You might also like
- List of Refrigerants PDFDocument15 pagesList of Refrigerants PDFFrancis Boey50% (2)
- Environmental Impact AssessmentDocument19 pagesEnvironmental Impact AssessmentbbnNo ratings yet
- Air Quality Prediction Using Machine Learning AlgorithmsDocument4 pagesAir Quality Prediction Using Machine Learning AlgorithmsATS100% (1)
- EnvironmentalDocument24 pagesEnvironmentalLivanshu Garg100% (1)
- Prediction of Air Pollution in Smart Cities Using Machine Learning TechniquesDocument7 pagesPrediction of Air Pollution in Smart Cities Using Machine Learning TechniquesIJRASETPublicationsNo ratings yet
- Chapter 3 LEED Documentation Proce 2016 LEED v4 Practices CertificationDocument42 pagesChapter 3 LEED Documentation Proce 2016 LEED v4 Practices CertificationTrần Khắc Độ100% (1)
- A Review On Pipeline Condition Prediction MethodsDocument15 pagesA Review On Pipeline Condition Prediction Methodsbalakrishna100% (1)
- WELL Building Standard v2.2Document269 pagesWELL Building Standard v2.2Anisio Jovanaci100% (1)
- Prediction and Classification of Weather Using Machine LearningDocument8 pagesPrediction and Classification of Weather Using Machine LearningIJRASETPublications100% (1)
- Evaluating Environmental and Social Impact Assessment in Developing CountriesFrom EverandEvaluating Environmental and Social Impact Assessment in Developing CountriesNo ratings yet
- Airquality PredictionDocument5 pagesAirquality PredictionSachin MishraNo ratings yet
- Hybrid Algorithms Based On Historical Accuracy For Forecasting Particulate Matter ConcentrationsDocument9 pagesHybrid Algorithms Based On Historical Accuracy For Forecasting Particulate Matter ConcentrationsIAES IJAINo ratings yet
- 4 TH Literature PaperDocument23 pages4 TH Literature PaperKunigiri RaghunathNo ratings yet
- 4 TH Literature PaperDocument23 pages4 TH Literature PaperKunigiri RaghunathNo ratings yet
- RegressionpaperDocument7 pagesRegressionpaperPramendra Kumar SinghNo ratings yet
- Air Quality Forecasting Using Deep Learning FrameworkDocument8 pagesAir Quality Forecasting Using Deep Learning FrameworkIJRASETPublicationsNo ratings yet
- Jurnal Ijtech Albert Husin, DitaDocument11 pagesJurnal Ijtech Albert Husin, DitaditaNo ratings yet
- 4685-Article Text-10183-1-10-20180814Document25 pages4685-Article Text-10183-1-10-20180814Darmawansyah -No ratings yet
- Sensors: A Deep CNN-LSTM Model For Particulate Matter (PM) Forecasting in Smart CitiesDocument22 pagesSensors: A Deep CNN-LSTM Model For Particulate Matter (PM) Forecasting in Smart CitiesSenthil MuruganNo ratings yet
- AQI 3 FixDocument21 pagesAQI 3 FixEven AmsikanNo ratings yet
- A Novel Coupled Optimization Prediction Model For Air QualityDocument19 pagesA Novel Coupled Optimization Prediction Model For Air QualityFresy NugrohoNo ratings yet
- IoT Based Real Time Air Pollution Monitoring SystemDocument15 pagesIoT Based Real Time Air Pollution Monitoring SystemJunel JovenNo ratings yet
- Prediction of Air Quality Index Using Supervised Machine LearningDocument14 pagesPrediction of Air Quality Index Using Supervised Machine LearningIJRASETPublicationsNo ratings yet
- Applied SciencesDocument32 pagesApplied SciencesImran KhanNo ratings yet
- GJESM Volume5 Issue4 Pages515-534Document21 pagesGJESM Volume5 Issue4 Pages515-534Fathia AgboolaNo ratings yet
- Emissions and Fuel Consumption Modeling For EvaluaDocument11 pagesEmissions and Fuel Consumption Modeling For EvaluaEdwin SilvaNo ratings yet
