You might also like
- Cheat SheetDocument4 pagesCheat SheetjelmoodNo ratings yet
- (Ebook - PDF) Untold Windows Tips and Secrets (Ankit Fadia)Document22 pages(Ebook - PDF) Untold Windows Tips and Secrets (Ankit Fadia)nimitkhanna7100% (1)
- (Ebook - PDF) Untold Windows Tips and Secrets (Ankit Fadia)Document22 pages(Ebook - PDF) Untold Windows Tips and Secrets (Ankit Fadia)nimitkhanna7100% (1)
- Algorithm For Matrix Addition-1Document5 pagesAlgorithm For Matrix Addition-1m azfar tariq0% (1)
- Rarefied Gas Dynamics - DSMC CourseDocument50 pagesRarefied Gas Dynamics - DSMC CourseyicdooNo ratings yet
- Seminar ON Least Cost Method AND North West Corner Method: Presented byDocument46 pagesSeminar ON Least Cost Method AND North West Corner Method: Presented byMonjit DuttaNo ratings yet
- Introduction to Information Theory's Noisy Channel Coding TheoremDocument6 pagesIntroduction to Information Theory's Noisy Channel Coding TheoremasNo ratings yet
- CH 7Document68 pagesCH 7Murali VickyNo ratings yet
- NotesDocument32 pagesNotesGiane HiginoNo ratings yet
- CodingDocument61 pagesCodingInacia ZanoNo ratings yet
- 1 MergedDocument182 pages1 MergedYash kumarNo ratings yet
- Homework 4 SolutionsDocument9 pagesHomework 4 SolutionsAmit PatelNo ratings yet
- A Mathematical Theory of Communication: by C.E.Shannon Presented by Ling ShiDocument10 pagesA Mathematical Theory of Communication: by C.E.Shannon Presented by Ling ShimahRastgooNo ratings yet
- Discrete Memory Less ChannelDocument68 pagesDiscrete Memory Less ChannelshakeelsalamatNo ratings yet
- Itc0809 Homework7Document5 pagesItc0809 Homework7Refka MansouryNo ratings yet
- Report Lucas Slot Sebastian ZurDocument13 pagesReport Lucas Slot Sebastian ZurRani JibhekarNo ratings yet
- EE 121 - Introduction To Digital Communications Final Exam Practice ProblemsDocument4 pagesEE 121 - Introduction To Digital Communications Final Exam Practice ProblemsNowshin AlamNo ratings yet
- Eco Survey 2017-18 SummaryDocument1 pageEco Survey 2017-18 SummarySarojkumar BhosleNo ratings yet
- Channel Coding: Reliable Communication Through Noisy ChannelsDocument23 pagesChannel Coding: Reliable Communication Through Noisy ChannelsVikranth VikiNo ratings yet
- Introduction to Information Theory: Channel Capacity and ModelsDocument30 pagesIntroduction to Information Theory: Channel Capacity and ModelsRekha YadavNo ratings yet
- 6441 Lecture 17Document17 pages6441 Lecture 17logrepository1No ratings yet
- Shannon's theorem for noisy channelsDocument7 pagesShannon's theorem for noisy channelsSoham PalNo ratings yet
- Parks Mcclellan Fir Filter Design 3Document9 pagesParks Mcclellan Fir Filter Design 3nitesh mudgalNo ratings yet
- L9,10, L11 - Module 3 Channel Models and CapacityDocument40 pagesL9,10, L11 - Module 3 Channel Models and CapacityMarkkandan ShanmugavelNo ratings yet
- 28.1 Coding: Shannon's TheoremDocument7 pages28.1 Coding: Shannon's Theoremجلال عواد كاظم جودةNo ratings yet
- MIMO Channel CapacityDocument9 pagesMIMO Channel CapacityGendyNo ratings yet
- Different Integration FormulasDocument11 pagesDifferent Integration Formulasnoman2020No ratings yet
- Capacity Convex OptDocument15 pagesCapacity Convex OptTu Chin HungNo ratings yet
- Quiz - 1: EC60128: Linear Algebra and Error Control Techniques Amitalok J. Budkuley (Amitalok@ece - Iitkgp.ac - In)Document5 pagesQuiz - 1: EC60128: Linear Algebra and Error Control Techniques Amitalok J. Budkuley (Amitalok@ece - Iitkgp.ac - In)sharan mouryaNo ratings yet
