You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Book Summary The Secrets of Millionaire MindDocument5 pagesBook Summary The Secrets of Millionaire MindRajeev Bahuguna100% (7)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Tips To Perform A Ram Study Webinar Presentation - tcm4-539661Document38 pagesTips To Perform A Ram Study Webinar Presentation - tcm4-539661Brenda Davis100% (3)
- Key Issues in E-Learning (1847063608)Document180 pagesKey Issues in E-Learning (1847063608)nafiz100% (3)
- Content AnalysisDocument34 pagesContent AnalysisKristian Ray Evangelista100% (1)
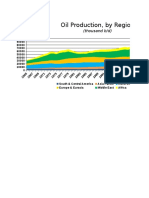
- Kno Ema Energy Data Cheat Sheet June 2017Document1 pageKno Ema Energy Data Cheat Sheet June 2017Sudha SivadasNo ratings yet
- World Natural Gas ProductionDocument4 pagesWorld Natural Gas ProductionBrenda DavisNo ratings yet
- Egypt Population Forecast: Population Yearly Change Change Yearly %Document4 pagesEgypt Population Forecast: Population Yearly Change Change Yearly %Brenda DavisNo ratings yet
- The Use of DRA in Crude OilDocument23 pagesThe Use of DRA in Crude OilBrenda DavisNo ratings yet
- BP Statistical Review of World Energy, 2016Document4 pagesBP Statistical Review of World Energy, 2016Brenda DavisNo ratings yet
- 3Ph Horiz Sep 2010 Weir VerA SIDocument5 pages3Ph Horiz Sep 2010 Weir VerA SIBrenda DavisNo ratings yet
- Crude Oil Transport Risks and Impacts PDFDocument16 pagesCrude Oil Transport Risks and Impacts PDFBrenda Davis100% (1)
- Modeling and Simulation of Membrane Separation Process Using Computational Fluid DynamicsDocument26 pagesModeling and Simulation of Membrane Separation Process Using Computational Fluid DynamicsBrenda DavisNo ratings yet
- O&G Modeling Course Outline OfferDocument28 pagesO&G Modeling Course Outline OfferBrenda DavisNo ratings yet
- Aspen HYSYS - New Feature AvailabilityDocument1 pageAspen HYSYS - New Feature AvailabilityBrenda DavisNo ratings yet
- Crude Oil Refining UpgradingDocument13 pagesCrude Oil Refining UpgradingBrenda DavisNo ratings yet
- Course Name: PMP Exam Preparation Course Course ObjectiveDocument1 pageCourse Name: PMP Exam Preparation Course Course ObjectiveBrenda DavisNo ratings yet
- Orifice CharacteristicsDocument1 pageOrifice CharacteristicsBrenda DavisNo ratings yet
- Nothingness: 1. Why Is There Something Rather Than Nothing?Document20 pagesNothingness: 1. Why Is There Something Rather Than Nothing?Talha MahmoodNo ratings yet
- Chapter 3 - Utility Theory: ST Petersburg ParadoxDocument77 pagesChapter 3 - Utility Theory: ST Petersburg Paradoxabc123No ratings yet
- The 2016 Presidential Election-An Abundance of ControversiesDocument20 pagesThe 2016 Presidential Election-An Abundance of ControversiesHoover InstitutionNo ratings yet
- Bakhtin X VygotskyDocument17 pagesBakhtin X VygotskyMARCOS MORAES CALAZANSNo ratings yet
- Palm Tree and DatesDocument2 pagesPalm Tree and DatesGhulam Hassan KhanNo ratings yet
- QuranDocument4 pagesQuranmohiNo ratings yet
- 04 The Nation State Postcolonial Theory and Global ViolenceDocument22 pages04 The Nation State Postcolonial Theory and Global Violenceu2102618No ratings yet
- Child's GuideDocument14 pagesChild's Guidet59409t045No ratings yet
- 01 The Tragedy of The Commons Garrett HardinDocument5 pages01 The Tragedy of The Commons Garrett HardinRaphael IrerêNo ratings yet
- Binder 1996 FluencyDocument35 pagesBinder 1996 FluencyAnonymous YfCPPhri8lNo ratings yet
- Impact of Counter-Terrorism On Communities - Methodology ReportDocument56 pagesImpact of Counter-Terrorism On Communities - Methodology ReportPaulo FelixNo ratings yet
- Ahlin Marceta 2019 PDFDocument11 pagesAhlin Marceta 2019 PDFRazero4No ratings yet
- Jekyllyhyde LibretoDocument32 pagesJekyllyhyde LibretoErick Constan D Montreuil OrnayNo ratings yet
- 10 Norman 1Document15 pages10 Norman 1Bryan GoodmanNo ratings yet
- James Brian GDocument5 pagesJames Brian GJames Brian Garcia GarayNo ratings yet
- The Teaching of The History of Rwanda, A Participative ApproachDocument113 pagesThe Teaching of The History of Rwanda, A Participative ApproachKagatamaNo ratings yet
- Imam Gunadi FebDocument123 pagesImam Gunadi FebBima HermasthoNo ratings yet
- Kidambi and Aakella 2007 (Social Audits in Andhra)Document2 pagesKidambi and Aakella 2007 (Social Audits in Andhra)rozgarNo ratings yet
- Hydraulic Coefficients of Orifice and Bernoulli TheoremDocument5 pagesHydraulic Coefficients of Orifice and Bernoulli TheoremerronNo ratings yet
- Review of Esu Yoruba God Power and The IDocument7 pagesReview of Esu Yoruba God Power and The IBoris MilovicNo ratings yet
- BibliographiesDocument7 pagesBibliographiesINA ISABEL FULONo ratings yet
- Marvaso - ChristInFire Book - ReducedDocument102 pagesMarvaso - ChristInFire Book - ReducedGeorge Marvaso Sr100% (1)
- Bannari Amman Sugars LTD Vs Commercial Tax Officer and OthersDocument15 pagesBannari Amman Sugars LTD Vs Commercial Tax Officer and Othersvrajamabl100% (2)
- Philo of Alexandria An Exegete For His Time - Peder BorgenDocument10 pagesPhilo of Alexandria An Exegete For His Time - Peder BorgenTemirbek BolotNo ratings yet
- Audio Transformers ChapterDocument49 pagesAudio Transformers ChapterbabumazumderrNo ratings yet
- Drama Strand - Progression Through Freeze Frame ActivityDocument8 pagesDrama Strand - Progression Through Freeze Frame ActivitySyafiq IzharNo ratings yet
- Criminological ResearchDocument209 pagesCriminological ResearchBRYANTRONICO50% (2)