- Digital Twin of Atmospheric Environment Sensory Data Fusion For High-Resolution PM2.5 Estimation and Action Policies RecommendationDocument10 pagesDigital Twin of Atmospheric Environment Sensory Data Fusion For High-Resolution PM2.5 Estimation and Action Policies RecommendationFresy NugrohoNo ratings yet
- State-Of-Art Review of Traffic Signal Control Methods: Challenges and OpportunitiesDocument23 pagesState-Of-Art Review of Traffic Signal Control Methods: Challenges and OpportunitiesDung NguyenNo ratings yet
- Prediction of Delhi's Air Quality Index Using Deep Learning ApproachDocument7 pagesPrediction of Delhi's Air Quality Index Using Deep Learning ApproachInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- IOT Based Air Quality Monitoring System Using MQ13Document9 pagesIOT Based Air Quality Monitoring System Using MQ13AlphaNo ratings yet
- A Predictive Data Feature Exploration-Based Air Quality Prediction ApproachDocument12 pagesA Predictive Data Feature Exploration-Based Air Quality Prediction ApproachbellaNo ratings yet
- Predicting Air PollutionDocument4 pagesPredicting Air PollutionYash DhanwantriNo ratings yet
- Air Quality Prediction Using Linear RegressionDocument22 pagesAir Quality Prediction Using Linear RegressionMisba nausheenNo ratings yet
- Comparative Analysis Study For Air Quality Prediction in Smart Cities Using Regression TechniquesDocument10 pagesComparative Analysis Study For Air Quality Prediction in Smart Cities Using Regression TechniquesFresy NugrohoNo ratings yet
- 1 VOL27editedDocument28 pages1 VOL27editedNunyaNo ratings yet
- 3 RD Literature PaperDocument5 pages3 RD Literature PaperKunigiri RaghunathNo ratings yet
- Implementation Paper On Network DataDocument6 pagesImplementation Paper On Network DataIJRASETPublicationsNo ratings yet
- Proposal of Testing Process For Service Systems: Masaryk University Faculty of InformaticsDocument25 pagesProposal of Testing Process For Service Systems: Masaryk University Faculty of InformaticsN KumarNo ratings yet
- Forecasting and Prediction of Air Pollution Levels To Protect Human Beings From Health HazardsDocument5 pagesForecasting and Prediction of Air Pollution Levels To Protect Human Beings From Health HazardsAisyah IinNo ratings yet
- Weather Forecast Prediction An Integrated ApproachDocument6 pagesWeather Forecast Prediction An Integrated ApproachNikita NawleNo ratings yet
- Data Mining in The Prediction of Impacts of Ambient Air Quality Data Analysis in Urban and Industrial AreaDocument5 pagesData Mining in The Prediction of Impacts of Ambient Air Quality Data Analysis in Urban and Industrial AreaEditor IJRITCCNo ratings yet
- Air Population Components Estimation in Silk Board Bangalore, IndiaDocument7 pagesAir Population Components Estimation in Silk Board Bangalore, IndiaIJRASETPublicationsNo ratings yet
- Symmetry: Green Cloud Computing: A Literature SurveyDocument20 pagesSymmetry: Green Cloud Computing: A Literature SurveyNikitha AryaNo ratings yet
- Wen 2016Document15 pagesWen 2016VITA SARASINo ratings yet
- Qir Jurnal DitaDocument10 pagesQir Jurnal DitaditaNo ratings yet
- Estimation of Fuel Consumption: B. Tech Degree in Information TechnologyDocument15 pagesEstimation of Fuel Consumption: B. Tech Degree in Information TechnologyTanya SrivastavaNo ratings yet
- 05-A Comprehensive Approach To Evaluating CSC - IJSOM - Volume 10 - Issue 4 - Pages 545-563Document19 pages05-A Comprehensive Approach To Evaluating CSC - IJSOM - Volume 10 - Issue 4 - Pages 545-563tahir amirNo ratings yet