- Statistical and Computational Phase Transitions in Spiked Tensor EstimationDocument17 pagesStatistical and Computational Phase Transitions in Spiked Tensor EstimationAlessio GagliardiNo ratings yet
- Notes 7Document3 pagesNotes 7goofyshowNo ratings yet
- Channel Coding: - Channel Capacity Channel Capacity, C Is Defined AsDocument11 pagesChannel Coding: - Channel Capacity Channel Capacity, C Is Defined AsHarshaNo ratings yet
- Digital Wireless Communications: Spring 2021 Homework Set 2Document2 pagesDigital Wireless Communications: Spring 2021 Homework Set 2Cameron SolomonNo ratings yet
- Channel Capacity and ModelsDocument30 pagesChannel Capacity and ModelsAshley SeesurunNo ratings yet
- A Short Introduction to Channel CodingDocument21 pagesA Short Introduction to Channel CodingDspNo ratings yet
- ECE 771 Lecture 10 - The Gaussian ChannelDocument9 pagesECE 771 Lecture 10 - The Gaussian ChannelbabbouzzaNo ratings yet
- Channel Capacity PDFDocument30 pagesChannel Capacity PDFRajasekhar MadithatiNo ratings yet
- Complexity Theory and CryptographyDocument7 pagesComplexity Theory and CryptographyOprea RebecaNo ratings yet
- Assignment III PDFDocument2 pagesAssignment III PDFprince sachanNo ratings yet
- Network Information Theory CapacityDocument30 pagesNetwork Information Theory CapacityviniciusvkdlimaNo ratings yet
- Lagrange IntepolationDocument10 pagesLagrange IntepolationceanilNo ratings yet
- Gaussian Channel: I 2 I I IDocument26 pagesGaussian Channel: I 2 I I ItjthegreatNo ratings yet
- Jan PDFDocument18 pagesJan PDFMEGALA PNo ratings yet
- CH 11Document64 pagesCH 11marcoteran007No ratings yet
- EE7101 Handout 5 - Data Compression TechniquesDocument6 pagesEE7101 Handout 5 - Data Compression TechniquesSuraj TyagiNo ratings yet
- Discrete Memoryless Channel and Its Capacity TutorialDocument16 pagesDiscrete Memoryless Channel and Its Capacity TutorialAnkur AgarwalNo ratings yet
- E2 201: Information Theory (2019) Homework 4: Instructor: Himanshu TyagiDocument3 pagesE2 201: Information Theory (2019) Homework 4: Instructor: Himanshu Tyagis2211rNo ratings yet
- 15ec54 PDFDocument56 pages15ec54 PDFpsych automobilesNo ratings yet
- UMN Info Theory Homework 5Document2 pagesUMN Info Theory Homework 5Sanjay KumarNo ratings yet
- Shannon's Theory of Secure Communication: CSG 252 Fall 2006 Riccardo PucellaDocument23 pagesShannon's Theory of Secure Communication: CSG 252 Fall 2006 Riccardo PucellaG NAVEEN KUMARNo ratings yet
- Consecutive primes in short intervalsDocument82 pagesConsecutive primes in short intervalsSam TaylorNo ratings yet
- 10.1 Gaussian ChannelDocument13 pages10.1 Gaussian ChannelHussain BohraNo ratings yet
- A Problem of Combinatorial Designs Related To Authentication CodesDocument13 pagesA Problem of Combinatorial Designs Related To Authentication Codesmafia criminalNo ratings yet
- Introduction To Information Theory Channel Capacity and ModelsDocument36 pagesIntroduction To Information Theory Channel Capacity and ModelssasirekaarumugamNo ratings yet
- Entropy 2Document3 pagesEntropy 2HarshaNo ratings yet
- EECS 121 Lecture 7 - Intro to Affine and Linear CodesDocument9 pagesEECS 121 Lecture 7 - Intro to Affine and Linear CodespyaridadaNo ratings yet
