100% found this document useful (2 votes)
21K views12 pagesKey Statistical Formulas Explained
This document discusses statistical formulas used to represent common statistical parameters and statistics. It provides the formulas for population mean (μ), population standard deviation (σ), population variance (σ2), sample mean ( ), sample standard deviation (s), variance of the sample proportion (sp2), and pooled sample standard deviation (sp). It also defines key terms used in the formulas like population, sample, sum, and size.
Uploaded by
ckkc09Copyright
© Attribution Non-Commercial (BY-NC)
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOC, PDF, TXT or read online on Scribd
100% found this document useful (2 votes)
21K views12 pagesKey Statistical Formulas Explained
This document discusses statistical formulas used to represent common statistical parameters and statistics. It provides the formulas for population mean (μ), population standard deviation (σ), population variance (σ2), sample mean ( ), sample standard deviation (s), variance of the sample proportion (sp2), and pooled sample standard deviation (sp). It also defines key terms used in the formulas like population, sample, sum, and size.
Uploaded by
ckkc09Copyright
© Attribution Non-Commercial (BY-NC)
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOC, PDF, TXT or read online on Scribd
- Statistical Formula Introduction
- Commonly Used Statistical Formulas
- Basic Statistical Formulas
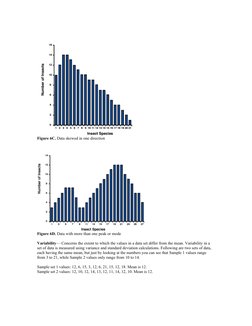
- Variance and Standard Deviation
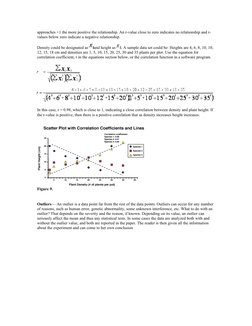
- ANOVA and Correlation
- Ecological Equations and Probability