You might also like
- Corejava PDFDocument250 pagesCorejava PDFsai srinivasNo ratings yet
- Java MCQ MergedDocument850 pagesJava MCQ Mergedunolo123100% (1)
- Durga Sir Java NotesDocument32 pagesDurga Sir Java Notesbhushan laware50% (2)
- SQL Server by RN ReddyDocument233 pagesSQL Server by RN ReddyKoushik SadhuNo ratings yet
- Hibernate MaterialDocument71 pagesHibernate MaterialTushar PatilNo ratings yet
- CoreJava PracticeLabDocument26 pagesCoreJava PracticeLabyogitha279267% (3)
- Top 50 SQL Interview Questions and Answers For Experienced & Freshers (2021 Update)Document15 pagesTop 50 SQL Interview Questions and Answers For Experienced & Freshers (2021 Update)KrupanandareddyYarragudiNo ratings yet
- Core Java Test QuestionsDocument13 pagesCore Java Test QuestionsVinodKatkar100% (1)
- SQL InterviewDocument62 pagesSQL InterviewNgô HoàngNo ratings yet
- Java Practice Questions and McqsDocument309 pagesJava Practice Questions and McqsAnonymous JP7Zqcgx50% (4)
- Jspiders Delhi-Ncr 9810072392: 1.program To CHK Number Is Palindrome or NotDocument5 pagesJspiders Delhi-Ncr 9810072392: 1.program To CHK Number Is Palindrome or NotCHIRAG MATTANo ratings yet
- Java Technologies - 2 PG DACDocument28 pagesJava Technologies - 2 PG DACSumeet PathadeNo ratings yet
- WebEx meeting link and Shopify training outlinesDocument16 pagesWebEx meeting link and Shopify training outlinesshakil ahmad khanNo ratings yet
- Adv Java NitDocument229 pagesAdv Java Nitsonam100% (3)
- SQL QueriesDocument11 pagesSQL QueriesWaqarAhmadAlviNo ratings yet
- SQL Notes PDFDocument15 pagesSQL Notes PDFANo ratings yet
- A4academics Com Interview Questions 53 Database and SQL 397Document14 pagesA4academics Com Interview Questions 53 Database and SQL 397Abhishek Sharma0% (1)
- Core JavaDocument214 pagesCore JavaShylaja G100% (4)
- JAVA LAB MANUALDocument28 pagesJAVA LAB MANUALMegha GargNo ratings yet
- Software Development Java ResumeDocument2 pagesSoftware Development Java ResumeHarisha G MNo ratings yet
- API vs FrameworkDocument40 pagesAPI vs Frameworkpramod kashyap50% (2)
- Java NotesDocument46 pagesJava Notesmuseb ittangiwale100% (2)
- Oracle 10g Material FinalDocument145 pagesOracle 10g Material Finalsbabu4u100% (1)
- C# NetcDocument22 pagesC# Netcprakash_net4_0100% (1)
- C# NotesDocument158 pagesC# NotesSatish Basavaraj Basapur100% (1)
- New Java Programs Copy - 2021Document68 pagesNew Java Programs Copy - 2021fiona100% (1)
- Exception HandlingDocument11 pagesException Handlingravi_00013No ratings yet
- Kishan Java NotesDocument284 pagesKishan Java NotesKishan Jaycker100% (1)
- API MCQ Set1Document25 pagesAPI MCQ Set1Praneet kumarNo ratings yet
- Java NotesDocument202 pagesJava NotesSourajit MitraNo ratings yet
- Java Lab ManualDocument38 pagesJava Lab ManualAshfaq Hussain0% (1)
- Top 33 JDBC Interview QuestionsDocument8 pagesTop 33 JDBC Interview QuestionsSatish BabuNo ratings yet
- SQL Class NotesDocument54 pagesSQL Class Notesranjithgottimukkala100% (1)
- Natraj InterviewsDocument32 pagesNatraj InterviewsRamesh BommaganiNo ratings yet
- Conditional Statements: If-Else StatementDocument16 pagesConditional Statements: If-Else StatementRaghu GbNo ratings yet
- MCQDocument3 pagesMCQmanaliNo ratings yet
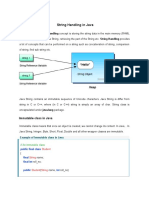
- String Handling in Java: Key Concepts and MethodsDocument24 pagesString Handling in Java: Key Concepts and MethodsVenu DNo ratings yet
- SQL Server NotesDocument75 pagesSQL Server NotesShashiBTITNo ratings yet
- CREATE SAMPLE TABLES, TRIGGERS, LOGMANAGER TABLEDocument4 pagesCREATE SAMPLE TABLES, TRIGGERS, LOGMANAGER TABLEKHAMBHATI NIRAL DEVANG100% (1)
- SQL Interview Questions and AnswersDocument25 pagesSQL Interview Questions and AnswersJigar ShahNo ratings yet
- Java ThreadsDocument15 pagesJava ThreadsKISHOREMUTCHARLA100% (1)
- File Handling IntroductionDocument2 pagesFile Handling Introductionsamrudhi50% (4)
- Java MCQDocument13 pagesJava MCQrajNo ratings yet
- Cs8383 Oops Lab ManualDocument81 pagesCs8383 Oops Lab ManualKarthik Subramani83% (12)
- Final Exam ReviewDocument4 pagesFinal Exam ReviewHenry ZhouNo ratings yet
- BSC IV Sem JAVA Lab ProgramsDocument35 pagesBSC IV Sem JAVA Lab ProgramsTeller Person100% (2)
- JAVApracticalsDocument5 pagesJAVApracticalsXYZNo ratings yet
