You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Extraordinary When One Looks at The Performance of The Broader Universe" As Well As WhenDocument9 pagesExtraordinary When One Looks at The Performance of The Broader Universe" As Well As Whenravi_405No ratings yet
- GSPL Delivers Robust Volumes; Tariff Hike LikelyDocument10 pagesGSPL Delivers Robust Volumes; Tariff Hike Likelyravi_405No ratings yet
- The Coffee Can PortfolioDocument5 pagesThe Coffee Can PortfolioVenkata Ramana PothulwarNo ratings yet
- Lessons Learnt From Security Analysis-100Document8 pagesLessons Learnt From Security Analysis-100ravi_405No ratings yet
- Cyclical and Non-Cyclical BusinessesDocument1 pageCyclical and Non-Cyclical Businessesravi_405No ratings yet
- Corporate Chanakya Successful Management The Chanakya WaysDocument60 pagesCorporate Chanakya Successful Management The Chanakya WaysRaza OshimNo ratings yet
- Loading Text Data to Oracle Table in ODI 12CDocument23 pagesLoading Text Data to Oracle Table in ODI 12Cravi_405No ratings yet
- Comparing DCA Versus Lumpsum Investing in S&P 500Document1 pageComparing DCA Versus Lumpsum Investing in S&P 500ravi_405No ratings yet
- Morgan Stanley - Lessons Learnt Over 20 Years of Quality InvestingDocument1 pageMorgan Stanley - Lessons Learnt Over 20 Years of Quality Investingravi_405No ratings yet
- Notes From RK-CCPDocument5 pagesNotes From RK-CCPravi_405No ratings yet
- KPMG Note On Canada Tax PlanningDocument21 pagesKPMG Note On Canada Tax Planningravi_405No ratings yet
- The Coffee Can PortfolioDocument5 pagesThe Coffee Can PortfolioVenkata Ramana PothulwarNo ratings yet
- Corporate Chanakya Successful Management The Chanakya WaysDocument60 pagesCorporate Chanakya Successful Management The Chanakya WaysRaza OshimNo ratings yet
- OBIA Finanicial Order Management & Supply Chain SchemasDocument32 pagesOBIA Finanicial Order Management & Supply Chain Schemasshivanagendra koyaNo ratings yet
- OBIA 7.9.6.4 - Configuration of DAC, Infa, OBIDocument30 pagesOBIA 7.9.6.4 - Configuration of DAC, Infa, OBIravi_405No ratings yet
- Mid-to-Mega Wealth Creation Strategies NotesDocument90 pagesMid-to-Mega Wealth Creation Strategies Notesravi_405No ratings yet
- Oracle BIApps 11g Customization Coding StandardDocument40 pagesOracle BIApps 11g Customization Coding Standardravi_405No ratings yet
- Mid-to-Mega Wealth Creation Strategies NotesDocument90 pagesMid-to-Mega Wealth Creation Strategies Notesravi_405No ratings yet
- Defining a Roadmap for Migrating to Oracle BI Applications on ODIDocument51 pagesDefining a Roadmap for Migrating to Oracle BI Applications on ODIsanaaNo ratings yet
- How To Create Users in Oracle BI (OBIEE) and WebLogic TutorialDocument9 pagesHow To Create Users in Oracle BI (OBIEE) and WebLogic Tutorialravi_405No ratings yet
- Oracle® Data Integrator: Getting Started With An ETL Project 10g Release 3 (10.1.3)Document64 pagesOracle® Data Integrator: Getting Started With An ETL Project 10g Release 3 (10.1.3)Mallikarjuna Rao ChNo ratings yet
- Differences in Terms Between Infa and ODIDocument2 pagesDifferences in Terms Between Infa and ODIravi_405No ratings yet
- VM ODI 12c Install GuideDocument17 pagesVM ODI 12c Install Guideravi_405No ratings yet
- Using Variables in ODI - The Timestamp ExampleDocument7 pagesUsing Variables in ODI - The Timestamp Exampleravi_405No ratings yet
- Oracle® Data Integrator: Getting Started With An ETL Project 10g Release 3 (10.1.3)Document64 pagesOracle® Data Integrator: Getting Started With An ETL Project 10g Release 3 (10.1.3)Mallikarjuna Rao ChNo ratings yet
- Exporting A Flat File To A RDBMS TableDocument27 pagesExporting A Flat File To A RDBMS Tableravi_405No ratings yet
- Using Variables in ODI - The Timestamp ExampleDocument7 pagesUsing Variables in ODI - The Timestamp Exampleravi_405No ratings yet
- Oracle® Data Integrator: Getting Started With An ETL Project 10g Release 3 (10.1.3)Document64 pagesOracle® Data Integrator: Getting Started With An ETL Project 10g Release 3 (10.1.3)Mallikarjuna Rao ChNo ratings yet
- Creating An ODI Procedure To Create and Populate RDBMS TableDocument20 pagesCreating An ODI Procedure To Create and Populate RDBMS Tableravi_4050% (1)
