78% found this document useful (9 votes)
13K views14 pagesB Simplex Method
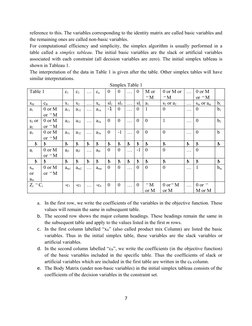
The document discusses the simplex method for solving linear programming problems. It explains that the simplex method provides a systematic algorithm for moving from one basic feasible solution to another in order to optimize the objective function. The simplex method involves preparing tables called simplex tables and moving between corner points, or basic feasible solutions, of the feasible region until an optimal solution is found. The document also defines several key terms related to the simplex method and linear programming problems.
Uploaded by
Utkarsh SethiCopyright
© Attribution Non-Commercial (BY-NC)
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOC, PDF, TXT or read online on Scribd
78% found this document useful (9 votes)
13K views14 pagesB Simplex Method
The document discusses the simplex method for solving linear programming problems. It explains that the simplex method provides a systematic algorithm for moving from one basic feasible solution to another in order to optimize the objective function. The simplex method involves preparing tables called simplex tables and moving between corner points, or basic feasible solutions, of the feasible region until an optimal solution is found. The document also defines several key terms related to the simplex method and linear programming problems.
Uploaded by
Utkarsh SethiCopyright
© Attribution Non-Commercial (BY-NC)
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOC, PDF, TXT or read online on Scribd
- (B) Simplex Method
- Constraints in LPP
- Definitions
- Redundant Constraints
- Standard Form of a LPP
- Charnes' Method for Surplus Variables
- Simplex Method Procedure
- Infeasibility vs Unboundedness