide and Conquer PDFDocument34 pagesDivide and Conquer PDFDini FitrianiNo ratings yet
- Vector Calc SummaryDocument7 pagesVector Calc SummaryJedwin VillanuevaNo ratings yet
- VAR Models: U y A y A y A yDocument15 pagesVAR Models: U y A y A y A yvmahdiNo ratings yet
- ME2115 - LumiNUS Mock-Up - SolutionsDocument6 pagesME2115 - LumiNUS Mock-Up - SolutionsCl SkyeNo ratings yet
- Lecture 4 - FD Analysis of Anisotropic Transmission LinesDocument20 pagesLecture 4 - FD Analysis of Anisotropic Transmission Linesjesus1843No ratings yet
- Solutions Manual Scientific ComputingDocument192 pagesSolutions Manual Scientific ComputingSanjeev Gupta0% (1)
- Week 1 - Part BDocument13 pagesWeek 1 - Part BHanxian LiangNo ratings yet
- LW 1119 Amath250notesDocument8 pagesLW 1119 Amath250notesuser2357No ratings yet
- Solu 4Document44 pagesSolu 4Eric FansiNo ratings yet
- Simultaneous Linear Equations: Gauss-Seidel Method: Lesson-4-08Document10 pagesSimultaneous Linear Equations: Gauss-Seidel Method: Lesson-4-08Thiam Chun OngNo ratings yet
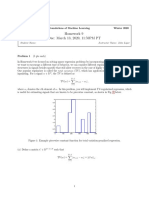
- Homework 9 Due: March 13, 2020, 11:59PM PTDocument2 pagesHomework 9 Due: March 13, 2020, 11:59PM PTPrateek VasudevNo ratings yet
- A M M e S B S: C e F P R PLSDocument15 pagesA M M e S B S: C e F P R PLSBengt HörbergNo ratings yet
- Experiment 22 PDFDocument6 pagesExperiment 22 PDFSoz BinaviNo ratings yet
- Serialkinematicsv2 Reference PakaiDocument12 pagesSerialkinematicsv2 Reference PakaitheonNo ratings yet
- Solution Manual For Fundamentals of Biostatistics 8Th Edition by Rosner Isbn 130526892X 9781305268920 Full Chapter PDFDocument19 pagesSolution Manual For Fundamentals of Biostatistics 8Th Edition by Rosner Isbn 130526892X 9781305268920 Full Chapter PDFgeorge.langham852100% (12)
- Fundamentals of Biostatistics 8th Edition by Rosner ISBN 130526892X Solution ManualDocument19 pagesFundamentals of Biostatistics 8th Edition by Rosner ISBN 130526892X Solution Manualdella100% (24)
- Game TheoryDocument14 pagesGame TheorySarangaHazarikaNo ratings yet
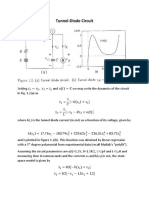
- Tunnel DiodeDocument5 pagesTunnel DiodeKiran PandeyNo ratings yet
- Midterm 2 Exam: Y-Parameters of The Amplifier With Feedback in (Ii) - You Must Show Your Work. (3 Points)Document9 pagesMidterm 2 Exam: Y-Parameters of The Amplifier With Feedback in (Ii) - You Must Show Your Work. (3 Points)Shubhresh Kumar JhaNo ratings yet
- CH 09 Part SolutionDocument10 pagesCH 09 Part SolutionHamid MojiryNo ratings yet
- S Ccs AnswersDocument192 pagesS Ccs AnswersnoshinNo ratings yet
- 2DoF General Method RevisedDocument3 pages2DoF General Method Revisedrory mcelhinneyNo ratings yet
- New Support Vector Algorithms: LetterDocument39 pagesNew Support Vector Algorithms: LetterSr. RZNo ratings yet
- ρA ´u x, t ∂ p x,t ∂ x b x, tDocument8 pagesρA ´u x, t ∂ p x,t ∂ x b x, tAlicia HambureNo ratings yet
- Summation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable CoefficientsDocument33 pagesSummation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable Coefficientsadsfhire fklwjeNo ratings yet
