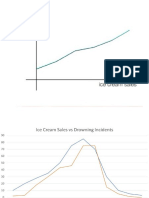
You might also like
- Medical Student Well-Being: An Essential GuideFrom EverandMedical Student Well-Being: An Essential GuideDana ZappettiNo ratings yet
- Principles and Uses of Surveys, Experiments, and Observational StudyDocument46 pagesPrinciples and Uses of Surveys, Experiments, and Observational Studysheryl duenasNo ratings yet
- Health Psychology An Introduction To Behavior and Health 8th Edition Brannon Test BankDocument26 pagesHealth Psychology An Introduction To Behavior and Health 8th Edition Brannon Test BankJosephMartinezwgrin100% (10)
- Research Methodology ArihantDocument6 pagesResearch Methodology Arihantaastha jainNo ratings yet
- Epidemiological MethodDocument7 pagesEpidemiological MethodAli Aman QaisarNo ratings yet
- Psych610 r2 Homework Exercise Week7 FinalDocument2 pagesPsych610 r2 Homework Exercise Week7 FinalJessica Paone LaraNo ratings yet
- Design of Experiments & ANOVADocument7 pagesDesign of Experiments & ANOVAvelkus2013No ratings yet
- Normative Case StudyDocument4 pagesNormative Case StudySessylu TalaveraNo ratings yet
- 21.cpsy.34 Research MethodsDocument14 pages21.cpsy.34 Research MethodsVictor YanafNo ratings yet
- Groot # 6 or 7Document29 pagesGroot # 6 or 7Sharan SahotaNo ratings yet
- Introduction To Nursing Research in An Evidence-Based Practice EnvironmentDocument5 pagesIntroduction To Nursing Research in An Evidence-Based Practice EnvironmentAshleyNo ratings yet
- Effects of Anxiety LevelsDocument9 pagesEffects of Anxiety Levelsapi-238107777No ratings yet
- Health PhyscologyDocument4 pagesHealth PhyscologySera SazleenNo ratings yet
- Methods in Behavioral Research Qn.1Document4 pagesMethods in Behavioral Research Qn.1Tonnie KiamaNo ratings yet
- VVV V: V V VVV VVV V VV VVV VV VDocument11 pagesVVV V: V V VVV VVV V VV VVV VV Vnishasadanandam8637No ratings yet
- Descriptive and Experimental Research by GurpreetDocument21 pagesDescriptive and Experimental Research by GurpreetGurpreet Singh WaliaNo ratings yet
- Correlational Research DefinitionDocument23 pagesCorrelational Research DefinitionDon DiazNo ratings yet
- Writting in The ScienceDocument7 pagesWritting in The ScienceSadaamAxmadNo ratings yet
- Is There Logic in The Placebo - LancetDocument3 pagesIs There Logic in The Placebo - LancetAnny AunNo ratings yet
- Observational: Observing Participants. You CannotDocument6 pagesObservational: Observing Participants. You CannotIS99057No ratings yet
- 0005 7916 (95) 00058 5Document9 pages0005 7916 (95) 00058 5zzzzzzNo ratings yet
- Community - 07Document4 pagesCommunity - 07Mohammad AlrefaiNo ratings yet
- Chap 5 ModuleDocument18 pagesChap 5 ModuledzikrydsNo ratings yet
- Behavioral Control of OvereatingDocument9 pagesBehavioral Control of OvereatingDario FriasNo ratings yet
- Massage Therapy EffectsDocument12 pagesMassage Therapy EffectsEkalevi FahlepieNo ratings yet
- Exercisecommitment ResearchDocument14 pagesExercisecommitment Researchapi-282525755No ratings yet
- Use and Abuse of AncovaDocument6 pagesUse and Abuse of Ancovaajax_telamonioNo ratings yet
- Literature Review Placebo EffectDocument4 pagesLiterature Review Placebo Effectfohudenyfeh2100% (1)
- RM Theory Assignment 2Document13 pagesRM Theory Assignment 2sheppyNo ratings yet
- Kritisi Artikel - Ni Nengah Susilawati - 152191105 - BDocument5 pagesKritisi Artikel - Ni Nengah Susilawati - 152191105 - BShilaNo ratings yet
- JabaextratherapyDocument12 pagesJabaextratherapyLetyCaMaNo ratings yet
- 4.2 The-Research-Endeavor Part 2Document5 pages4.2 The-Research-Endeavor Part 2janeclou villasNo ratings yet
- Test Bank For Biostatistics An Applied Introduction For The Public Health Practitioner 1st EditionDocument36 pagesTest Bank For Biostatistics An Applied Introduction For The Public Health Practitioner 1st Editionoscines.filicide.qzie100% (41)
- An Update On Empirically Validated Therapies (1997) PDFDocument9 pagesAn Update On Empirically Validated Therapies (1997) PDFIgnacia HuckeNo ratings yet