- Java MCQDocument25 pagesJava MCQSurya KameswariNo ratings yet
- Core Java MCQ Questions and Answers: Take Online Java MCQ Test To Test Your KnowledgeDocument6 pagesCore Java MCQ Questions and Answers: Take Online Java MCQ Test To Test Your KnowledgeMayankNo ratings yet
- Oracle Practical FileDocument9 pagesOracle Practical FileKarandeep Singh100% (2)
- JS-Basic Code PDFDocument7 pagesJS-Basic Code PDFSanthosh KrishnaNo ratings yet
- J2EEDocument80 pagesJ2EERanjithNo ratings yet
- Java Script AssignmentDocument7 pagesJava Script Assignmenthanima4No ratings yet
- Code To Solve Set of ProblemsDocument17 pagesCode To Solve Set of ProblemsMamta DoliyaNo ratings yet
- OOPS Viva Questions ExplainedDocument8 pagesOOPS Viva Questions ExplainedPunithadevi100% (1)
- DBMS Lab ManualDocument47 pagesDBMS Lab Manualprasad9440024661100% (4)
- DbmsDocument65 pagesDbmsDeepanshu PurwarNo ratings yet
- Introduction To Database Management System: Poonam MehtaDocument21 pagesIntroduction To Database Management System: Poonam Mehtacyka blyatNo ratings yet
- Sri Aurobindo Institute of Technology: RDBMS LAB (ME-606)Document20 pagesSri Aurobindo Institute of Technology: RDBMS LAB (ME-606)Rajat MalviyaNo ratings yet
- Points To Be Noted During Online SubmissionDocument1 pagePoints To Be Noted During Online SubmissionUddipto SenNo ratings yet
- Read MeDocument1 pageRead MeFakhar BalochNo ratings yet
- Tcs Placement Paper 01Document4 pagesTcs Placement Paper 01Uddipto SenNo ratings yet
- Scan Doc by CamScannerDocument1 pageScan Doc by CamScannerUddipto SenNo ratings yet
- DBMS QUESTION ANSWERSDocument27 pagesDBMS QUESTION ANSWERSUddipto Sen100% (1)
- Adv Hiring Project Staff 2014Document4 pagesAdv Hiring Project Staff 2014manisha maniNo ratings yet
- Laurent SeriesDocument4 pagesLaurent SeriesGabo del NorteNo ratings yet
- LaplaceDocument4 pagesLaplaceUddipto SenNo ratings yet
- Admission Process FlowDocument2 pagesAdmission Process FlowmvsrrNo ratings yet
- TCS Pattern Model QuestionsDocument95 pagesTCS Pattern Model QuestionsUddipto SenNo ratings yet
- Railway Recruitment Boards publish corrigendum on vacancies and PWD suitabilityDocument1 pageRailway Recruitment Boards publish corrigendum on vacancies and PWD suitabilityJayanth SamavedamNo ratings yet
- IP FundamentalsDocument81 pagesIP FundamentalsAdrian EladNo ratings yet
- Introduction To Statistical Quality ControlDocument29 pagesIntroduction To Statistical Quality ControlmivranesNo ratings yet
- Statistical Quality ControlDocument14 pagesStatistical Quality ControlvignanarajNo ratings yet
- Temperature-Aware Routing in 3D IcsDocument6 pagesTemperature-Aware Routing in 3D IcsUddipto SenNo ratings yet
- Wbut MicroprocessorDocument6 pagesWbut MicroprocessorUddipto SenNo ratings yet
- TCS Pattern Model QuestionsDocument95 pagesTCS Pattern Model QuestionsUddipto SenNo ratings yet
- 1038 Questions Mech QuestionDocument152 pages1038 Questions Mech QuestionRaushan KumarNo ratings yet
- TCS Placement Paper 1Document15 pagesTCS Placement Paper 1anoos04No ratings yet
- Adv Hiring Project Staff 2014Document4 pagesAdv Hiring Project Staff 2014manisha maniNo ratings yet
- Computing the Discrete Fourier Transform with the Fast Fourier Transform AlgorithmDocument12 pagesComputing the Discrete Fourier Transform with the Fast Fourier Transform Algorithmhakkem bNo ratings yet
- Effect of Resistor Tolerances On Power Supply Accuracy: Application ReportDocument6 pagesEffect of Resistor Tolerances On Power Supply Accuracy: Application ReportUddipto SenNo ratings yet
- Fifa 14 ReadmeDocument9 pagesFifa 14 ReadmeAshikur RahmanNo ratings yet
- 0 Territorial28aprial09Document2 pages0 Territorial28aprial09Uddipto SenNo ratings yet
- Calling Card BusinessDocument5 pagesCalling Card BusinessAbraham GhNo ratings yet
- Glossary of Budget Terms: Balance AvailableDocument6 pagesGlossary of Budget Terms: Balance AvailableharshitjskNo ratings yet
- Fourier TransformDocument5 pagesFourier TransformUddipto Sen100% (1)
- BEL Recruitment Exam Pattern and Syllabus for ECEDocument1 pageBEL Recruitment Exam Pattern and Syllabus for ECEUddipto SenNo ratings yet
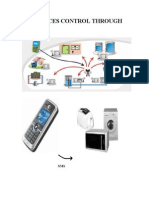
- Appliances Control Through SmsDocument7 pagesAppliances Control Through SmspushkararoraNo ratings yet