- Quiz3 2015 SolutionsDocument8 pagesQuiz3 2015 SolutionsGerald RattichNo ratings yet
- 19ECE201 MidTerm KeyDocument2 pages19ECE201 MidTerm KeyabhijithNo ratings yet
- Lec4 08Document8 pagesLec4 08alanpicard2303No ratings yet
- Numerical Solution of Initial Value ProblemsDocument17 pagesNumerical Solution of Initial Value ProblemslambdaStudent_eplNo ratings yet
- Kevin Swingler - Lecture 3: Delta RuleDocument10 pagesKevin Swingler - Lecture 3: Delta RuleRoots999No ratings yet
- Linear System Theory Fall 2011 Final Exam Questions With SolutionsDocument6 pagesLinear System Theory Fall 2011 Final Exam Questions With SolutionsFakhar AbbasNo ratings yet
- Adaptive Quadrature - RevisitedDocument18 pagesAdaptive Quadrature - RevisitedSaifuddin AriefNo ratings yet
- Adaptive Quadrature RevisitedDocument19 pagesAdaptive Quadrature RevisitedVenkatesh PeriasamyNo ratings yet
- Beam Deflection by Discontinuity FunctionsDocument10 pagesBeam Deflection by Discontinuity Functionsmiry89No ratings yet
- ch08 AnsDocument20 pagesch08 Ansrifdah abadiyahNo ratings yet
- Lab 2-CS-LabDocument7 pagesLab 2-CS-Labهاشمی دانشNo ratings yet
- Book Problem Solutions Separate PagesDocument121 pagesBook Problem Solutions Separate PagesrathanNo ratings yet
- ELE8311 - Module 2B - Inversion of Z-TransformDocument8 pagesELE8311 - Module 2B - Inversion of Z-TransformUmarSaboBabaDoguwaNo ratings yet
- 8Vhu&Kdujhvlq/Rfdo Ryhuqphqw) LQDQFH 5Lfkdug0%LugDocument26 pages8Vhu&Kdujhvlq/Rfdo Ryhuqphqw) LQDQFH 5Lfkdug0%LugAcho JieNo ratings yet
- Financial Accounting IFRS EditionDocument1 pageFinancial Accounting IFRS EditionAcho JieNo ratings yet
- Financial Accounting IFRS Edition 10a PDFDocument1 pageFinancial Accounting IFRS Edition 10a PDFAcho JieNo ratings yet
- Financial Accounting IFRS Edition 05a PDFDocument1 pageFinancial Accounting IFRS Edition 05a PDFAcho JieNo ratings yet
- Financial Accounting IFRS EditionDocument1 pageFinancial Accounting IFRS EditionAcho JieNo ratings yet
- Financial Accounting IFRS EditionDocument1 pageFinancial Accounting IFRS EditionAcho JieNo ratings yet
- Financial Accounting IFRS Edition 04aDocument1 pageFinancial Accounting IFRS Edition 04aAcho JieNo ratings yet
- Financial Accounting IFRS EditionDocument1 pageFinancial Accounting IFRS EditionAcho JieNo ratings yet
- Undergraduate EconometricDocument40 pagesUndergraduate EconometricAcho JieNo ratings yet
- Undergraduate EconometricDocument44 pagesUndergraduate EconometricAcho JieNo ratings yet
- R. Martonak, D. Marx and P. Nielaba - Quantum Fluctuations Driven Orientational Disordering: A Finite-Size Scaling StudyDocument50 pagesR. Martonak, D. Marx and P. Nielaba - Quantum Fluctuations Driven Orientational Disordering: A Finite-Size Scaling StudyYidel4313No ratings yet
- Exploration of The Quantum Casimir Effect: A. TorodeDocument7 pagesExploration of The Quantum Casimir Effect: A. Torodesayandatta1No ratings yet
- OrganizationDocument2 pagesOrganizationhulusi CengizNo ratings yet
- Sta301 1-9Document9 pagesSta301 1-9thornapple25No ratings yet
