You might also like
- Cover Letter For Minority Women RightsDocument1 pageCover Letter For Minority Women Rightszeeshan78returntohydNo ratings yet
- Neural Networks and Their Application To Finance: Martin P. Wallace (P D)Document10 pagesNeural Networks and Their Application To Finance: Martin P. Wallace (P D)Goutham BeesettyNo ratings yet
- Competition and Self-Organisation - Kohonen NetsDocument12 pagesCompetition and Self-Organisation - Kohonen NetsAnonymous I0bTVBNo ratings yet
- Kohen's Self Organizing Maps - NotesDocument4 pagesKohen's Self Organizing Maps - NotesjamieabeyNo ratings yet
- Clustering in BioinformaticsDocument110 pagesClustering in BioinformaticstisimpsonNo ratings yet
- What Is Research ReportDocument28 pagesWhat Is Research Reportsadia khalidNo ratings yet
- Chapter8-Basic Cluster Analysis2018Document143 pagesChapter8-Basic Cluster Analysis2018Zerlynda Fitria Nur MayantiNo ratings yet
- CS361 Soft Computing CSE Syllabus-Semesters - 5 PDFDocument3 pagesCS361 Soft Computing CSE Syllabus-Semesters - 5 PDFKATE WATSONNo ratings yet
- Self Organization MapsDocument14 pagesSelf Organization MapsdocumentosvaltierraNo ratings yet
- Soft Computing 2016Document4 pagesSoft Computing 2016Sandeep RoyNo ratings yet
- AI AssignmentDocument5 pagesAI AssignmentRajeev SahaniNo ratings yet
- Numerical Methods for Differential Systems: Recent Developments in Algorithms, Software, and ApplicationsFrom EverandNumerical Methods for Differential Systems: Recent Developments in Algorithms, Software, and ApplicationsL. LapidusRating: 1 out of 5 stars1/5 (1)
- Kohonen Self Organizing MapsDocument4 pagesKohonen Self Organizing MapsSamuditha YatiwellaNo ratings yet
- Fundamentals of Electronics 2: Continuous-time Signals and SystemsFrom EverandFundamentals of Electronics 2: Continuous-time Signals and SystemsNo ratings yet
- K Means AlgorithmDocument6 pagesK Means AlgorithmAsir Mosaddek SakibNo ratings yet
- The Decision-Feedback Equalizer PDFDocument5 pagesThe Decision-Feedback Equalizer PDFHuy Nguyễn QuốcNo ratings yet
- Behavioural Science QuestionsDocument5 pagesBehavioural Science QuestionsPritika SharmaNo ratings yet
- Real-Time Data Acquisition in Human Physiology: Real-Time Acquisition, Processing, and Interpretation—A MATLAB-Based ApproachFrom EverandReal-Time Data Acquisition in Human Physiology: Real-Time Acquisition, Processing, and Interpretation—A MATLAB-Based ApproachNo ratings yet
- K Means Clustering in R Example - Learn by MarketingDocument3 pagesK Means Clustering in R Example - Learn by MarketingAri CleciusNo ratings yet
- Set Symbols of Set Theory (Ø, U,, ,..Document4 pagesSet Symbols of Set Theory (Ø, U,, ,..Les CanoNo ratings yet
- Image RestorationDocument41 pagesImage Restorationcsbits0% (1)
- Williams L.J., Krishnan A., Abdi H - Experimental Design and Analysis For Psychology PDFDocument192 pagesWilliams L.J., Krishnan A., Abdi H - Experimental Design and Analysis For Psychology PDFDafny C. Arone100% (1)
- Manual On TranscriptionDocument93 pagesManual On TranscriptionMarco PerezNo ratings yet
- Approximate Frequency Counts Over Data StreamsDocument87 pagesApproximate Frequency Counts Over Data StreamsVidit PathakNo ratings yet
- Libra - Rfid Library With HF and Uhf TechnologyDocument18 pagesLibra - Rfid Library With HF and Uhf TechnologyLibbest RfidNo ratings yet
- Using Statistics in the Social and Health Sciences with SPSS and ExcelFrom EverandUsing Statistics in the Social and Health Sciences with SPSS and ExcelNo ratings yet
- Interpreting Multiple RegressionDocument19 pagesInterpreting Multiple RegressionRalph Wajah ZwenaNo ratings yet
- AP Psychology Review Part 1Document27 pagesAP Psychology Review Part 1Tony Hue100% (8)
- Pseudocode ReferenceDocument10 pagesPseudocode ReferenceImran Hasanuddin0% (1)
