You might also like
- O Level Additional Maths Notes PDFDocument8 pagesO Level Additional Maths Notes PDFDavid Ardiansyah100% (1)
- Principles of Cost Accounting 17th EditionDocument61 pagesPrinciples of Cost Accounting 17th Editiondarren.barnett949100% (45)
- Individual Differences Student PortfolioDocument9 pagesIndividual Differences Student Portfolioapi-242587194No ratings yet
- K Means ExampleDocument10 pagesK Means ExampleDaljit SinghNo ratings yet
- K-Means Clustering Example ExplainedDocument8 pagesK-Means Clustering Example ExplainedAdithya RamnathNo ratings yet
- K Means TutorialDocument8 pagesK Means TutorialhhhNo ratings yet
- Lecture - Notes MAtrix Algebra 2Document99 pagesLecture - Notes MAtrix Algebra 2BrunéNo ratings yet
- CMA-ES With MATLAB CodeDocument30 pagesCMA-ES With MATLAB CodeReveloApraezCesarNo ratings yet
- Pattern Recognition and Machine Learning Techniques (Fuzzy SetsDocument15 pagesPattern Recognition and Machine Learning Techniques (Fuzzy SetsAvishek ChandraNo ratings yet
- MatrixDocument37 pagesMatrixMohit ChawlaNo ratings yet
- Unsupervised Learning & ClusteringDocument102 pagesUnsupervised Learning & ClusteringCarlos Niger DiazNo ratings yet
- F?L Yl : 9.55 Region Growing by MergingDocument10 pagesF?L Yl : 9.55 Region Growing by MergingManu ManuNo ratings yet
- Linear Algebra Review and Reference: Zico Kolter (Updated by Chuong Do and Tengyu Ma) June 20, 2020Document29 pagesLinear Algebra Review and Reference: Zico Kolter (Updated by Chuong Do and Tengyu Ma) June 20, 2020sid sNo ratings yet
- Matrix Algebra GuideDocument15 pagesMatrix Algebra GuideRafael Ramon VBNo ratings yet
- Eigenvalue Problems and Quadratic Forms: Engineering Mathematics By: Engr. Angelo RamosDocument36 pagesEigenvalue Problems and Quadratic Forms: Engineering Mathematics By: Engr. Angelo RamosAngelo RamosNo ratings yet
- GamabetaDocument14 pagesGamabetaD-497 Neha MalviyaNo ratings yet
- Estimating Output Variance of A Regressing Tree Model: Case Study of Concrete Strength PredictionDocument16 pagesEstimating Output Variance of A Regressing Tree Model: Case Study of Concrete Strength PredictionMonjurul HasanNo ratings yet
- Describing The Problem With Background Knowledge. 2. Design of Object Recognition Algorithm Based On Support Vector MachineDocument2 pagesDescribing The Problem With Background Knowledge. 2. Design of Object Recognition Algorithm Based On Support Vector MachineHasib haqueNo ratings yet
- 26 Matrix FactorizationDocument20 pages26 Matrix FactorizationONCE ThaqiefNo ratings yet
- 8 Jan2015Document53 pages8 Jan2015정하윤No ratings yet
- Finding Eigenvalues and EigenvectorsDocument33 pagesFinding Eigenvalues and EigenvectorsGayatriramanaNo ratings yet
- Class IIIDocument17 pagesClass IIIBhagirath PrajapatiNo ratings yet
- Tcu11 08 08-1Document12 pagesTcu11 08 08-1moquddes akramNo ratings yet
- Linear AlgebraDocument28 pagesLinear AlgebraLuthfan AdeNo ratings yet
- Linear Algebra Review and Reference: Zico Kolter (Updated by Chuong Do and Tengyu Ma) April 3, 2019Document28 pagesLinear Algebra Review and Reference: Zico Kolter (Updated by Chuong Do and Tengyu Ma) April 3, 2019Name TATANo ratings yet
- Linearna Algebra 2Document14 pagesLinearna Algebra 2rankoman0% (1)
- Dense NetDocument28 pagesDense NetFahad RazaNo ratings yet
