You might also like
- Preliminary Concepts On Statistical InferenceDocument39 pagesPreliminary Concepts On Statistical InferenceMhaj Capio100% (1)
- Module 004 - Parametric and Non-ParametricDocument12 pagesModule 004 - Parametric and Non-ParametricIlovedocumintNo ratings yet
- COMPRE STATISTICS Sample Q.Document2 pagesCOMPRE STATISTICS Sample Q.Mary Antonette DeitaNo ratings yet
- Data Analysis Final RequierementsDocument11 pagesData Analysis Final RequierementsJane MahidlawonNo ratings yet
- Para and Non-ParaDocument4 pagesPara and Non-ParaAldye XNo ratings yet
- Allama Iqbal Open University Islamabad: Muhammad AshrafDocument25 pagesAllama Iqbal Open University Islamabad: Muhammad AshrafHafiz M MudassirNo ratings yet
- StatisticsDocument50 pagesStatisticsAGEY KAFUI HANSELNo ratings yet
- Inferential Statistics For Data ScienceDocument10 pagesInferential Statistics For Data Sciencersaranms100% (1)
- Inferential StatisticsDocument6 pagesInferential StatisticsRomdy LictaoNo ratings yet
- DBA-5102 Statistics - For - Management AssignmentDocument12 pagesDBA-5102 Statistics - For - Management AssignmentPrasanth K SNo ratings yet
- Power and Sample Size DeterminationDocument27 pagesPower and Sample Size DeterminationArockia SamyNo ratings yet
- Name: Hasnain Shahnawaz REG#: 1811265 Class: Bba-5B Subject: Statistical Inferance Assignment 1 To 10Document38 pagesName: Hasnain Shahnawaz REG#: 1811265 Class: Bba-5B Subject: Statistical Inferance Assignment 1 To 10kazi ibiiNo ratings yet
- Academic Research UWDocument28 pagesAcademic Research UWKishor BhanushliNo ratings yet
- Standard Error in StatisticsDocument2 pagesStandard Error in Statisticsdsubhajyoti28No ratings yet
- Marshall Jonker Inferent Stats 2010Document12 pagesMarshall Jonker Inferent Stats 2010Kenny BayudanNo ratings yet
- Analysis of VarianceDocument5 pagesAnalysis of VarianceMIKINo ratings yet
- Research Methodology - Parametric and Non-Parametric TestsDocument7 pagesResearch Methodology - Parametric and Non-Parametric TestsDerrick TheophilusNo ratings yet
- Haramaya University Water Resources ProgramDocument11 pagesHaramaya University Water Resources ProgramhabtamuNo ratings yet
- Business StatisticsDocument20 pagesBusiness StatisticsdmomsdNo ratings yet
- Parametric and Non Parametric TestsDocument4 pagesParametric and Non Parametric TestsZubaria KhanamNo ratings yet
- Data Collection: SamplingDocument8 pagesData Collection: SamplingskyNo ratings yet
- SEM & Confidence IntervalDocument39 pagesSEM & Confidence IntervalAnitha NoronhaNo ratings yet
- Final Assignment On StatsDocument36 pagesFinal Assignment On StatsRahul GuptaNo ratings yet
- "Minhaj University Lahore": Inferential StatisticsDocument6 pages"Minhaj University Lahore": Inferential StatisticsMuhammad MadniNo ratings yet
- Educational Statistics Inferential StatisticsDocument19 pagesEducational Statistics Inferential StatisticsAqsa RaniNo ratings yet
- Exploratory Factor Analysis: Understanding the Underlying Structure in DataDocument35 pagesExploratory Factor Analysis: Understanding the Underlying Structure in DataAlia Al Zghoul100% (1)
- Course: Educational Statistics (8614) Semester: Spring, 2023 Assignment-02Document19 pagesCourse: Educational Statistics (8614) Semester: Spring, 2023 Assignment-02abdul ghaffarNo ratings yet
- Hypothesis Testing Parametric and Non Parametric TestsDocument14 pagesHypothesis Testing Parametric and Non Parametric Testsreeya chhetriNo ratings yet