- AI-Lecture 12 - Simple PerceptronDocument24 pagesAI-Lecture 12 - Simple PerceptronMadiha Nasrullah100% (1)
- Demystifying Deep Convolutional Neural Networks - Adam Harley (2014) CNN PDFDocument27 pagesDemystifying Deep Convolutional Neural Networks - Adam Harley (2014) CNN PDFharislyeNo ratings yet
- On Neural Networks and Application: Submitted By: Makrand Ballal Reg No. 1025929 Mca 3 SemDocument14 pagesOn Neural Networks and Application: Submitted By: Makrand Ballal Reg No. 1025929 Mca 3 Semmakku_ballalNo ratings yet
- Machine Learning Data Mining: ProblemsDocument27 pagesMachine Learning Data Mining: ProblemsnanaoNo ratings yet
- Understanding Neural Networks. We Explore How Neural Networks Function - by Tony Yiu - Towards Data ScienceDocument18 pagesUnderstanding Neural Networks. We Explore How Neural Networks Function - by Tony Yiu - Towards Data ScienceDerrick TayNo ratings yet
- What Are Neural NetsDocument4 pagesWhat Are Neural NetsCVDSCRIBNo ratings yet
- Clustering Technique: Mohammad Ali JoneidiDocument3 pagesClustering Technique: Mohammad Ali JoneidimadalNo ratings yet
- Unit 2Document25 pagesUnit 2Darshan RaoraneNo ratings yet
- Artificial Neural NetworkDocument21 pagesArtificial Neural Networkannibuit007No ratings yet
- Complex Brain Networks Graph Theoretical Analysis of Structural and Functional SystemsDocument13 pagesComplex Brain Networks Graph Theoretical Analysis of Structural and Functional SystemsWillian Muniz Do NascimentoNo ratings yet
- Szegedy 2014 Intriguing Properties of Neural Networks PDFDocument10 pagesSzegedy 2014 Intriguing Properties of Neural Networks PDFroblee1No ratings yet
- L 1Document16 pagesL 1Evelyn Gabriela Lema VinuezaNo ratings yet
- Artificial Neural Networks For Beginners: September 2003Document9 pagesArtificial Neural Networks For Beginners: September 2003Kosta NikolicNo ratings yet
- New Microsoft Office Word DocumentDocument6 pagesNew Microsoft Office Word DocumentAjayNo ratings yet
- UNIT4Document13 pagesUNIT4Ayush NighotNo ratings yet
- Introduction To Neural Networks: 2Nd Year Ug, MSC in Computer ScienceDocument16 pagesIntroduction To Neural Networks: 2Nd Year Ug, MSC in Computer ScienceAhmad AbusnainaNo ratings yet
- Soft Computing Question AnswerDocument6 pagesSoft Computing Question AnswerNitesh NemaNo ratings yet
- Artificial Neural NetworksDocument12 pagesArtificial Neural NetworksBhargav Cho ChweetNo ratings yet
- Aspects of The Numerical Analysis of Neural NetworksDocument58 pagesAspects of The Numerical Analysis of Neural Networks은지No ratings yet
- Dsa Theory DaDocument41 pagesDsa Theory Daswastik rajNo ratings yet
- Feedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsFrom EverandFeedforward Neural Networks: Fundamentals and Applications for The Architecture of Thinking Machines and Neural WebsNo ratings yet
- Neural NetworksDocument12 pagesNeural NetworksP PNo ratings yet
- Artificial Neural NetworksDocument14 pagesArtificial Neural NetworksprashantupadhyeNo ratings yet
- Fqxi Essay 2017 RGDocument9 pagesFqxi Essay 2017 RGFrancisco Vega GarciaNo ratings yet
- Long Short Term Memory: Fundamentals and Applications for Sequence PredictionFrom EverandLong Short Term Memory: Fundamentals and Applications for Sequence PredictionNo ratings yet
- Fuzzy & Nural NetworkDocument24 pagesFuzzy & Nural NetworkRavi ShankarNo ratings yet
- CISIM2010 HBHashemiDocument5 pagesCISIM2010 HBHashemiHusain SulemaniNo ratings yet
- 2202.13829 HJFHKGDocument32 pages2202.13829 HJFHKGFrank GrahamNo ratings yet
- Chapter 19Document15 pagesChapter 19Ara Martínez-OlguínNo ratings yet
- Manual Instalare INIM SmartLine PDFDocument72 pagesManual Instalare INIM SmartLine PDFcristytrs787878No ratings yet
- S12000 Indoor: GSM Solutions GSM 850 / 900 / 1800 / 1900Document49 pagesS12000 Indoor: GSM Solutions GSM 850 / 900 / 1800 / 1900jintoNo ratings yet