- Energies: Multivariate Features Extraction and Effective Decision Making Using Machine Learning ApproachesDocument16 pagesEnergies: Multivariate Features Extraction and Effective Decision Making Using Machine Learning ApproachesFares BencheikhNo ratings yet
- A Dual Model For Selecting Technology and Technology Transfer MethodDocument38 pagesA Dual Model For Selecting Technology and Technology Transfer MethodAli ZarifNo ratings yet
- Hybrid Prediction Model For The Interindustry Carbon Emissions Transfer Network Based On The Grey Model and General Vector MachineDocument12 pagesHybrid Prediction Model For The Interindustry Carbon Emissions Transfer Network Based On The Grey Model and General Vector MachinenhatvpNo ratings yet
- Experiences With LCA in The Nordic Building Industry - Challenges, Needs and SolutionsDocument9 pagesExperiences With LCA in The Nordic Building Industry - Challenges, Needs and SolutionsalfiansudibNo ratings yet
- (IJCST-V10I5P45) :mrs R Jhansi Rani, V Hari ChandanaDocument8 pages(IJCST-V10I5P45) :mrs R Jhansi Rani, V Hari ChandanaEighthSenseGroupNo ratings yet
- ADVANCED WEB DESIGN AND CONTENT MANAGEMENT ReportDocument42 pagesADVANCED WEB DESIGN AND CONTENT MANAGEMENT ReportMOHAMAD IZUDIN ABDUL RAHAMANNo ratings yet
- An Agent Based Traffic Regulation System For The Roadside Air Quality ControlDocument10 pagesAn Agent Based Traffic Regulation System For The Roadside Air Quality Controlakhil jumadeNo ratings yet
- Graphical User Interface Application in Matlab Environment For Water and Air Quality Process MonitoringDocument6 pagesGraphical User Interface Application in Matlab Environment For Water and Air Quality Process MonitoringLipQin YeoNo ratings yet
- Study On The Policy of Air Pollution Control in ChengduDocument9 pagesStudy On The Policy of Air Pollution Control in ChengduRoy WangintanNo ratings yet
- Electricity Price and Load Forecasting Using Data Analytics in Smart Grid: A SurveyDocument14 pagesElectricity Price and Load Forecasting Using Data Analytics in Smart Grid: A SurveyusmanNo ratings yet
- 1 s2.0 S1309104221002622 MainDocument13 pages1 s2.0 S1309104221002622 MainNoman Ali35No ratings yet
- A Markov Chain-Based IoT System For Monitoring and Analysis of Urban Air QualityDocument21 pagesA Markov Chain-Based IoT System For Monitoring and Analysis of Urban Air QualityBenito antonio martinezNo ratings yet
- Journal Pre-Proof: Microprocessors and MicrosystemsDocument29 pagesJournal Pre-Proof: Microprocessors and Microsystemsshanmuga prakashNo ratings yet
- Air Pollution Modelling With Deep Learning A ReviewDocument6 pagesAir Pollution Modelling With Deep Learning A ReviewliluNo ratings yet
- Air Quality Monitoring SystemDocument11 pagesAir Quality Monitoring Systemjayapriyathillaikumar217No ratings yet
- 1 s2.0 S095965262200614X MainDocument12 pages1 s2.0 S095965262200614X MainAhmadi AliNo ratings yet
- Ijaiem 2013 06 22 061Document10 pagesIjaiem 2013 06 22 061editorijaiemNo ratings yet
- Acr IjettDocument5 pagesAcr IjettAkhand BaghelNo ratings yet
- A Detailed Excursion On Machine Learning Approach, Algorithms and ApplicationsDocument8 pagesA Detailed Excursion On Machine Learning Approach, Algorithms and Applicationsviju001No ratings yet
- Journal Pone 0247330Document14 pagesJournal Pone 0247330viju001No ratings yet