- The Householder Transformation in Numerical Linear Algebra: John Kerl February 3, 2008Document21 pagesThe Householder Transformation in Numerical Linear Algebra: John Kerl February 3, 2008elan4scribdNo ratings yet
- Linear Algebra Primer Breaks Down Key ConceptsDocument15 pagesLinear Algebra Primer Breaks Down Key ConceptsMario PioNo ratings yet
- HKU MATH1853 - Brief Linear Algebra Notes: 1 Eigenvalues and EigenvectorsDocument6 pagesHKU MATH1853 - Brief Linear Algebra Notes: 1 Eigenvalues and EigenvectorsfirelumiaNo ratings yet
- Ch01 DeterminantDocument27 pagesCh01 DeterminantDharma AdyanNo ratings yet
- Mat435 Chapter 1 Trigonometric IntegralsDocument6 pagesMat435 Chapter 1 Trigonometric IntegralsNabil MahadzirNo ratings yet
- Lattin Et Al - Analyzing Multivariate Data - 279-281Document3 pagesLattin Et Al - Analyzing Multivariate Data - 279-281vigneshNo ratings yet
- HELM Workbook 22 Eigenvalues and EigenvectorsDocument53 pagesHELM Workbook 22 Eigenvalues and Eigenvectorsbilbis4321No ratings yet
- Hitungan Struktur Perancah Sistem ShorringDocument36 pagesHitungan Struktur Perancah Sistem Shorringkertas biruNo ratings yet
- Image Filtering in Spatial DomainDocument36 pagesImage Filtering in Spatial DomainRafiq MuzakkiNo ratings yet
- TH Differential Calculus Solution PDFDocument4 pagesTH Differential Calculus Solution PDFEdwin Quinlat DevizaNo ratings yet
- Fpractice4 Sols 02Document2 pagesFpractice4 Sols 02Claire WuNo ratings yet
- Random Forests: N 1 N J X A I X A IDocument12 pagesRandom Forests: N 1 N J X A I X A IendaleNo ratings yet
- Unit 7 Review WS 2013Document3 pagesUnit 7 Review WS 2013scribida42No ratings yet
- Nabil 201 Chap 07Document39 pagesNabil 201 Chap 07dasjyotiska2005No ratings yet
- Unit 7 Review WS 2013Document3 pagesUnit 7 Review WS 2013scribida42No ratings yet
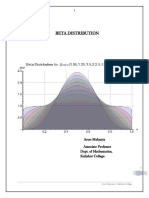
- Mathematical Excursion To Beta Distribution PDFDocument20 pagesMathematical Excursion To Beta Distribution PDFsekarganesanNo ratings yet
- Neural Networks Unit - 8 Perceptrons Objective: An Objective of The Unit-8 Is, The Reader Should Be Able To Know What Do YouDocument13 pagesNeural Networks Unit - 8 Perceptrons Objective: An Objective of The Unit-8 Is, The Reader Should Be Able To Know What Do YouMohan AgrawalNo ratings yet
- 5-SpatialFiltering 2Document74 pages5-SpatialFiltering 2pham tamNo ratings yet
- Eigen Symmetric 3 X 3Document21 pagesEigen Symmetric 3 X 3Igor GjorgjievNo ratings yet
- Matrices and Matrix Algebra Course OverviewDocument28 pagesMatrices and Matrix Algebra Course OverviewVimala ElumalaiNo ratings yet
- Limits,ContinuityDocument5 pagesLimits,ContinuityVedika ShahNo ratings yet
- Vector Geometry AnnotatedDocument93 pagesVector Geometry Annotatedkentoks 69No ratings yet
- Chap 2 Computational MethodDocument26 pagesChap 2 Computational MethodUmair Ali RajputNo ratings yet
- MIT2 086F14 Monte CarloDocument15 pagesMIT2 086F14 Monte Carloমে হে দীNo ratings yet
- Dynamic Analysis Using FeaDocument114 pagesDynamic Analysis Using FeaDr P Ravinder ReddyNo ratings yet
- 4 Eigenvalues and Eigenvectors PDFDocument108 pages4 Eigenvalues and Eigenvectors PDFLam LamNo ratings yet
- What Is Matlab?: Introduction To Matlab ProgrammingDocument7 pagesWhat Is Matlab?: Introduction To Matlab ProgrammingJggNo ratings yet
- 02 K-MeansDocument25 pages02 K-MeansKushagra BhatnagarNo ratings yet
- Introduction To Matlab: Luke DickensDocument41 pagesIntroduction To Matlab: Luke DickensTranjay ChandelNo ratings yet
