You might also like
- SVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationDocument11 pagesSVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationChris DiehlNo ratings yet
- Ex Lecture1Document2 pagesEx Lecture1AlNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Solutions Problem Set 1Document7 pagesSolutions Problem Set 1sanketjaiswalNo ratings yet
- 1 Introduction To Optimization: 1.1 Notations and DefinitionsDocument4 pages1 Introduction To Optimization: 1.1 Notations and DefinitionsSamuel Alfonzo Gil BarcoNo ratings yet
- B-Spline Techniques For Volatility Modeling: To Cite This VersionDocument20 pagesB-Spline Techniques For Volatility Modeling: To Cite This VersionStephane MysonaNo ratings yet
- EconometricsII ExercisesDocument27 pagesEconometricsII ExercisesAkriti TrivediNo ratings yet
- EE 542 HEV Assignment 1Document2 pagesEE 542 HEV Assignment 1Kêšhãv ŠîñghNo ratings yet
- Week5 SWIDocument3 pagesWeek5 SWIAditya PaharwaNo ratings yet
- Worksheet Maths (M.SC.)Document6 pagesWorksheet Maths (M.SC.)shireenNo ratings yet
- Balas 2018Document11 pagesBalas 2018Raj PrabuNo ratings yet
- Dis11 SolDocument5 pagesDis11 SolMichael ARKNo ratings yet
- Cs 229, Public Course Problem Set #2 Solutions: Kernels, SVMS, and TheoryDocument8 pagesCs 229, Public Course Problem Set #2 Solutions: Kernels, SVMS, and Theorysuhar adiNo ratings yet
- Tugas MTKDocument24 pagesTugas MTKGhalih Hakiki KavisaNo ratings yet
- ECON 809: Problem Set 1Document18 pagesECON 809: Problem Set 1Phan Van NamNo ratings yet
- Topic 5Document32 pagesTopic 5hmood966No ratings yet
- Ass 1Document3 pagesAss 1Vibhanshu LodhiNo ratings yet
- Attachment 1Document5 pagesAttachment 1anthony.onyishi.242680No ratings yet
- Practical Work N. 3 (Travaux Pratiques N. 3) : Introduction To Machine Learning: Application To GeosciencesDocument4 pagesPractical Work N. 3 (Travaux Pratiques N. 3) : Introduction To Machine Learning: Application To GeosciencesSylia BenNo ratings yet
- Clustering With Gradient Descent: 1 PerformanceDocument4 pagesClustering With Gradient Descent: 1 PerformanceChristine StraubNo ratings yet
- Lecture Notes SVMDocument4 pagesLecture Notes SVMLilia XaNo ratings yet
- Lecture Notes SVMDocument4 pagesLecture Notes SVMSreeprada VNo ratings yet
- The Dirichlet BVP For A Rectangle: U U (X, 0) F U (X, B) F X A, U (0, Y) G U (A, Y) G y BDocument5 pagesThe Dirichlet BVP For A Rectangle: U U (X, 0) F U (X, B) F X A, U (0, Y) G U (A, Y) G y BAkash KumarNo ratings yet
- p6-REF-0 JMLRDocument16 pagesp6-REF-0 JMLRSELVAKUMAR RNo ratings yet
- Final Exam Solutions: N I I TDocument19 pagesFinal Exam Solutions: N I I TPengintaiNo ratings yet
- Chapter 3, Lecture 6: Broyden's Method: This Document Comes From The Math 484 Course WebpageDocument5 pagesChapter 3, Lecture 6: Broyden's Method: This Document Comes From The Math 484 Course Webpageparadoja_hiperbolicaNo ratings yet
- Homework2 v1.0Document5 pagesHomework2 v1.0royadaneshi2001No ratings yet
- Mathematics For Business: Non-Linear EquationDocument25 pagesMathematics For Business: Non-Linear Equationbobby510No ratings yet
- Support Vector Machine Classification Algorithm and Its ApplicationDocument8 pagesSupport Vector Machine Classification Algorithm and Its Application0191720003 ELIAS ANTONIO BELLO LEON ESTUDIANTE ACTIVONo ratings yet
- Machine Learning Week 3Document4 pagesMachine Learning Week 3AnandhsNo ratings yet
- Kernel SVM For Image ClassificationDocument20 pagesKernel SVM For Image ClassificationAriake SwyceNo ratings yet
