0% found this document useful (0 votes)
47 views5 pagesLogistic Regression Analysis in SPSS
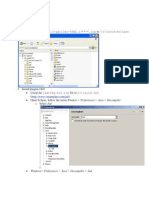
The document describes using logistic regression to analyze factors related to CHC_ser_use using data from the Field SPSS.sav dataset. It finds that the variables Land_cultivated, Loan_avai, and Easeoffinance are significant predictors of CHC_ser_use based on the Variables not in the Equation output. The full logistic regression model correctly classifies 90% of cases according to the Classification Table.
Uploaded by
Gaurav SinghalCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as RTF, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
47 views5 pagesLogistic Regression Analysis in SPSS
The document describes using logistic regression to analyze factors related to CHC_ser_use using data from the Field SPSS.sav dataset. It finds that the variables Land_cultivated, Loan_avai, and Easeoffinance are significant predictors of CHC_ser_use based on the Variables not in the Equation output. The full logistic regression model correctly classifies 90% of cases according to the Classification Table.
Uploaded by
Gaurav SinghalCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as RTF, PDF, TXT or read online on Scribd