- 13 Statistical Analysis Methods for Data Analysts & Data Scientists _ by btd _ MediumDocument22 pages13 Statistical Analysis Methods for Data Analysts & Data Scientists _ by btd _ Mediumravinder.ds7865No ratings yet
- Summary of Module 4Document10 pagesSummary of Module 4marc jhayron taganasNo ratings yet
- Unit 1Document9 pagesUnit 1Saral ManeNo ratings yet
- Unit 1Document9 pagesUnit 1Saral ManeNo ratings yet
- Statistical TermsDocument11 pagesStatistical TermsSanath NairNo ratings yet
- Research Methods: PH.D in NursingDocument63 pagesResearch Methods: PH.D in NursingsusilaNo ratings yet
- Multivariate AnalysisDocument11 pagesMultivariate AnalysisCerlin PajilaNo ratings yet
- BRM Unit 4 ExtraDocument10 pagesBRM Unit 4 Extraprem nathNo ratings yet
- 12 - Parametric and Non-Parametric TestDocument2 pages12 - Parametric and Non-Parametric TestALVI ANANDA PUTRINo ratings yet
- Sampling DistributionDocument7 pagesSampling DistributionSunil Kumar Hg HgNo ratings yet
- 8614 - Assignment 2 Solved (AG)Document19 pages8614 - Assignment 2 Solved (AG)Maria GillaniNo ratings yet
- Select Statistical Techniques AppropriatelyDocument1 pageSelect Statistical Techniques AppropriatelyArtemisNo ratings yet
- Statistical Concepts You Need For Life After This Course Is OverDocument3 pagesStatistical Concepts You Need For Life After This Course Is OverMichael WelkerNo ratings yet
- Statistical analysis conclusions interpretationDocument3 pagesStatistical analysis conclusions interpretationErrol de los SantosNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OMakmur SejatiNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OOK ViewNo ratings yet
- Abs Unit3Document14 pagesAbs Unit3lav RathoreNo ratings yet
- BY: Anupama 092 IshaDocument32 pagesBY: Anupama 092 IshaPriyanka ZalpuriNo ratings yet
- Business Research Tools and VariablesDocument15 pagesBusiness Research Tools and VariablessarathNo ratings yet
- Basics of Testing HypothesisDocument25 pagesBasics of Testing HypothesisHiba MohammedNo ratings yet
- Chapter 3 AngelineDocument5 pagesChapter 3 AngelineAngelo CompahinayNo ratings yet
- Six Sigma Mission: Statistical Sample Population ParameterDocument4 pagesSix Sigma Mission: Statistical Sample Population ParameterFaheem HussainNo ratings yet
- Angela Verano MC MATH 15 Module 2Document11 pagesAngela Verano MC MATH 15 Module 2AN GE LANo ratings yet
- Parametric Test and NonDocument9 pagesParametric Test and Nonshellem salazaarNo ratings yet
- Be A 65 Ads Exp 4Document17 pagesBe A 65 Ads Exp 4Ritika dwivediNo ratings yet
- Parametric TestDocument6 pagesParametric Testshellem salazaarNo ratings yet
- GFK K.pusczak-Sample Size in Customer Surveys - PaperDocument27 pagesGFK K.pusczak-Sample Size in Customer Surveys - PaperVAlentino AUrishNo ratings yet
- Name Roll No Learning Centre Subject Assignment No Date of Submission at The Learning CentreDocument11 pagesName Roll No Learning Centre Subject Assignment No Date of Submission at The Learning CentreVikash AgrawalNo ratings yet
- Experiment 1Document4 pagesExperiment 1Charls DeimoyNo ratings yet
- ANOVA AND T-TESTS EXPLAINEDDocument29 pagesANOVA AND T-TESTS EXPLAINEDmounika kNo ratings yet
- Overview Of Bayesian Approach To Statistical Methods: SoftwareFrom EverandOverview Of Bayesian Approach To Statistical Methods: SoftwareNo ratings yet
- 7cpc OptionformDocument1 page7cpc Optionformsyam227793No ratings yet
- Timahhi WordDocument2 pagesTimahhi Wordromesh10008No ratings yet
