You might also like
- Semi-Supervised Learning A Brief ReviewDocument6 pagesSemi-Supervised Learning A Brief ReviewReshma KhemchandaniNo ratings yet
- Energy Efficiency Techniques in Cloud CoDocument7 pagesEnergy Efficiency Techniques in Cloud Coviju001No ratings yet
- A Detailed Excursion On Machine Learning Approach, Algorithms and ApplicationsDocument8 pagesA Detailed Excursion On Machine Learning Approach, Algorithms and Applicationsviju001No ratings yet
- Air Quality2Document11 pagesAir Quality2viju001No ratings yet
- Journal Pone 0247330Document14 pagesJournal Pone 0247330viju001No ratings yet
- Jurisoo Tarkvaratehnika 2017Document45 pagesJurisoo Tarkvaratehnika 2017viju001No ratings yet
- Silviu Risco ThesisDocument308 pagesSilviu Risco Thesisviju001No ratings yet
- Fingerprint Orientation Field Enhancement: April 2011Document9 pagesFingerprint Orientation Field Enhancement: April 2011viju001No ratings yet
- LubnaAlhenaki Project4Document20 pagesLubnaAlhenaki Project4viju001No ratings yet
- Data Mining Analysis of The Parkinsons DiseaseDocument107 pagesData Mining Analysis of The Parkinsons Diseaseviju001No ratings yet
- Handling Missing Data Analysis of A Challenging Data Set Using Multiple ImputationDocument20 pagesHandling Missing Data Analysis of A Challenging Data Set Using Multiple Imputationviju001No ratings yet
- State Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest CertificateDocument1 pageState Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest Certificateviju001100% (1)
- Big Data Analytics in Supply Chain Management: A Systematic Literature Review and Research DirectionsDocument29 pagesBig Data Analytics in Supply Chain Management: A Systematic Literature Review and Research Directionsviju001No ratings yet
- Using Using Using Using Using Using Using Using Using Namespace Public Partial ClassDocument14 pagesUsing Using Using Using Using Using Using Using Using Namespace Public Partial Classviju001No ratings yet
- Deep Recurrent Level Set For Segmenting Brain TumorsDocument8 pagesDeep Recurrent Level Set For Segmenting Brain Tumorsviju001No ratings yet
- Iot Based Biometric Attendance System Using ArduinoDocument108 pagesIot Based Biometric Attendance System Using Arduinoviju001No ratings yet
- Fingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya MishraDocument5 pagesFingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya Mishraviju001No ratings yet
- A New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita NathDocument5 pagesA New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita Nathviju001No ratings yet
- 06 - Chapter 3Document36 pages06 - Chapter 3viju001No ratings yet
- Support Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball ClusteringDocument9 pagesSupport Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball Clusteringviju001No ratings yet
- 14 - Chapter 6Document7 pages14 - Chapter 6viju001No ratings yet
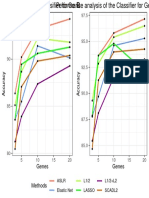
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Document1 pageGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001No ratings yet
- Literature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle PrintDocument24 pagesLiterature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle Printviju001No ratings yet
- Biometric Fingerprint Student Attendance System: Software Requirement SpecificationsDocument19 pagesBiometric Fingerprint Student Attendance System: Software Requirement Specificationsviju001No ratings yet
- 10 - Chapter 1Document22 pages10 - Chapter 1viju001No ratings yet
- T.A. & D.A. BillDocument1 pageT.A. & D.A. Billviju001No ratings yet
- Decision Making With Unknown Data: Development of ELECTRE Method Based On Black NumbersDocument16 pagesDecision Making With Unknown Data: Development of ELECTRE Method Based On Black Numbersviju001No ratings yet
- Fingerprint Enhancement Using Improved Orientation and Circular Gabor FilterDocument7 pagesFingerprint Enhancement Using Improved Orientation and Circular Gabor Filterviju001No ratings yet
- 04 - Chapter 1Document19 pages04 - Chapter 1viju001No ratings yet