- Exporting A Flat File To A Flat FileDocument32 pagesExporting A Flat File To A Flat Fileravi_405No ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Wheat as an alternative to reduce corn feed costsDocument4 pagesWheat as an alternative to reduce corn feed costsYuariza Winanda IstyanNo ratings yet
- Bid Document PDFDocument125 pagesBid Document PDFAzharudin ZoechnyNo ratings yet
- Characteristics: Wheels Alloy Aluminium Magnesium Heat ConductionDocument4 pagesCharacteristics: Wheels Alloy Aluminium Magnesium Heat ConductionJv CruzeNo ratings yet
- Serras Tilted Arc Art and Non Art Senie in Art Journal 1989Document6 pagesSerras Tilted Arc Art and Non Art Senie in Art Journal 1989api-275667500No ratings yet
- Lecture7 PDFDocument5 pagesLecture7 PDFrashidNo ratings yet
- DSP Lab Record Convolution ExperimentsDocument25 pagesDSP Lab Record Convolution ExperimentsVishwanand ThombareNo ratings yet
- Final Biomechanics of Edentulous StateDocument114 pagesFinal Biomechanics of Edentulous StateSnigdha SahaNo ratings yet
- Organization Structure GuideDocument6 pagesOrganization Structure GuideJobeth BedayoNo ratings yet
- Sugar Milling Contract DisputeDocument3 pagesSugar Milling Contract DisputeRomy IanNo ratings yet
- S0231689H02-B01-0001 Rev 02 Code 1 General Arrangement Drawing For 44 Kva Diesel Generator PDFDocument6 pagesS0231689H02-B01-0001 Rev 02 Code 1 General Arrangement Drawing For 44 Kva Diesel Generator PDFAnonymous AfjzJdnNo ratings yet
- Responsibility Centres: Nature of Responsibility CentersDocument13 pagesResponsibility Centres: Nature of Responsibility Centersmahesh19689No ratings yet
- Tutorial Manual Safi PDFDocument53 pagesTutorial Manual Safi PDFrustamriyadiNo ratings yet
- Warranty Information Emea and CisDocument84 pagesWarranty Information Emea and CisHenriques BrunoNo ratings yet
- Denys Vuika - Electron Projects - Build Over 9 Cross-Platform Desktop Applications From Scratch-Packt Publishing (2019)Document429 pagesDenys Vuika - Electron Projects - Build Over 9 Cross-Platform Desktop Applications From Scratch-Packt Publishing (2019)Sarthak PrakashNo ratings yet
- Affordable Care Act Tax - Fact CheckDocument26 pagesAffordable Care Act Tax - Fact CheckNag HammadiNo ratings yet
- What Role Can IS Play in The Pharmaceutical Industry?Document4 pagesWhat Role Can IS Play in The Pharmaceutical Industry?Đức NguyễnNo ratings yet
- FOMRHI Quarterly: Ekna Dal CortivoDocument52 pagesFOMRHI Quarterly: Ekna Dal CortivoGaetano PreviteraNo ratings yet
- Embedded Systems: Martin Schoeberl Mschoebe@mail - Tuwien.ac - atDocument27 pagesEmbedded Systems: Martin Schoeberl Mschoebe@mail - Tuwien.ac - atDhirenKumarGoleyNo ratings yet
- The Punjab Commission On The Status of Women Act 2014 PDFDocument7 pagesThe Punjab Commission On The Status of Women Act 2014 PDFPhdf MultanNo ratings yet
- Continuous torque monitoring improves predictive maintenanceDocument13 pagesContinuous torque monitoring improves predictive maintenancemlouredocasadoNo ratings yet
- Guardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicDocument110 pagesGuardplc Certified Function Blocks - Basic Suite: Catalog Number 1753-CfbbasicTarun BharadwajNo ratings yet
- Borneo United Sawmills SDN BHD V Mui Continental Insurance Berhad (2006) 1 LNS 372Document6 pagesBorneo United Sawmills SDN BHD V Mui Continental Insurance Berhad (2006) 1 LNS 372Cheng LeongNo ratings yet
- Itec 3100 Student Response Lesson PlanDocument3 pagesItec 3100 Student Response Lesson Planapi-346174835No ratings yet
- Numark MixTrack Pro II Traktor ProDocument3 pagesNumark MixTrack Pro II Traktor ProSantiCai100% (1)
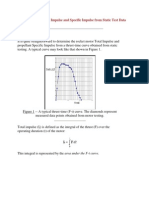
- Determining Total Impulse and Specific Impulse From Static Test DataDocument4 pagesDetermining Total Impulse and Specific Impulse From Static Test Datajai_selvaNo ratings yet
- Nammo Bulletin 2014Document13 pagesNammo Bulletin 2014Dmitry Karpov0% (1)
- Fact Sheet Rocket StovesDocument2 pagesFact Sheet Rocket StovesMorana100% (1)
- Method StatementDocument11 pagesMethod StatementMohammad Fazal Khan100% (1)
- Software Engineering Modern ApproachesDocument775 pagesSoftware Engineering Modern ApproachesErico Antonio TeixeiraNo ratings yet
- Pyramix V9.1 User Manual PDFDocument770 pagesPyramix V9.1 User Manual PDFhhyjNo ratings yet