- CT111: Introduction To Communication SystemsDocument3 pagesCT111: Introduction To Communication Systemskngngn bfbfdbfNo ratings yet
- Introduction To Information Theory Channel Capacity and ModelsDocument36 pagesIntroduction To Information Theory Channel Capacity and ModelsSunil SharmaNo ratings yet
- Lecture 18: Gaussian Channel, Parallel Channels and Rate-Distortion TheoryDocument7 pagesLecture 18: Gaussian Channel, Parallel Channels and Rate-Distortion TheoryHussain BohraNo ratings yet
- Statistical Digital Signal Processing and Modeling Exam November 2017Document3 pagesStatistical Digital Signal Processing and Modeling Exam November 2017Alexander LouwerseNo ratings yet
- LDPC-optimizationDocument32 pagesLDPC-optimizationĐặng Hoài SơnNo ratings yet
- InfTh Vorl eDocument96 pagesInfTh Vorl eShamo Dalbvajan PiqueNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- The Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64From EverandThe Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64No ratings yet
- Block Matching Algorithms For Motion EstimationDocument6 pagesBlock Matching Algorithms For Motion EstimationApoorva JagadeeshNo ratings yet
- Optimal Control With SetpointDocument2 pagesOptimal Control With SetpointShashank KushwahNo ratings yet
- UGTAshipCircular Sem1 1601Document1 pageUGTAshipCircular Sem1 1601Shashank KushwahNo ratings yet
- EEL707 - Multimedia Systems: Assignment 2Document4 pagesEEL707 - Multimedia Systems: Assignment 2Shashank KushwahNo ratings yet
- Assignment 1. Software LabDocument1 pageAssignment 1. Software LabShashank KushwahNo ratings yet
- Lecture6 PDFDocument9 pagesLecture6 PDFRaman GoyalNo ratings yet
- Minor 1Document12 pagesMinor 1Shashank KushwahNo ratings yet
- DIP Assignment 1: General InstructionsDocument1 pageDIP Assignment 1: General InstructionsShashank KushwahNo ratings yet
- Envelope Recovery Envelope Recovery Envelope Recovery Envelope RecoveryDocument12 pagesEnvelope Recovery Envelope Recovery Envelope Recovery Envelope RecoveryShashank KushwahNo ratings yet
- Synchronous Machines Theory PDFDocument4 pagesSynchronous Machines Theory PDFRavinder SharmaNo ratings yet
- EEP702 Software LabDocument6 pagesEEP702 Software LabShashank KushwahNo ratings yet
- EEP 201: Digital Electronic Circuits LaboratoryDocument1 pageEEP 201: Digital Electronic Circuits LaboratoryShashank KushwahNo ratings yet
- Ram Ke Naam-ReviewDocument2 pagesRam Ke Naam-ReviewShashank KushwahNo ratings yet
- Experiment 1: Standing Wave and VSWR Measurement of A Given LoadDocument4 pagesExperiment 1: Standing Wave and VSWR Measurement of A Given LoadShashank KushwahNo ratings yet
- Radiation Pattern PDFDocument6 pagesRadiation Pattern PDFShashank KushwahNo ratings yet
- Ram Ke Naam - ReviewDocument2 pagesRam Ke Naam - ReviewShashank KushwahNo ratings yet
- Fabricate Patch Antenna for 5GHzDocument2 pagesFabricate Patch Antenna for 5GHzShashank KushwahNo ratings yet
- UPSC Civil Services Exam SyllabusDocument231 pagesUPSC Civil Services Exam Syllabusvssridhar99100% (1)
- Unknown Impedance MeasurementDocument5 pagesUnknown Impedance MeasurementShashank KushwahNo ratings yet
- Computer Architecture Slides 1Document27 pagesComputer Architecture Slides 1Shashank KushwahNo ratings yet
- CSL102Document778 pagesCSL102Shashank KushwahNo ratings yet
- Major 1Document1 pageMajor 1Shashank KushwahNo ratings yet
