You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5811)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (844)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- 12 Business Studies Impq CH08 ControllingDocument9 pages12 Business Studies Impq CH08 ControllingdeepashajiNo ratings yet
- English MattersDocument1 pageEnglish MattersdeepashajiNo ratings yet
- 12 Business Studies Impq CH07 DirectingDocument9 pages12 Business Studies Impq CH07 DirectingdeepashajiNo ratings yet
- Police Injustice Responding Together To Chaengnge The StoryDocument4 pagesPolice Injustice Responding Together To Chaengnge The StorydeepashajiNo ratings yet
- Stanengding Rules&OrdersDocument130 pagesStanengding Rules&OrdersdeepashajiNo ratings yet
- 38432reading 4Document28 pages38432reading 4deepashajiNo ratings yet
- 170 Eng 10Document224 pages170 Eng 10deepashajiNo ratings yet
- Marking Scheme ScienceSubject XII 2010Document438 pagesMarking Scheme ScienceSubject XII 2010Ashish KumarNo ratings yet
- Commonlit Reading LiteratureDocument77 pagesCommonlit Reading LiteraturedeepashajiNo ratings yet
- Pages Froebom Police StoriesDocument17 pagesPages Froebom Police StoriesdeepashajiNo ratings yet
- NWMP Engfull PackageDocument38 pagesNWMP Engfull Packagedeepashaji100% (1)
- Parliamentary Procedure: Simplified Handbook ofDocument23 pagesParliamentary Procedure: Simplified Handbook ofdeepashajiNo ratings yet
- Parliamentarengy ProcedureDocument1 pageParliamentarengy ProceduredeepashajiNo ratings yet
- Parliamentary Procedures: Local Action GuideDocument2 pagesParliamentary Procedures: Local Action GuidedeepashajiNo ratings yet
- PSB Guidelinreadinges July2013Document25 pagesPSB Guidelinreadinges July2013deepashajiNo ratings yet
- Englishtagore The Home-ComingDocument5 pagesEnglishtagore The Home-ComingdeepashajiNo ratings yet
- Parliamentary Procedure - Quick Questions and Answers: T L C W S UDocument4 pagesParliamentary Procedure - Quick Questions and Answers: T L C W S UdeepashajiNo ratings yet
- Bonar Geotextiles Leaflet PDFDocument2 pagesBonar Geotextiles Leaflet PDFthadikkaranNo ratings yet
- Consulting - Specifying Engineer - NFPA 92 Defines Design, Testing of Smoke Control SystemsDocument11 pagesConsulting - Specifying Engineer - NFPA 92 Defines Design, Testing of Smoke Control SystemsHermi DavidNo ratings yet
- Team Bicol Endo For The Month of Dec.2019 With Col IdDocument37 pagesTeam Bicol Endo For The Month of Dec.2019 With Col IdJohn Albert AlejandrinoNo ratings yet
- Akai EA-A2 OwnersDocument0 pagesAkai EA-A2 OwnersBradfordGuyNo ratings yet
- Industry Sandbox Consultation Report FinalDocument68 pagesIndustry Sandbox Consultation Report FinalCrowdfundInsider100% (1)
- Historical Origins of NASA's Launch Operations Center To July 1, 1962Document322 pagesHistorical Origins of NASA's Launch Operations Center To July 1, 1962Bob Andrepont100% (2)
- Coal-Water Slurry Presentation2Document19 pagesCoal-Water Slurry Presentation2cumpio425428No ratings yet
- Analog Lab Cadence Procedure PDFDocument18 pagesAnalog Lab Cadence Procedure PDFKavyashreeMNo ratings yet
- Wave Energy Conversion Ocean Thermal Energy PDFDocument136 pagesWave Energy Conversion Ocean Thermal Energy PDFcio100% (1)
- Design DataDocument16 pagesDesign DataSaber Abdel MoreidNo ratings yet
- Fibre Policy Sub Groups Report Dir MG D 20100608 IDocument2 pagesFibre Policy Sub Groups Report Dir MG D 20100608 IVipul VarmaNo ratings yet
- Divisora de MasaDocument4 pagesDivisora de MasaNicolas Astudillo MaldonadoNo ratings yet
- Section 90 - Cab - Chapter 1Document16 pagesSection 90 - Cab - Chapter 1Esteban MunaresNo ratings yet
- MaterialDocument37 pagesMaterialSrelonyNo ratings yet
- Quotation CEMS (HG) - CO2 - SISPEK - PT Tenaga Listrik Bengkulu (1269)Document2 pagesQuotation CEMS (HG) - CO2 - SISPEK - PT Tenaga Listrik Bengkulu (1269)Muhamad JemadiNo ratings yet
- Logistics - Section - 09 - Transportation (Updated)Document20 pagesLogistics - Section - 09 - Transportation (Updated)Tôn Nữ Minh UyênNo ratings yet
- Structure Repairs & Rehabilitation Presentation No.3Document98 pagesStructure Repairs & Rehabilitation Presentation No.3Sougata DasNo ratings yet
- Piezoelectric Transducers: Advantages of The Piezoelectric TransducerDocument2 pagesPiezoelectric Transducers: Advantages of The Piezoelectric TransducerAlan ContrerasNo ratings yet
- Computer Aided Quality ControlDocument17 pagesComputer Aided Quality ControlMFNo ratings yet
- Technological Institute of The Philippines: Impedance Matching Using Smith ChartDocument8 pagesTechnological Institute of The Philippines: Impedance Matching Using Smith ChartHikaru HitachiinNo ratings yet
- Differance Between ELCB and RCCB?: Answer:For Lighting Loads, Neutral Conductor Is Must and Hence The SecondaryDocument3 pagesDifferance Between ELCB and RCCB?: Answer:For Lighting Loads, Neutral Conductor Is Must and Hence The SecondaryBeere GangadharNo ratings yet
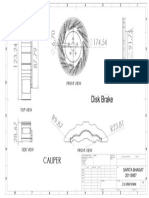
- 2a Disc BrakeDocument1 page2a Disc BrakeSarita BhagatNo ratings yet
- About UsDocument35 pagesAbout Us9897856218No ratings yet
- Dumagat Ecolodge (Architecture) CritiqueDocument4 pagesDumagat Ecolodge (Architecture) CritiquePatreze AberillaNo ratings yet
- Service Manual: Kodak Dryview 8150 Laser ImagerDocument470 pagesService Manual: Kodak Dryview 8150 Laser ImagerTausif AliNo ratings yet
- Memo 097.7 - 121119 - Item 403 Metal Structures (Revised Pay Item Subscripts)Document2 pagesMemo 097.7 - 121119 - Item 403 Metal Structures (Revised Pay Item Subscripts)Bai Alleha MusaNo ratings yet
- Vert Heater TreaterDocument2 pagesVert Heater TreaterJaveed KhanNo ratings yet
- N10EKS CSVDocument8 pagesN10EKS CSVYosca YolantaNo ratings yet
- Presentation On Photonics CommunicationDocument14 pagesPresentation On Photonics CommunicationKavithaNo ratings yet
- Workpaper GuidelinesDocument4 pagesWorkpaper GuidelinesAltynay IlyassovaNo ratings yet