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Document1 pageGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001No ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Febryruthwahyuni Lds g1718 Bilphy MRDocument11 pagesFebryruthwahyuni Lds g1718 Bilphy MRfebry sihiteNo ratings yet
- Law Sample QuestionDocument2 pagesLaw Sample QuestionknmodiNo ratings yet
- Pros and Cons of AbortionDocument14 pagesPros and Cons of AbortionSuman SarekukkaNo ratings yet
- MLOG GX CMXA75 v4.05 322985e0 UM-EN PDFDocument342 pagesMLOG GX CMXA75 v4.05 322985e0 UM-EN PDFGandalf cimarillonNo ratings yet
- Main Book LR X PDFDocument192 pagesMain Book LR X PDFjay danenjeyanNo ratings yet
- Alb Ani A BrochureDocument18 pagesAlb Ani A BrochurejskardaNo ratings yet
- CLASSIFICATION OF COSTS: Manufacturing: Subhash Sahu (Cs Executive Student of Jaipur Chapter)Document85 pagesCLASSIFICATION OF COSTS: Manufacturing: Subhash Sahu (Cs Executive Student of Jaipur Chapter)shubhamNo ratings yet
- Automatic Water Level Indicator and Controller by Using ARDUINODocument10 pagesAutomatic Water Level Indicator and Controller by Using ARDUINOSounds of PeaceNo ratings yet
- A Proposed Approach To Handling Unbounded Dependencies in Automatic ParsersDocument149 pagesA Proposed Approach To Handling Unbounded Dependencies in Automatic ParsersRamy Al-GamalNo ratings yet
- My Cook BookDocument66 pagesMy Cook BookAkshay KumariNo ratings yet
- Swot Analysis of PiramalDocument5 pagesSwot Analysis of PiramalPalak NarangNo ratings yet
- Exam in Analytic Geometry With AnswersDocument4 pagesExam in Analytic Geometry With Answersmvmbapple100% (6)
- Kuis 4Document10 pagesKuis 4Deri AntoNo ratings yet
- Eva Braun Life With Hitler PDFDocument2 pagesEva Braun Life With Hitler PDFPamela0% (1)
- Eliminate Zombie Nouns and Minimize Passive Voice: Plain LanguageDocument2 pagesEliminate Zombie Nouns and Minimize Passive Voice: Plain LanguagePădure IonuțNo ratings yet
- Department of Education: Weekly Learning PlanDocument4 pagesDepartment of Education: Weekly Learning PlanJanine Galas DulacaNo ratings yet
- STGS7115-B3 Mini Esmeriladoramanualusuario-29505070 PDFDocument14 pagesSTGS7115-B3 Mini Esmeriladoramanualusuario-29505070 PDFHydro Energy GroupNo ratings yet
- Carnatic Music NotationDocument6 pagesCarnatic Music Notationksenthil kumar100% (1)
- The Great Psychotherapy Debate PDFDocument223 pagesThe Great Psychotherapy Debate PDFCasey Lewis100% (9)
- Case DigestsDocument12 pagesCase DigestsHusni B. SaripNo ratings yet
- How To Install Linux, Apache, MySQL, PHP (LAMP) Stack On Ubuntu 16.04Document12 pagesHow To Install Linux, Apache, MySQL, PHP (LAMP) Stack On Ubuntu 16.04Rajesh kNo ratings yet
- Students Name - Kendrick Joel Fernandes ROLL NO. 8250 Semester Vi Subject - Turnaround Management Topic-Industrial SicknessDocument15 pagesStudents Name - Kendrick Joel Fernandes ROLL NO. 8250 Semester Vi Subject - Turnaround Management Topic-Industrial SicknesskarenNo ratings yet
- Eastwoods: College of Science and Technology, IncDocument2 pagesEastwoods: College of Science and Technology, IncMichael AustriaNo ratings yet
- Rockonomics: Book Non-Fiction US & Canada Crown Publishing (Ed. Roger Scholl) UK & Comm John Murray (Ed. Nick Davies)Document2 pagesRockonomics: Book Non-Fiction US & Canada Crown Publishing (Ed. Roger Scholl) UK & Comm John Murray (Ed. Nick Davies)Natasha DanchevskaNo ratings yet
- Sustainable Building: Submitted By-Naitik JaiswalDocument17 pagesSustainable Building: Submitted By-Naitik JaiswalNaitik JaiswalNo ratings yet
- The Til Pat YearsDocument1 pageThe Til Pat Yearsrajkumarvpost6508No ratings yet
- CrossFit Wod Tracking JournalDocument142 pagesCrossFit Wod Tracking JournalJavier Estelles Muñoz0% (1)
- Public Utility Accounting Manual 2018Document115 pagesPublic Utility Accounting Manual 2018effieladureNo ratings yet
- Toyota Corolla AE80 - 2 - 3 01 - 85-08 - 86 Corolla (PDFDrive)Document107 pagesToyota Corolla AE80 - 2 - 3 01 - 85-08 - 86 Corolla (PDFDrive)Abhay Kumar Sharma BOODHOONo ratings yet
- Policing System Indonesia PolicingDocument5 pagesPolicing System Indonesia Policingdanilo bituin jrNo ratings yet