- Big Data Analytics in Supply Chain Management: A Systematic Literature Review and Research DirectionsDocument29 pagesBig Data Analytics in Supply Chain Management: A Systematic Literature Review and Research Directionsviju001No ratings yet
- Silviu Risco ThesisDocument308 pagesSilviu Risco Thesisviju001No ratings yet
- Data Mining Analysis of The Parkinsons DiseaseDocument107 pagesData Mining Analysis of The Parkinsons Diseaseviju001No ratings yet
- Energy Efficiency Techniques in Cloud CoDocument7 pagesEnergy Efficiency Techniques in Cloud Coviju001No ratings yet
- Semi-Supervised Learning A Brief ReviewDocument6 pagesSemi-Supervised Learning A Brief ReviewReshma KhemchandaniNo ratings yet
- Jurisoo Tarkvaratehnika 2017Document45 pagesJurisoo Tarkvaratehnika 2017viju001No ratings yet
- LubnaAlhenaki Project4Document20 pagesLubnaAlhenaki Project4viju001No ratings yet
- Handling Missing Data Analysis of A Challenging Data Set Using Multiple ImputationDocument20 pagesHandling Missing Data Analysis of A Challenging Data Set Using Multiple Imputationviju001No ratings yet
- Using Using Using Using Using Using Using Using Using Namespace Public Partial ClassDocument14 pagesUsing Using Using Using Using Using Using Using Using Namespace Public Partial Classviju001No ratings yet
- Iot Based Biometric Attendance System Using ArduinoDocument108 pagesIot Based Biometric Attendance System Using Arduinoviju001No ratings yet
- Deep Recurrent Level Set For Segmenting Brain TumorsDocument8 pagesDeep Recurrent Level Set For Segmenting Brain Tumorsviju001No ratings yet
- Fingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya MishraDocument5 pagesFingerprint Segmentation Algorithms: A Literature Review: Rohan Nimkar Agya Mishraviju001No ratings yet
- State Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest CertificateDocument1 pageState Bank of India: To Whomsoever It May Concern Provisional Home Loan Interest Certificateviju001100% (1)
- Fingerprint Orientation Field Enhancement: April 2011Document9 pagesFingerprint Orientation Field Enhancement: April 2011viju001No ratings yet
- Biometric Fingerprint Student Attendance System: Software Requirement SpecificationsDocument19 pagesBiometric Fingerprint Student Attendance System: Software Requirement Specificationsviju001No ratings yet
- 10 - Chapter 1Document22 pages10 - Chapter 1viju001No ratings yet
- A New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita NathDocument5 pagesA New Adaptive Cuckoo Search Algorithm:, Maheshwari Rashmita Nathviju001No ratings yet
- 06 - Chapter 3Document36 pages06 - Chapter 3viju001No ratings yet
- Support Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball ClusteringDocument9 pagesSupport Vector Machine Classification For Large Data Sets Via Minimum Enclosing Ball Clusteringviju001No ratings yet
- Literature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle PrintDocument24 pagesLiterature Survey: 2.1 Fingerprint, Palmprint & Finger-Knuckle Printviju001No ratings yet
- 14 - Chapter 6Document7 pages14 - Chapter 6viju001No ratings yet
- 04 - Chapter 1Document19 pages04 - Chapter 1viju001No ratings yet
- Decision Making With Unknown Data: Development of ELECTRE Method Based On Black NumbersDocument16 pagesDecision Making With Unknown Data: Development of ELECTRE Method Based On Black Numbersviju001No ratings yet
- Fingerprint Enhancement Using Improved Orientation and Circular Gabor FilterDocument7 pagesFingerprint Enhancement Using Improved Orientation and Circular Gabor Filterviju001No ratings yet