- Additive Manufacturing: Presented by Nazma AmrinDocument23 pagesAdditive Manufacturing: Presented by Nazma AmrinSai SrinivasNo ratings yet
- BRF + (Business Rule Framework) Output Management in S/4 HANADocument7 pagesBRF + (Business Rule Framework) Output Management in S/4 HANAArun KumarNo ratings yet
- Deepak Kumar Kannaujiya's Resume-HackerresumeDocument1 pageDeepak Kumar Kannaujiya's Resume-HackerresumeDaya shankarNo ratings yet
- High-End High Quality 12sqm Budget of Outdoor P3.91SR Series 500x500mmDocument1 pageHigh-End High Quality 12sqm Budget of Outdoor P3.91SR Series 500x500mmCarlo PreciosoNo ratings yet
- Letter To Secretary Raimondo Regarding ITA's Promotion of Surveillance TechnologyDocument3 pagesLetter To Secretary Raimondo Regarding ITA's Promotion of Surveillance TechnologyAli BrelandNo ratings yet
- Tweet Sentiment Classification Using An Ensemble of Unsupervised Dictionary Based Classifier and Deep Convolutional Neural NetworkDocument9 pagesTweet Sentiment Classification Using An Ensemble of Unsupervised Dictionary Based Classifier and Deep Convolutional Neural NetworkEss Kay EssNo ratings yet
- Chapter I. Introduction To GCPDocument3 pagesChapter I. Introduction To GCPAyoub BENSAKHRIANo ratings yet
- Panelsaw CADmatic EDocument15 pagesPanelsaw CADmatic EDaniel Mazón ToledoNo ratings yet
- Archetype Nolly v2.0.0Document19 pagesArchetype Nolly v2.0.0LTNo ratings yet
- Sustainability 11 05355 v2Document24 pagesSustainability 11 05355 v2Singam SridharNo ratings yet
- Microsoft Content Services WhitePaper 5Document39 pagesMicrosoft Content Services WhitePaper 5andini eldanantyNo ratings yet
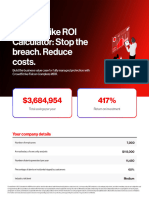
- Crowdstrike Personalized MDRDocument15 pagesCrowdstrike Personalized MDRkabayakimaki93No ratings yet
- Mariam Yasser (ERP) OS Disk ManagementDocument4 pagesMariam Yasser (ERP) OS Disk ManagementMariyam YasserNo ratings yet
- Act3 - Annisa Putri Purwariyono - 50418951Document10 pagesAct3 - Annisa Putri Purwariyono - 50418951annisa putri purwariyonoNo ratings yet
- 1.1.4 System Attributes To PerformanceDocument9 pages1.1.4 System Attributes To PerformanceVikram ShirolNo ratings yet
- Progress 4gl PDFDocument87 pagesProgress 4gl PDFKotresh NerkiNo ratings yet
- Introduction To C++ Friends, Nesting, Static Members, and TemplatesDocument70 pagesIntroduction To C++ Friends, Nesting, Static Members, and TemplatesRaaghav KumarNo ratings yet
- Module - 1 Notes - SEPM (21CS61)Document29 pagesModule - 1 Notes - SEPM (21CS61)Gagan V hallurNo ratings yet
- Lus-Cpall-Maq-Spe-Ut-10174 - District Cooling Sub-Meter System Guideline - Rev. 02Document8 pagesLus-Cpall-Maq-Spe-Ut-10174 - District Cooling Sub-Meter System Guideline - Rev. 02RamiAl-fuqahaNo ratings yet
- Kissing Booth AgreementDocument13 pagesKissing Booth AgreementZied SioudNo ratings yet
- Robotics TapasDocument260 pagesRobotics TapasADHADUK RONS MAHENDRABHAINo ratings yet
- JPNR - S02, 2023 - 154Document16 pagesJPNR - S02, 2023 - 154Dr Yousef ElebiaryNo ratings yet
- From Google Gemini To OpenAIDocument30 pagesFrom Google Gemini To OpenAIAgraNo ratings yet
- 1 - IntroductionDocument5 pages1 - Introductionboxbe9876No ratings yet
- Power Supply Board 860-AB0-P150BTLTA-2H For Grundig GU15WDT TV - Amazon - Co.uk - Computers & AccessoriesDocument4 pagesPower Supply Board 860-AB0-P150BTLTA-2H For Grundig GU15WDT TV - Amazon - Co.uk - Computers & AccessoriesIssa BakariNo ratings yet
- Process Costing: Managerial Accounting: The Cornerstone of Business Decisions, 4eDocument72 pagesProcess Costing: Managerial Accounting: The Cornerstone of Business Decisions, 4eAndrea Florence Guy VidalNo ratings yet
- Desortment Of: GturationDocument4 pagesDesortment Of: GturationEdemay CornicoNo ratings yet
- Z 600Document12 pagesZ 600Enrique AriasNo ratings yet