You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Statistics Lesson Plan-2Document2 pagesStatistics Lesson Plan-2api-237496321No ratings yet
- Support Vector MachineDocument45 pagesSupport Vector MachinekevalNo ratings yet
- Jordan Vneumann THMDocument3 pagesJordan Vneumann THMJamilu Adamu MusaNo ratings yet
- Data Structures Through C 1Document209 pagesData Structures Through C 1Abhay DabhadeNo ratings yet
- Experimental Study On Tool Condition Monitoring in Boring of AISI 316 Stainless SteelDocument12 pagesExperimental Study On Tool Condition Monitoring in Boring of AISI 316 Stainless SteelshitalchiddarwarNo ratings yet
- D4304-Syllabus-Neural Networks and Fuzzy SystemsDocument1 pageD4304-Syllabus-Neural Networks and Fuzzy Systemsshankar15050% (1)
- Anti-Spam Filter Based On Naïve Bayes, SVM, and KNN ModelDocument5 pagesAnti-Spam Filter Based On Naïve Bayes, SVM, and KNN ModelEdgar MarcaNo ratings yet
- Delta Surface Methodology - Implied Volatility Surface by DeltaDocument9 pagesDelta Surface Methodology - Implied Volatility Surface by DeltaShirley XinNo ratings yet
- Hull m3sp5Document30 pagesHull m3sp5Firstface LastbookNo ratings yet
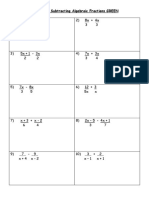
- Algebraic FractionDocument4 pagesAlgebraic FractionBaiquinda ElzulfaNo ratings yet
- Tap FSMDocument39 pagesTap FSMMadhukumar KsNo ratings yet
- Cambridge University Chemistry DataBookDocument18 pagesCambridge University Chemistry DataBookiantocNo ratings yet
- Topic:: Testing of Hypothesis About Linear RegressionDocument15 pagesTopic:: Testing of Hypothesis About Linear RegressionAtifMuhammadNo ratings yet
- SSVR Single Phase enDocument4 pagesSSVR Single Phase enankur rathiNo ratings yet
- Programs For C Building Blocks:: 1. WAP in C To Print "HELLO WORLD"Document86 pagesPrograms For C Building Blocks:: 1. WAP in C To Print "HELLO WORLD"Gautam VermaNo ratings yet
- Class 9 Sample Questions: International Reasoning & Aptitude Olympiad - iRAO 22Document1 pageClass 9 Sample Questions: International Reasoning & Aptitude Olympiad - iRAO 22Anshuman Chauhan 9ENo ratings yet
- Numerical Analysis: Lecture - 3Document17 pagesNumerical Analysis: Lecture - 3khizarNo ratings yet
- Impact of Jet PDFDocument32 pagesImpact of Jet PDFHari PrakashNo ratings yet
- Bee Lab ManualDocument69 pagesBee Lab ManualYash AryaNo ratings yet
- Hardy Cross Continuous Frames of Reinforced ConcreteDocument361 pagesHardy Cross Continuous Frames of Reinforced ConcreteCarson BakerNo ratings yet
- (Lecture 3) Linear Equations of Single Variable-2Document2 pages(Lecture 3) Linear Equations of Single Variable-2HendriNo ratings yet
- Chapter 10 Solutions PDFDocument30 pagesChapter 10 Solutions PDFabcNo ratings yet
- Applications of StacksDocument17 pagesApplications of StacksaadityakrjainNo ratings yet
- Composite Materials Assignment 1Document2 pagesComposite Materials Assignment 1Danielle Wagner0% (1)
- Amcat Question QUANTITATIVE ABILITY Papers-2. - FresherLine - Jobs, Recruitment, Fresher - FresherlineDocument2 pagesAmcat Question QUANTITATIVE ABILITY Papers-2. - FresherLine - Jobs, Recruitment, Fresher - FresherlinePrashant Kumar TiwariNo ratings yet
- Zhi Dong Bai, Random Matrix Theory and Its ApplicationsDocument174 pagesZhi Dong Bai, Random Matrix Theory and Its ApplicationsanthalyaNo ratings yet
- Two-Way ANOVA and InteractionsDocument15 pagesTwo-Way ANOVA and InteractionsBrian WebbNo ratings yet
- SS1 Physics Note WK 3Document11 pagesSS1 Physics Note WK 3Samuel EwomazinoNo ratings yet
- Matlab CodeDocument7 pagesMatlab CodeOmar Waqas SaadiNo ratings yet
- 1997 1829 Wake-Body InterferenceDocument10 pages1997 1829 Wake-Body InterferenceMarcos SoarNo ratings yet