You might also like
- Learn Statistics Fast: A Simplified Detailed Version for StudentsFrom EverandLearn Statistics Fast: A Simplified Detailed Version for StudentsNo ratings yet
- Micecx 3Document35 pagesMicecx 3chrisignmNo ratings yet
- Micecx 2Document14 pagesMicecx 2chrisignmNo ratings yet
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- Micecx 4Document28 pagesMicecx 4chrisignmNo ratings yet
- Nonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970From EverandNonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970Louis B. RallNo ratings yet
- Chapter 16Document6 pagesChapter 16maustroNo ratings yet
- LecturesDocument766 pagesLecturesHe HNo ratings yet
- Unit 5Document104 pagesUnit 5downloadjain123No ratings yet
- 4 RegressionDocument24 pages4 RegressionBlessing MapadzaNo ratings yet
- Topic 6B RegressionDocument13 pagesTopic 6B RegressionMATHAVAN A L KRISHNANNo ratings yet
- Simple Regression Model: Erbil Technology InstituteDocument9 pagesSimple Regression Model: Erbil Technology Institutemhamadhawlery16No ratings yet
- Linear RegressionDocument17 pagesLinear RegressionLuka SavićNo ratings yet
- Ols 2Document19 pagesOls 2sanamdadNo ratings yet
- Regression: Dr. Agustinus Suryantoro, M.SDocument31 pagesRegression: Dr. Agustinus Suryantoro, M.SVikha Suryo KharismawanNo ratings yet
- An Introduction To Objective Bayesian Statistics PDFDocument69 pagesAn Introduction To Objective Bayesian Statistics PDFWaterloo Ferreira da SilvaNo ratings yet
- LP-III Lab ManualDocument49 pagesLP-III Lab ManualNihal GujarNo ratings yet
- AIML ppt1Document8 pagesAIML ppt1apoorva.k2017No ratings yet
- Tutorial On PLS and PCADocument17 pagesTutorial On PLS and PCAElsa GeorgeNo ratings yet
- Cheming eDocument61 pagesCheming eEduardo Ocampo HernandezNo ratings yet
- Applied Statistics II-SLRDocument23 pagesApplied Statistics II-SLRMagnifico FangaWoro100% (1)
- Matemath For Data ScienceDocument10 pagesMatemath For Data ScienceSuryanNo ratings yet
- EconometricsDocument12 pagesEconometricsJessica SohNo ratings yet
- Probability and StatisticsDocument55 pagesProbability and StatisticsOladokun Sulaiman OlanrewajuNo ratings yet
- Linear RegressionDocument56 pagesLinear RegressionOpus YenNo ratings yet
- Hypothesis TestingDocument27 pagesHypothesis TestingJessica SohNo ratings yet
- Introduction To Error AnalysisDocument21 pagesIntroduction To Error AnalysisMichael MutaleNo ratings yet
- Ordinary Least Squares: Linear ModelDocument13 pagesOrdinary Least Squares: Linear ModelNanang ArifinNo ratings yet
- M07 Julita Nahar PDFDocument8 pagesM07 Julita Nahar PDFNadya NovitaNo ratings yet
- RegressionDocument6 pagesRegressionMansi ChughNo ratings yet
- Solving Multicollinearity Problem: Int. J. Contemp. Math. Sciences, Vol. 6, 2011, No. 12, 585 - 600Document16 pagesSolving Multicollinearity Problem: Int. J. Contemp. Math. Sciences, Vol. 6, 2011, No. 12, 585 - 600Tiberiu TincaNo ratings yet
- Regression and CorrelationDocument13 pagesRegression and CorrelationzNo ratings yet
- ch02 Edit v2Document69 pagesch02 Edit v222000492No ratings yet
- MAE 300 TextbookDocument95 pagesMAE 300 Textbookmgerges15No ratings yet
- The Uncertainty of A Result From A Linear CalibrationDocument14 pagesThe Uncertainty of A Result From A Linear CalibrationudsaigakfsNo ratings yet
- Slides BackupDocument38 pagesSlides BackupWahaj KamranNo ratings yet
- Question 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1Document9 pagesQuestion 4 (A) What Are The Stochastic Assumption of The Ordinary Least Squares? Assumption 1yaqoob008No ratings yet
