You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Gaytri Sampoorn Puja VidhiDocument123 pagesGaytri Sampoorn Puja VidhiAnurag Chand75% (8)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Gaytri Sampoorn Puja VidhiDocument123 pagesGaytri Sampoorn Puja VidhiAnurag Chand75% (8)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Guidelines For Treatment of DengueDocument4 pagesGuidelines For Treatment of DengueegalivanNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Gaytri Sampoorn Puja VidhiDocument123 pagesGaytri Sampoorn Puja VidhiAnurag Chand75% (8)
- Guidelines For Treatment of DengueDocument4 pagesGuidelines For Treatment of DengueegalivanNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- A CPM Strategic PlanDocument2 pagesA CPM Strategic Planpradeep0224uNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- RMNCH+a StrategyDocument83 pagesRMNCH+a Strategypradeep0224uNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Abstract PracticeDocument4 pagesAbstract PracticerifqiNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
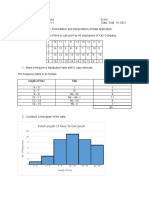
- Cedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDocument4 pagesCedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDeuK WR100% (1)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- A Minimal Core Calculus For Java and GJDocument15 pagesA Minimal Core Calculus For Java and GJpostscriptNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Edge of Space: Revisiting The Karman LineDocument10 pagesThe Edge of Space: Revisiting The Karman LineAlpin AndromedaNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Lesson 4: Mean and Variance of Discrete Random Variable: Grade 11 - Statistics & ProbabilityDocument26 pagesLesson 4: Mean and Variance of Discrete Random Variable: Grade 11 - Statistics & Probabilitynicole MenesNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- AN2061 Application Note: EEPROM Emulation With ST10F2xxDocument15 pagesAN2061 Application Note: EEPROM Emulation With ST10F2xxleuchimed mouhNo ratings yet
- Limit of Outside Usage Outside Egypt ENDocument1 pageLimit of Outside Usage Outside Egypt ENIbrahem EmamNo ratings yet
- 5.talisayon Chapter 3Document12 pages5.talisayon Chapter 3Jinky Marie TuliaoNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Samuel Mendez, "Health Equity Rituals: A Case For The Ritual View of Communication in An Era of Precision Medicine"Document227 pagesSamuel Mendez, "Health Equity Rituals: A Case For The Ritual View of Communication in An Era of Precision Medicine"MIT Comparative Media Studies/WritingNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Gathering Statistical DataDocument8 pagesGathering Statistical DataianNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- An Approach To Predict The Failure of Water Mains Under Climatic VariationsDocument16 pagesAn Approach To Predict The Failure of Water Mains Under Climatic VariationsGeorge, Yonghe YuNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Other Books NewDocument136 pagesOther Books NewYashRaj ChoudharyNo ratings yet
- 18.443 MIT Stats CourseDocument139 pages18.443 MIT Stats CourseAditya JainNo ratings yet
- DTS Letter of Request To IndustryDocument3 pagesDTS Letter of Request To IndustryJohn Paul MartinNo ratings yet
- John Constantine Rouge Loner Primordial Orphan Paranormal DetectiveDocument4 pagesJohn Constantine Rouge Loner Primordial Orphan Paranormal DetectiveMirko PrćićNo ratings yet
- Algebra IiDocument2 pagesAlgebra IiFumiServi GuayaquilNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Coolit SystemsDocument5 pagesCoolit SystemsUsama NaseemNo ratings yet
- Practice Exercise For Final Assessment 2221Document3 pagesPractice Exercise For Final Assessment 2221Guneet Singh ChawlaNo ratings yet
- Drone Hexacopter IjisrtDocument4 pagesDrone Hexacopter IjisrtDEPARTEMEN RUDALNo ratings yet
- Articulo SDocument11 pagesArticulo SGABRIELANo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Social Studies Bece Mock 2024Document6 pagesSocial Studies Bece Mock 2024awurikisimonNo ratings yet
- Socrates 8dDocument8 pagesSocrates 8dcarolinaNo ratings yet
- Short Time Fourier TransformDocument37 pagesShort Time Fourier TransformGopikaPrasadNo ratings yet
- Assignment 7Document1 pageAssignment 7sujit kcNo ratings yet
- Quick Start Guide - QualiPoc AndroidDocument24 pagesQuick Start Guide - QualiPoc AndroidDmitekNo ratings yet
- Using Sunspots To Measure Solar Rotation: Astronomy 104 Observing Laboratory Spring 2009Document6 pagesUsing Sunspots To Measure Solar Rotation: Astronomy 104 Observing Laboratory Spring 2009Jeko Betguen PalangiNo ratings yet
- BG BG 202102080912862 User Manual - File (Long) BG BG-8Document1 pageBG BG 202102080912862 User Manual - File (Long) BG BG-8hofolo39No ratings yet
- AR Ageing FinalDocument13 pagesAR Ageing FinalHAbbunoNo ratings yet
- 12th Maths - English Medium PDF DownloadDocument38 pages12th Maths - English Medium PDF DownloadSupriya ReshmaNo ratings yet
- Towards Innovative Community Building: DLSU Holds Henry Sy, Sr. Hall GroundbreakingDocument2 pagesTowards Innovative Community Building: DLSU Holds Henry Sy, Sr. Hall GroundbreakingCarl ChiangNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)