- ComputerProcessing PDFDocument9 pagesComputerProcessing PDFromesh10008No ratings yet
- Chetan Bhagat - Three Mistakes of My LifeDocument144 pagesChetan Bhagat - Three Mistakes of My LifeGayathri ParthasarathyNo ratings yet
- List of Publications-Sudhirsharma - 30816 PDFDocument8 pagesList of Publications-Sudhirsharma - 30816 PDFromesh10008No ratings yet
- Employee allocation optionsDocument5 pagesEmployee allocation optionsromesh10008No ratings yet
- Advt - IIT Jammu - 01 - 2020 - (Direct Rectt.)Document22 pagesAdvt - IIT Jammu - 01 - 2020 - (Direct Rectt.)RohitNo ratings yet
- 1 PDFDocument48 pages1 PDFclass with rupeshNo ratings yet
- CAE Brochure Final PDFDocument4 pagesCAE Brochure Final PDFromesh10008No ratings yet
- RBI Bank RatesDocument1 pageRBI Bank Ratesromesh10008No ratings yet
- UPSC Recruitment for Examiner, Professor PostsDocument51 pagesUPSC Recruitment for Examiner, Professor PostsRaj MNo ratings yet
- Savitribai Phule Pune University PDFDocument24 pagesSavitribai Phule Pune University PDFromesh10008No ratings yet
- Rti Fellowship Report 2011 PDFDocument257 pagesRti Fellowship Report 2011 PDFromesh10008No ratings yet
- Application Form For LibrarianDocument12 pagesApplication Form For Librarianromesh10008No ratings yet
- ThoughtsDocument364 pagesThoughtssangeshnnNo ratings yet
- RBI Bank RatesDocument1 pageRBI Bank Ratesromesh10008No ratings yet
- Ancient Indian Wisdom For ManagersDocument24 pagesAncient Indian Wisdom For ManagersanupamrcNo ratings yet
- Label Batch 202Document2 pagesLabel Batch 202romesh10008No ratings yet
- Label Batch 254Document2 pagesLabel Batch 254romesh10008No ratings yet
- Indo Russian Relation in 21St Century PDFDocument8 pagesIndo Russian Relation in 21St Century PDFromesh10008No ratings yet
- j.2040-0209.2011.00362 2.xDocument33 pagesj.2040-0209.2011.00362 2.xromesh10008No ratings yet
- Public Notice DraftUGCRegulationsDocument1 pagePublic Notice DraftUGCRegulationsromesh10008No ratings yet
- Label Batch 207Document3 pagesLabel Batch 207romesh10008No ratings yet
- 27 - India's Relations With USA and Russia (87 KB)Document9 pages27 - India's Relations With USA and Russia (87 KB)Tabish BeighNo ratings yet
- Gst-Form ST-6Document2 pagesGst-Form ST-6romesh10008No ratings yet
- SrI RAmAnuja Dharsanam - 2013-08-09 - Vijaya-Adi - HindiDocument25 pagesSrI RAmAnuja Dharsanam - 2013-08-09 - Vijaya-Adi - Hindiromesh10008No ratings yet
- Result of Higher Secondary Part Two, Bi-Annual 2017 (Private) - Jammu (Summer Zone) - JKBOSEDocument1 pageResult of Higher Secondary Part Two, Bi-Annual 2017 (Private) - Jammu (Summer Zone) - JKBOSEromesh10008No ratings yet
- ThirumalaiAnanthalwan ABiographyDocument60 pagesThirumalaiAnanthalwan ABiographyromesh10008No ratings yet
- Dishtv 01522422287190920160206060118Document1 pageDishtv 01522422287190920160206060118romesh10008No ratings yet
- Arthaśāstra: Ancient India's Rule Book On Politics, War, Governance and LifestyleDocument306 pagesArthaśāstra: Ancient India's Rule Book On Politics, War, Governance and Lifestyleashgene100% (4)
- Application for Lecturer StatusDocument7 pagesApplication for Lecturer StatusSIVA KRISHNA PRASAD ARJANo ratings yet
- JAC Result 2018, Jharkhand Board Result 2018, JAC Matric Result 2018Document3 pagesJAC Result 2018, Jharkhand Board Result 2018, JAC Matric Result 2018Exam Results0% (1)
- Summary of PhilosophyDocument4 pagesSummary of PhilosophyRaihan Alisha NabilaNo ratings yet