- Lesson 2: Multiple Linear Regression Model (I) : E L F V A L U A T I O N X E R C I S E SDocument14 pagesLesson 2: Multiple Linear Regression Model (I) : E L F V A L U A T I O N X E R C I S E SMauricio Ortiz OsorioNo ratings yet
- Lectures 8 9 10Document185 pagesLectures 8 9 10AzmiHafifiNo ratings yet
- QM1 Typed NotesDocument18 pagesQM1 Typed Noteskarl hemmingNo ratings yet
- (Bruderl) Applied Regression Analysis Using StataDocument73 pages(Bruderl) Applied Regression Analysis Using StataSanjiv DesaiNo ratings yet
- Estimation in A Multivariate Errors in Variables Regression Model (Large Sample Results)Document22 pagesEstimation in A Multivariate Errors in Variables Regression Model (Large Sample Results)ainNo ratings yet
- Econometrics Module 2Document38 pagesEconometrics Module 2chatfieldlohrNo ratings yet
- Chapter 4Document68 pagesChapter 4Nhatty WeroNo ratings yet
- Introduction To Econometrics (ET2013) : Teresa RandazzoDocument30 pagesIntroduction To Econometrics (ET2013) : Teresa RandazzoNikuBotnariNo ratings yet
- 03 ES Regression CorrelationDocument14 pages03 ES Regression CorrelationMuhammad AbdullahNo ratings yet
- M. Amir Hossain PHD: Course No: Emba 502: Business Mathematics and StatisticsDocument31 pagesM. Amir Hossain PHD: Course No: Emba 502: Business Mathematics and StatisticsSP VetNo ratings yet
- PH511 Lab Manual-July-Nov. 2022Document24 pagesPH511 Lab Manual-July-Nov. 2022Dhananjay KapseNo ratings yet
- Mathematics in Machine LearningDocument83 pagesMathematics in Machine LearningSubha OPNo ratings yet
- Mean, Standard Deviation, and Counting StatisticsDocument2 pagesMean, Standard Deviation, and Counting StatisticsMohamed NaeimNo ratings yet
- Chapter Two: Bivariate Regression ModeDocument54 pagesChapter Two: Bivariate Regression ModenahomNo ratings yet
- Inference For RegressionDocument24 pagesInference For RegressionJosh PotashNo ratings yet
- Ordinary Least SquaresDocument21 pagesOrdinary Least SquaresRahulsinghooooNo ratings yet
- Complete Business Statistics: by Amir D. Aczel & Jayavel Sounderpandian 6 EditionDocument54 pagesComplete Business Statistics: by Amir D. Aczel & Jayavel Sounderpandian 6 EditionMohit VermaNo ratings yet
- 2b Multiple Linear RegressionDocument14 pages2b Multiple Linear RegressionNamita DeyNo ratings yet
- Stata Lecture2Document134 pagesStata Lecture2lukyindonesiaNo ratings yet
- This Content Downloaded From 117.227.34.195 On Fri, 18 Nov 2022 17:23:35 UTCDocument11 pagesThis Content Downloaded From 117.227.34.195 On Fri, 18 Nov 2022 17:23:35 UTCsherlockholmes108No ratings yet
- 2333-211118-Exam 3 Review - TaggedDocument20 pages2333-211118-Exam 3 Review - TaggedJorge CastilloNo ratings yet
- Simple Linear Regression and Multiple Linear Regression: MAST 6474 Introduction To Data Analysis IDocument15 pagesSimple Linear Regression and Multiple Linear Regression: MAST 6474 Introduction To Data Analysis IJohn SmithNo ratings yet
- Probability Sampling - According To BJYU's, It Utilizes Some Form of Random Selection. in ThisDocument28 pagesProbability Sampling - According To BJYU's, It Utilizes Some Form of Random Selection. in ThisShiela Louisianne AbañoNo ratings yet
- Collection and Presentation of DatafinalDocument95 pagesCollection and Presentation of DatafinalYvonne Alonzo De BelenNo ratings yet
- Worksheet 4 - Mean and Variance of Sampling DistributionDocument2 pagesWorksheet 4 - Mean and Variance of Sampling DistributionRey SteveNo ratings yet
- Omitted Variable Bias: The Simple CaseDocument8 pagesOmitted Variable Bias: The Simple CasecjNo ratings yet