- Basic Power Electronics Concepts - Ozipineci - ORNLDocument25 pagesBasic Power Electronics Concepts - Ozipineci - ORNLdionisio_ant5813No ratings yet
- De Novo Programming: Ha Thi Xuan Chi, PHDDocument21 pagesDe Novo Programming: Ha Thi Xuan Chi, PHDhusterNo ratings yet
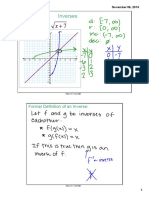
- Inverse Functions NotesDocument6 pagesInverse Functions NotesROHAN NARAYANNo ratings yet
- C# Keywords and Definitions With ExamplesDocument130 pagesC# Keywords and Definitions With Examplesrafiulalhasan50% (2)
- C&DS Unit-VI (Searching and Sorting)Document8 pagesC&DS Unit-VI (Searching and Sorting)N. Janaki RamNo ratings yet
- The Similarities and Differences Between Polynomials and IntegersDocument23 pagesThe Similarities and Differences Between Polynomials and IntegersGrant AtoyanNo ratings yet
- Lecture 7 - RecursionDocument3 pagesLecture 7 - Recursionmalaika zulfiqarNo ratings yet
- Cambridge International AS & A Level: Computer Science 9608/23Document24 pagesCambridge International AS & A Level: Computer Science 9608/23Shakila.D Raks PallikkoodamNo ratings yet
- Wikipedia Data StructuresDocument377 pagesWikipedia Data StructuresSamveen Gulati100% (1)
- Artificial Intelligence: Beyond Classical SearchDocument29 pagesArtificial Intelligence: Beyond Classical SearchPrasidha PrabhuNo ratings yet
- DSP Report Lab3 OfficialDocument11 pagesDSP Report Lab3 Officialbao.pham27sayzeNo ratings yet
- 2021 Lecture08 FirstOrderLogic PDFDocument97 pages2021 Lecture08 FirstOrderLogic PDFMinh ChâuNo ratings yet
- Digital Logic Fundamentals ExplainedDocument24 pagesDigital Logic Fundamentals ExplainedTrần Thái SơnNo ratings yet
- Big-O Performance Analysis: - Computer: - Compiler: - DataDocument13 pagesBig-O Performance Analysis: - Computer: - Compiler: - Datayahya nur marfuadNo ratings yet
- 07 ArraysDocument16 pages07 ArraysSharath NaikNo ratings yet
- Part 2Document165 pagesPart 2msuresh79No ratings yet
- Learning by Asking: Decision Tree GuideDocument22 pagesLearning by Asking: Decision Tree GuideAnilNo ratings yet
- Assignment 7 (Sol.) : Reinforcement LearningDocument3 pagesAssignment 7 (Sol.) : Reinforcement Learningsachin bhadangNo ratings yet
- CNN Image ClassificationDocument27 pagesCNN Image Classificationmember2 mtriNo ratings yet
- Newton's Form of InterpolationDocument34 pagesNewton's Form of Interpolationحمامة السلامNo ratings yet
- Maximize Revenue Linear Program Airline TicketsDocument5 pagesMaximize Revenue Linear Program Airline TicketsNguyen Thi Hong HanhNo ratings yet
- Cquestions (2) - RemovedDocument1 pageCquestions (2) - RemovedparthipanphdNo ratings yet
- Bottom View Binary Tree in 40 CharactersDocument15 pagesBottom View Binary Tree in 40 CharactersAlok Kumar HotaNo ratings yet
- CE 205: Numerical Methods: Dr. Tanvir Ahmed Assistant ProfessorDocument25 pagesCE 205: Numerical Methods: Dr. Tanvir Ahmed Assistant ProfessorObaidurRahamanNo ratings yet
- H446 02 Mark Scheme Set 1Document32 pagesH446 02 Mark Scheme Set 1howeqkNo ratings yet
- Multiple Choice Answer LinksDocument10 pagesMultiple Choice Answer LinksJoseph RefuerzoNo ratings yet
- Codechef Assignment 5Document5 pagesCodechef Assignment 5Kumar SanuNo ratings yet
- Learning Techniques For NILMTKDocument9 pagesLearning Techniques For NILMTKUMARNo ratings yet
- Bellman Ford AlgorithmDocument17 pagesBellman Ford AlgorithmKrishna VijaywargiyNo ratings yet