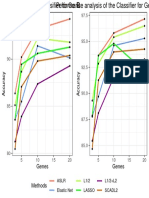
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Document1 pageGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001No ratings yet
- T.A. & D.A. BillDocument1 pageT.A. & D.A. Billviju001No ratings yet
- Programme Schedule - Webinar141020Document2 pagesProgramme Schedule - Webinar141020viju001No ratings yet
- Genes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2Document1 pageGenes Genes: Aslr Elastic Net L1/2 Lasso L1/2+L2 Scadl2viju001No ratings yet
- UE 2001 Section C ANSDocument15 pagesUE 2001 Section C ANSapi-19495519No ratings yet
- 12 Eng - Study MaterialDocument38 pages12 Eng - Study MaterialCarbonNo ratings yet
- Executive Regulations For Air QualityDocument86 pagesExecutive Regulations For Air QualityKashifPervez1No ratings yet
- Citizen Science Guide: IscapeDocument28 pagesCitizen Science Guide: IscapeBenito Perez GaldosNo ratings yet
- EC & CRZ Clearance For Great Nicobar Project - 11nov2022Document30 pagesEC & CRZ Clearance For Great Nicobar Project - 11nov2022DebiGoenkaCATNo ratings yet
- Scientific Compendium PDFDocument209 pagesScientific Compendium PDFJeremi PlazasNo ratings yet
- FINALSDocument32 pagesFINALSNathasha Marie BanalNo ratings yet
- Calibration of Air PollutionDocument3 pagesCalibration of Air PollutionECRDNo ratings yet
- Chapter 7Document134 pagesChapter 7raguchandra7527No ratings yet
- CREP GuidelinesDocument32 pagesCREP Guidelinesamol76No ratings yet
- Archer Daniels Midland: A Case Study in Corporate Welfare, Cato Policy AnalysisDocument27 pagesArcher Daniels Midland: A Case Study in Corporate Welfare, Cato Policy AnalysisCato InstituteNo ratings yet
- EWE 160 Air Pollution 1948 Donora SmogDocument11 pagesEWE 160 Air Pollution 1948 Donora SmogAlexander P. IgasanNo ratings yet
- SSRN Id3697395Document5 pagesSSRN Id3697395akttripathiNo ratings yet
- Air QualityDocument24 pagesAir QualityNiño Jhim AndrewNo ratings yet
- Mil PRF 24596b Amendment 1Document27 pagesMil PRF 24596b Amendment 1JFRD69No ratings yet
- PFPI Report To FTC On Biomass Power GreenwashingDocument55 pagesPFPI Report To FTC On Biomass Power Greenwashingpetersoe0No ratings yet
- Juvenal Manrique Cueto-2016133256Document4 pagesJuvenal Manrique Cueto-2016133256arahrojas33No ratings yet
- Three Way Catalytic ConvertersDocument12 pagesThree Way Catalytic ConvertersRahul sandireddyNo ratings yet
- Dr. Alison Simcox Low Cost Sensors LCS For Monitoring Air QualityDocument32 pagesDr. Alison Simcox Low Cost Sensors LCS For Monitoring Air QualityPaikama GuciNo ratings yet
- Certificat de Compétences en Langues de L'Enseignement Supérieur ClesDocument7 pagesCertificat de Compétences en Langues de L'Enseignement Supérieur ClesviiazNo ratings yet
- DD SF Fs F Fs F S F SF S F S Fs F S F S S FF SF SF F SF F Fs F F Fs Fs F F Fs Ffs Fs Fs Fs F F Fs Fs F F Sfs F SF F Fs F F S F Fs Fs FDDDocument20 pagesDD SF Fs F Fs F S F SF S F S Fs F S F S S FF SF SF F SF F Fs F F Fs Fs F F Fs Ffs Fs Fs Fs F F Fs Fs F F Sfs F SF F Fs F F S F Fs Fs FDDRabufetti QuintanaNo ratings yet
- Air Contaminants Benchmarks List 2018Document189 pagesAir Contaminants Benchmarks List 2018ibrahim syedNo ratings yet
- Piazzesi, PHD Thesis, ETH Zurich, 2006Document164 pagesPiazzesi, PHD Thesis, ETH Zurich, 2006Alfin AdiNo ratings yet
- Tod Working PaperDocument80 pagesTod Working PaperTedy MurtejoNo ratings yet
- CWTS REVIEWER Final 2Document19 pagesCWTS REVIEWER Final 2PoppyNo ratings yet