- Abdulkerim DinoDocument68 pagesAbdulkerim DinoOmar ReyanNo ratings yet
- Confidence, Prediction, and Tolerance Intervals: Engineering Experimental Design Valerie L. YoungDocument18 pagesConfidence, Prediction, and Tolerance Intervals: Engineering Experimental Design Valerie L. YoungEng MakwebaNo ratings yet
- Artikel Kajian LusianaDocument12 pagesArtikel Kajian LusianaLusiana SNo ratings yet
- Athey 2015Document2 pagesAthey 2015MunirNo ratings yet
- Conversion Chart T-Scores To Standard Scores PDFDocument1 pageConversion Chart T-Scores To Standard Scores PDFcoldfritesNo ratings yet
- Censored Quantile Regression ReduxDocument26 pagesCensored Quantile Regression ReduxguitarPtNo ratings yet
- Auditing Report HuhuDocument26 pagesAuditing Report HuhuRemar James DolleteNo ratings yet
- Term Project DetailsDocument4 pagesTerm Project Detailsapi-316152589No ratings yet
- Confidence Intervals For Proportions Take Home TestDocument5 pagesConfidence Intervals For Proportions Take Home Test1012219No ratings yet
- STAT501 Complex SurveyDocument104 pagesSTAT501 Complex SurveyPercy Soto BecerraNo ratings yet
- Analysis and Management of Production System: Lesson 11: Variability of Processing TimeDocument33 pagesAnalysis and Management of Production System: Lesson 11: Variability of Processing TimeEnri GjondrekajNo ratings yet
- University of Hyderabad Post Graduate Diploma in Business Management (PGDBM) I Term Assignment (2016) Dbm-416: Quantitative and Research MethodsDocument4 pagesUniversity of Hyderabad Post Graduate Diploma in Business Management (PGDBM) I Term Assignment (2016) Dbm-416: Quantitative and Research Methodsrao_nari8305No ratings yet
- QT Quiz FinalDocument223 pagesQT Quiz Finalparikh_prateek063784No ratings yet
- St. Peter's College of Ormoc: SY 2020-2021 School ThemeDocument4 pagesSt. Peter's College of Ormoc: SY 2020-2021 School ThemeKatezskiie NovalNo ratings yet
- N4studies Sample Size Calculation For AnDocument11 pagesN4studies Sample Size Calculation For AnAzoz FaizNo ratings yet
- AP Psychology Module 6Document16 pagesAP Psychology Module 6Klein ZhangNo ratings yet
- Pareto Analysis: Sigma Quality ManagementDocument12 pagesPareto Analysis: Sigma Quality ManagementEkopribadiNo ratings yet
- 7.6.2 Appendix: Using R To Find Confidence IntervalsDocument4 pages7.6.2 Appendix: Using R To Find Confidence IntervalsAnonymous MqprQvjEKNo ratings yet
- Assignment 1: Data Analytics For Business DecisionDocument6 pagesAssignment 1: Data Analytics For Business Decisiongautam maggoVWsKrHajMQNo ratings yet
- Perhitungan Regresi Dengan Excell Secara ManualDocument7 pagesPerhitungan Regresi Dengan Excell Secara Manualnaning mekawatiNo ratings yet
- XLSTAT Features by Solution - Statistical Software For ExcelDocument9 pagesXLSTAT Features by Solution - Statistical Software For Excelmarmah_hadiNo ratings yet
- 7varversion RR Group Assignment Mel Econ1066 2110Document26 pages7varversion RR Group Assignment Mel Econ1066 2110MINH NGUYỄN LÂM TƯỜNG100% (1)
- Heckman Selection ModelsDocument4 pagesHeckman Selection ModelsrbmalasaNo ratings yet
- Nota RegresiDocument3 pagesNota RegresiAl_Raqibah_Bin_2217No ratings yet
- Lecture 3 & 4 Describing Data Numerical MeasuresDocument24 pagesLecture 3 & 4 Describing Data Numerical Measuresfbm2000No ratings yet
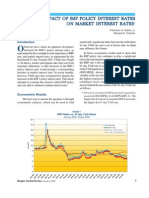
- BSR2006a - 01THE IMPACT OF BSP POLICY INTEREST RATES ON MARKET INTEREST RATES1Document6 pagesBSR2006a - 01THE IMPACT OF BSP POLICY INTEREST RATES ON MARKET INTEREST RATES1이수연No ratings yet