- Tips For A Successful Job InterviewDocument9 pagesTips For A Successful Job InterviewRoshinne Lea Ang BialaNo ratings yet
- k-3 Literacy Essentials 3 2016Document6 pagesk-3 Literacy Essentials 3 2016api-255453365No ratings yet
- Teaching of English in Indian Higher Education ClassroomsDocument12 pagesTeaching of English in Indian Higher Education ClassroomsNihalSoni100% (2)
- Biology - Course Syllabus - Valencia High School Mr. KlingerDocument3 pagesBiology - Course Syllabus - Valencia High School Mr. KlingerMathews MwambaNo ratings yet
- Department of Education: Republic of The PhilippinesDocument2 pagesDepartment of Education: Republic of The PhilippinesjoanNo ratings yet
- Cambridge International General Certificate of Education Gce Examinations in NepalDocument5 pagesCambridge International General Certificate of Education Gce Examinations in NepalArun GhatanNo ratings yet
- Private Tuition Culture in IndiaDocument7 pagesPrivate Tuition Culture in IndiaWicked WizrdNo ratings yet
- Consumer Behaviour SyllabusDocument2 pagesConsumer Behaviour SyllabusBalachandar Kaliappan100% (2)
- Practicing Teaching English Writing T6askDocument34 pagesPracticing Teaching English Writing T6askAlia Mujtaba100% (1)
- Writing CBMDocument2 pagesWriting CBMEliotAshNo ratings yet
- Ece Ojt Narrative Report Summer 2014Document3 pagesEce Ojt Narrative Report Summer 2014Eunice Jane Bolgado-Doctor100% (4)
- Anita Biedrzycki-Radiography Procedure and Competency Manual, 2nd Ed 2008Document540 pagesAnita Biedrzycki-Radiography Procedure and Competency Manual, 2nd Ed 2008pepsimax85100% (1)
- Standard Guidelines for Practicum ReportsDocument15 pagesStandard Guidelines for Practicum ReportsmaziahesaNo ratings yet
- Students in High-Achieving Neighborhoods Who Spend Too Much Time On Homework Have More Health Problems, Stress, and Alienation From SocietyDocument3 pagesStudents in High-Achieving Neighborhoods Who Spend Too Much Time On Homework Have More Health Problems, Stress, and Alienation From Societyryan eNo ratings yet
- MSc Clinical Epidemiology at Stellenbosch UniversityDocument24 pagesMSc Clinical Epidemiology at Stellenbosch UniversityNeo Mervyn MonahengNo ratings yet
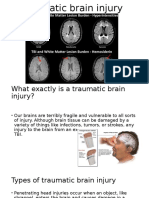
- Traumatic Brain InjuryDocument11 pagesTraumatic Brain Injuryapi-341401878No ratings yet
- Klaryse Dam - Essay On The Foundation of Teaching and LearningDocument12 pagesKlaryse Dam - Essay On The Foundation of Teaching and Learningapi-505539908No ratings yet
- Edsc 502 H GoalsDocument2 pagesEdsc 502 H GoalsAlexandra BarlowNo ratings yet
- Listening RPHDocument3 pagesListening RPHSharkirin NazianNo ratings yet
- Final Practicum Report Andersen Casey Year 5 Bed May 2020Document4 pagesFinal Practicum Report Andersen Casey Year 5 Bed May 2020api-511866902No ratings yet
- Ibps So MarketDocument2 pagesIbps So MarketDrRam Singh KambojNo ratings yet
- Tution Fee FixationDocument22 pagesTution Fee FixationThomas ThachilNo ratings yet
- IB DP TOK SyllabusDocument6 pagesIB DP TOK SyllabusLuis G. MoraNo ratings yet
- Pedagogy AccomplishmentDocument3 pagesPedagogy AccomplishmentZacky CanthelayoungNo ratings yet
- Peer Support Training ManualDocument192 pagesPeer Support Training ManualSharon A Stocker100% (2)
- Reflective Analysis of Portfolio Artifact ST 4Document1 pageReflective Analysis of Portfolio Artifact ST 4api-250867686No ratings yet
- Examples of CybercultureDocument2 pagesExamples of CybercultureDaniie BeltránNo ratings yet