- Hydrogen Atom: Numerical MethodsDocument11 pagesHydrogen Atom: Numerical MethodsBryan HarterNo ratings yet
- (Edward Anderson) The Problem of Time Quantum Mech (B-Ok - CC)Document917 pages(Edward Anderson) The Problem of Time Quantum Mech (B-Ok - CC)Ujjwal Gupta100% (4)
- Phys.303-Classical Mechanics Ii - Lectur PDFDocument184 pagesPhys.303-Classical Mechanics Ii - Lectur PDFZaviraNabillaNo ratings yet
- A Simple Random Walk ModelDocument1 pageA Simple Random Walk ModelHaji XeeshanNo ratings yet
- Paul Dirac: A Genius in The History of Physics: Richard DalitzDocument4 pagesPaul Dirac: A Genius in The History of Physics: Richard DalitzLeonNo ratings yet
- Test Bank For Behavior Modification Principles and Procedures 5th Edition Miltenberger DownloadDocument11 pagesTest Bank For Behavior Modification Principles and Procedures 5th Edition Miltenberger Downloadjuliekimbmcnygjrkx100% (28)
- HiggsDocument31 pagesHiggsJacques SmeetsNo ratings yet
- Wave Function in A Periodic Potential and Bloch The-OremDocument3 pagesWave Function in A Periodic Potential and Bloch The-OremSajisk Sk100% (1)
- What We Can Learn About Quantum Physics From A Single Qubit: Wolfgang - Duer@uibk - Ac.at Stefan - Heusler@uni-Muenster - deDocument15 pagesWhat We Can Learn About Quantum Physics From A Single Qubit: Wolfgang - Duer@uibk - Ac.at Stefan - Heusler@uni-Muenster - deAdrian CamachoNo ratings yet
- Arfken MMCH 9 S 4 e 6Document2 pagesArfken MMCH 9 S 4 e 6Suresh Chandra JoshiNo ratings yet
- Mathematical ExpectationDocument49 pagesMathematical ExpectationnofiarozaNo ratings yet
- T2 Skript BertlmannDocument186 pagesT2 Skript BertlmannFaulwienixNo ratings yet
- An Integrable (Classical and Quantum) Four-Wave Mixing Hamiltonian SystemDocument19 pagesAn Integrable (Classical and Quantum) Four-Wave Mixing Hamiltonian Systempippo50@No ratings yet
- 11 One Way AnovaDocument24 pages11 One Way AnovaSyed Ijlal HaiderNo ratings yet
- Formula Sheet and Statistical TablesDocument11 pagesFormula Sheet and Statistical TablesdonatchangeNo ratings yet
- An Spss Case StudyDocument8 pagesAn Spss Case StudyVenkata Ramana MurthyNo ratings yet
- The WKB Approximation: Griffiths Problem 8.2: Alternative Derivation of WKBDocument6 pagesThe WKB Approximation: Griffiths Problem 8.2: Alternative Derivation of WKBkanchankonwarNo ratings yet
- Statistical TreatmentsDocument34 pagesStatistical TreatmentsElmery Chrysolite Casinillo VelascoNo ratings yet
- Hypothesis Test With Chi SquareDocument34 pagesHypothesis Test With Chi SquareBenj AndresNo ratings yet
- Continuous ProbabilityDocument38 pagesContinuous ProbabilitysarahNo ratings yet
- μ x̄=205 μ≠179 (claim) s=26Document9 pagesμ x̄=205 μ≠179 (claim) s=26Jykx SiaoNo ratings yet
- Semc 3 QDocument9 pagesSemc 3 QshelygandhiNo ratings yet
- Helium Atom, Approximate Methods: 22nd April 2008Document17 pagesHelium Atom, Approximate Methods: 22nd April 2008Julian David Henao EscobarNo ratings yet
- L6 Scattering PartialWavesDocument19 pagesL6 Scattering PartialWavesdwyphy100% (1)