- ScientificComputing HW2Document2 pagesScientificComputing HW2arashnasr79No ratings yet
- On the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)From EverandOn the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)No ratings yet
- Sample Items From The Multifactor Leadership Questionnaire (MLQ) Form 5X-ShortDocument1 pageSample Items From The Multifactor Leadership Questionnaire (MLQ) Form 5X-ShortMutia Kusuma DewiNo ratings yet
- Final Result IES ISS 2015 EnglishDocument3 pagesFinal Result IES ISS 2015 Englishismav169No ratings yet
- IELTS Liz - IELTS Preparation - Free Tips, Lessons - EnglishDocument2 pagesIELTS Liz - IELTS Preparation - Free Tips, Lessons - EnglishviyimahNo ratings yet
- Lesson 3 PR 1Document11 pagesLesson 3 PR 1Clarenz Ken TatierraNo ratings yet
- Establishing Strategic PayDocument17 pagesEstablishing Strategic PayRain StarNo ratings yet
- Non Graded Activity - AssignmentDocument2 pagesNon Graded Activity - AssignmentWany WanyNo ratings yet
- DR B.shyamala MD PHD Kerala Web BlogDocument31 pagesDR B.shyamala MD PHD Kerala Web Blogsamuel dameraNo ratings yet
- Employment Transition of Fresh Business Graduates An AssessmentDocument49 pagesEmployment Transition of Fresh Business Graduates An AssessmentCyan Vincent CanlasNo ratings yet
- OS X Lion Artifacts v1.0Document39 pagesOS X Lion Artifacts v1.0opexxxNo ratings yet
- BRP Akpsi 2022Document17 pagesBRP Akpsi 2022dhill fNo ratings yet
- Creating COM+ ApplicationsDocument7 pagesCreating COM+ ApplicationsAdalberto Reyes ValenzuelaNo ratings yet
- Q1 FOP MODULE G10 FinalDocument42 pagesQ1 FOP MODULE G10 FinalJhennyvy TorrenNo ratings yet
- The Importance of Drama in Primary EducationDocument2 pagesThe Importance of Drama in Primary EducationMichael Prants100% (5)
- Resume UpdatedDocument6 pagesResume UpdatedBryan Romena EvangelistaNo ratings yet
- Major Project: Front Page, Certificate & Acknowledgement FormatDocument3 pagesMajor Project: Front Page, Certificate & Acknowledgement FormatSantosh Kumar50% (20)
- 11 Socio Cultural (Chap. 7)Document22 pages11 Socio Cultural (Chap. 7)Meridian Ela100% (1)
- ReferencesDocument5 pagesReferencesAshar HidayatNo ratings yet
- Ar1 - A4 Standee PantaleonDocument1 pageAr1 - A4 Standee PantaleonNestor PantaleonNo ratings yet
- Change ManagementDocument15 pagesChange ManagementsaieeshgNo ratings yet
- Planilha Classificação Qualis 2017-2018 - TabelaDocument460 pagesPlanilha Classificação Qualis 2017-2018 - TabelaThiago EtcNo ratings yet
- Art Is An Expression of LifeDocument1 pageArt Is An Expression of LifeGintokiNo ratings yet
- B.tech. IT Curriculam For All 4 YearsDocument244 pagesB.tech. IT Curriculam For All 4 YearsRaghavNo ratings yet
- Report On Performance Management System at InfosysDocument12 pagesReport On Performance Management System at InfosysDiksha Singla100% (2)
- New Fashion Designers Sketchbooks (Zarida Zaman) (Z-Library)Document162 pagesNew Fashion Designers Sketchbooks (Zarida Zaman) (Z-Library)Carolina VieirNo ratings yet
- Philippine Constitution provisions on educationDocument2 pagesPhilippine Constitution provisions on educationLouise salesNo ratings yet
- Syllabus Students PoliticsDocument2 pagesSyllabus Students PoliticsJerald Jay Capistrano CatacutanNo ratings yet
- Informative Outline SPCDocument2 pagesInformative Outline SPCAnonymous madidqNo ratings yet