- Variants of Exposure and Response PreventionDocument18 pagesVariants of Exposure and Response PreventionMarta CerdáNo ratings yet
- Meta-Analysis and SubgroupsDocument10 pagesMeta-Analysis and SubgroupsDinda Anindita SalsabillaNo ratings yet
- Stats 6Document25 pagesStats 6api-294156876No ratings yet
- A Meta Analysis of Play Therapy Outcomes PDFDocument16 pagesA Meta Analysis of Play Therapy Outcomes PDFAron MautnerNo ratings yet
- Experimental ResearchDocument38 pagesExperimental ResearchSuvrhy MuhajjiNo ratings yet
- 2017 - Mar - The Placebo and Nocebo Phenomena. Their Clinical Management and Impact On Treatment Outcomes (Read - MB)Document10 pages2017 - Mar - The Placebo and Nocebo Phenomena. Their Clinical Management and Impact On Treatment Outcomes (Read - MB)brumontoroNo ratings yet
- In-Methodology & DesignDocument45 pagesIn-Methodology & Designnica pidlaoanNo ratings yet
- CursusDocument139 pagesCursusAnh ThanhNo ratings yet
- Identifying Research Study Designs Google Docs PDFDocument10 pagesIdentifying Research Study Designs Google Docs PDFMia NNo ratings yet
- 2016 Article 1018Document12 pages2016 Article 1018Aditya Lovindo SuwarnoNo ratings yet
- AliDocument3 pagesAliAmare TarekegnNo ratings yet
- Ekkekakis Acevedo 2006Document23 pagesEkkekakis Acevedo 2006Aprendendo com o Lucas e com o DitoNo ratings yet
- (2017) Evolution of Cognitive-BehavioralDocument11 pages(2017) Evolution of Cognitive-BehavioralSammyr AbrãoNo ratings yet
- 7a EpidemiologyDocument15 pages7a EpidemiologyLowell CuffNo ratings yet
- A Level Psycology Unit 3 Exam Studies.173697407Document47 pagesA Level Psycology Unit 3 Exam Studies.173697407VF MariaNo ratings yet
- Quantitative Research DesignDocument4 pagesQuantitative Research DesignReazt YhanieNo ratings yet
- Lecture 1 Definitions & Terminologies in Experimental DesignDocument11 pagesLecture 1 Definitions & Terminologies in Experimental DesignMalvika PatelNo ratings yet
- Intromedii Artigo t21 JunhoDocument15 pagesIntromedii Artigo t21 JunhoMonika JonesNo ratings yet
- Medical Statistics Exersice 2 PDFDocument4 pagesMedical Statistics Exersice 2 PDFНурпери НуралиеваNo ratings yet
- Lecture Notes: Take Note! Characteristics of A Good Experimental DesignDocument5 pagesLecture Notes: Take Note! Characteristics of A Good Experimental Designmarvin jayNo ratings yet
- Reserach MethodsDocument5 pagesReserach MethodsMike MuchimbaNo ratings yet
- Article 3Document11 pagesArticle 3Agatha AgboNo ratings yet
- Capitulo2-What Caracterizes Effective TherapistsDocument17 pagesCapitulo2-What Caracterizes Effective TherapistsMiriam Marques0% (1)
- Persons Case Formulation ArticleDocument11 pagesPersons Case Formulation ArticleMarco Sousa100% (2)
- Lectures (01-02) (Week 1)Document6 pagesLectures (01-02) (Week 1)Fatima HassanNo ratings yet
- Storytelling and Data in Numerical Simulations: Visual VisualizationDocument68 pagesStorytelling and Data in Numerical Simulations: Visual VisualizationmopliqNo ratings yet
- Unit-12 SELECTION OF VARIABLESDocument17 pagesUnit-12 SELECTION OF VARIABLESmopliqNo ratings yet
- Full 148Document12 pagesFull 148mopliqNo ratings yet
- Unit-13 TREND COMPONENT ANALYSIDocument28 pagesUnit-13 TREND COMPONENT ANALYSImopliqNo ratings yet
- Unit-16 TIME SERIES MODELSDocument19 pagesUnit-16 TIME SERIES MODELSmopliqNo ratings yet
- R Graphics4Document51 pagesR Graphics4mopliqNo ratings yet
- Unit 15 KruskalDocument16 pagesUnit 15 KruskalmopliqNo ratings yet
- Errors and Di Culties in Understanding Elementary Statistical ConceptsDocument20 pagesErrors and Di Culties in Understanding Elementary Statistical ConceptsmopliqNo ratings yet
- R Graphics2Document55 pagesR Graphics2mopliqNo ratings yet
- Milanovic Beijing18 Rome19Document70 pagesMilanovic Beijing18 Rome19mopliqNo ratings yet
- Estado: Oaxaca: Municipio Clave Municipal Liga ElectrónicaDocument31 pagesEstado: Oaxaca: Municipio Clave Municipal Liga ElectrónicamopliqNo ratings yet
- Estado: Puebla: Municipio Clave Municipal Liga ElectrónicaDocument13 pagesEstado: Puebla: Municipio Clave Municipal Liga ElectrónicamopliqNo ratings yet
- Package RCMDR': January 6, 2022Document46 pagesPackage RCMDR': January 6, 2022mopliqNo ratings yet
- Chapter 2Document50 pagesChapter 2mopliqNo ratings yet
- Instructor: MATH 40 Spring 2007: STATISTICSDocument4 pagesInstructor: MATH 40 Spring 2007: STATISTICSmopliqNo ratings yet
- Losario Nglés Spañol: BORRADOR (Dec. 2002)Document30 pagesLosario Nglés Spañol: BORRADOR (Dec. 2002)mopliqNo ratings yet
- Polish Economics and The Polish Economy:: A Study For The Twentieth Anniversary of Transition in PolandDocument17 pagesPolish Economics and The Polish Economy:: A Study For The Twentieth Anniversary of Transition in PolandmopliqNo ratings yet
- Review of Esu Yoruba God Power and The IDocument7 pagesReview of Esu Yoruba God Power and The IBoris MilovicNo ratings yet
- Tarot SpreadsDocument6 pagesTarot SpreadssueNo ratings yet
- Centrifugal ForceDocument5 pagesCentrifugal Forceasd3e23No ratings yet
- 19Document24 pages19physicsdocsNo ratings yet
- SA200Document35 pagesSA200Laura D'souzaNo ratings yet
- Bannari Amman Sugars LTD Vs Commercial Tax Officer and OthersDocument15 pagesBannari Amman Sugars LTD Vs Commercial Tax Officer and Othersvrajamabl100% (2)
- Lesson PlanDocument4 pagesLesson PlanWizza Mae L. Coralat100% (2)
- ADEC - Al Yasat Privae School 2016 2017Document22 pagesADEC - Al Yasat Privae School 2016 2017Edarabia.comNo ratings yet
- Smeijsters, H. and Clever, G. (2006) - The Treatment of Aggression Using Arts Therapies in Forensi PDFDocument22 pagesSmeijsters, H. and Clever, G. (2006) - The Treatment of Aggression Using Arts Therapies in Forensi PDFaleksandra_radevicNo ratings yet
- 01 Sociological PerspectiveDocument42 pages01 Sociological PerspectiverazmirarazakNo ratings yet
- Share PRED-1313.-Module-2.-CP-3.-for-uploading PDFDocument13 pagesShare PRED-1313.-Module-2.-CP-3.-for-uploading PDFChristian Rhey NebreNo ratings yet
- UntitledDocument2 pagesUntitledmdey999No ratings yet
- MechanicalDocument5 pagesMechanicalGaurav MakwanaNo ratings yet
- Journal 2012Document268 pagesJournal 2012KetevanKorinteliNo ratings yet
- The Just Shall Live by FaithDocument34 pagesThe Just Shall Live by FaithGaryGarcianoBasas100% (1)
- Public AdminDocument5 pagesPublic AdminMuhammad Iqbal ZamirNo ratings yet
- Untitled 5Document5 pagesUntitled 5Boshra BoshraNo ratings yet
- Introduction To Clinical Health PsychologyDocument271 pagesIntroduction To Clinical Health Psychologyshafijan100% (1)
- GROUP ASSIGNMENT Managerial EconomicsDocument26 pagesGROUP ASSIGNMENT Managerial Economicsmahedre100% (1)
- Team Cohesion in Water PoloDocument19 pagesTeam Cohesion in Water PoloEween100% (2)
- 1.coulomb Law and Superposition PrincipleDocument5 pages1.coulomb Law and Superposition PrincipleArjunNo ratings yet
- 8 Pillars of Prosperity - Jim AllenDocument133 pages8 Pillars of Prosperity - Jim AllenReynaldo EstomataNo ratings yet
- Thematic TeachingDocument20 pagesThematic TeachingClea Allosa JunillerNo ratings yet
- QuranDocument4 pagesQuranmohiNo ratings yet
- Philippine Values in ContextDocument11 pagesPhilippine Values in ContextSteve B. Salonga100% (1)
- Jung in The Valley of Diamonds Unus Mundus TheDocument61 pagesJung in The Valley of Diamonds Unus Mundus The_the_bridge_No ratings yet
- Recognising The Mechanics Used in Reading Text: Cohesive Devices and TransitionsDocument31 pagesRecognising The Mechanics Used in Reading Text: Cohesive Devices and TransitionsAnonymous 8Ksdh5eNo ratings yet
- Nature and Nurture: Chapter 3 99-133Document18 pagesNature and Nurture: Chapter 3 99-133yummywords1254100% (1)
- SW Engg.Document50 pagesSW Engg.Ajay ChandranNo ratings yet
- Motivational Interviewing ManualDocument206 pagesMotivational Interviewing ManualSean Cho100% (1)