- MIT6 832s09 Exam01 PracticeDocument4 pagesMIT6 832s09 Exam01 PracticePiero RaurauNo ratings yet
- An Introduction To Support Vector Machines: Biplab BanerjeeDocument31 pagesAn Introduction To Support Vector Machines: Biplab BanerjeeAkshat sharmaNo ratings yet
- cs229 Notes7aDocument3 pagescs229 Notes7achrisNo ratings yet
- DNN Cluster S2 22 MidSem RegularDocument6 pagesDNN Cluster S2 22 MidSem RegularrahulsgaykeNo ratings yet
- Ada Module 3 NotesDocument40 pagesAda Module 3 NotesLokko PrinceNo ratings yet
- Machine Learning: BackpropagationDocument24 pagesMachine Learning: BackpropagationArdiansyah Mochamad NugrahaNo ratings yet
- Assignment 5: E1 244 - Detection and Estimation Theory (Jan 2023) Due Date: April 02, 2023 Total Marks: 55Document2 pagesAssignment 5: E1 244 - Detection and Estimation Theory (Jan 2023) Due Date: April 02, 2023 Total Marks: 55samyak jainNo ratings yet
- hw03 1 02 SolutionsDocument3 pageshw03 1 02 SolutionsranvNo ratings yet
- Mid Prac SolnDocument6 pagesMid Prac SolnNguyễn Bá PhúcNo ratings yet
- Chapter 4Document10 pagesChapter 4Emanuel DiegoNo ratings yet
- Ait AllDocument83 pagesAit AllramasaiNo ratings yet
- Support Vector Machines For Classification and RegressionDocument8 pagesSupport Vector Machines For Classification and RegressionYiwei ChenNo ratings yet
- coursSVM Versionlongue 20Document70 pagescoursSVM Versionlongue 20dorianNo ratings yet
- Computer Vision MCQ's For InterviewDocument12 pagesComputer Vision MCQ's For InterviewMallikarjun patilNo ratings yet
- Notes 3Document8 pagesNotes 3Sriram BalasubramanianNo ratings yet
- HW 4Document5 pagesHW 422022510 Nguyễn Công HiếuNo ratings yet
- Numerical Linear Algebra University of Edinburgh Past Paper 2021-2022Document5 pagesNumerical Linear Algebra University of Edinburgh Past Paper 2021-2022Jonathan SamuelsNo ratings yet
- HW02 Sol - KNN DTDocument8 pagesHW02 Sol - KNN DTghukasyans033No ratings yet
- Unit 1 - Efficient Market HypothesisDocument10 pagesUnit 1 - Efficient Market HypothesisKrishnaPrasanna vankayalaNo ratings yet
- Laibson Notes 2013 0Document54 pagesLaibson Notes 2013 0geetagarg1No ratings yet
- Good Luck!: Massachusetts Institute of TechnologyDocument8 pagesGood Luck!: Massachusetts Institute of TechnologyMuller YeneNo ratings yet
- Workshop6 SolutionsDocument3 pagesWorkshop6 SolutionsforspamreceivalNo ratings yet
- CS335 Lab6Document7 pagesCS335 Lab6YASH PATILNo ratings yet
- Building Your Deep Neural Network - Step by Step v8 PDFDocument44 pagesBuilding Your Deep Neural Network - Step by Step v8 PDFjiaNo ratings yet
- HW3Document3 pagesHW3angy_1123No ratings yet
- SoftFRAC Matlab Library For RealizationDocument10 pagesSoftFRAC Matlab Library For RealizationKotadai Le ZKNo ratings yet
- MAT 461/561: 5.1 Stationary Iterative MethodsDocument4 pagesMAT 461/561: 5.1 Stationary Iterative MethodsDebisaNo ratings yet
- Comparing Hidden Markov Models and Long Short Term Memory Neural Networks For Learning Action RepresentationsDocument12 pagesComparing Hidden Markov Models and Long Short Term Memory Neural Networks For Learning Action Representationssun_917443954No ratings yet
- Bayesian InferenceDocument28 pagesBayesian Inferencesun_917443954No ratings yet
- What Is Data Science? Probability Overview Descriptive StatisticsDocument10 pagesWhat Is Data Science? Probability Overview Descriptive StatisticsMauricioRojasNo ratings yet
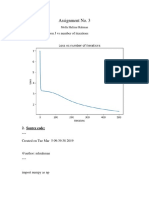
- Assignment No. 3: 1. Plot of Loss Function J Vs Number of IterationsDocument6 pagesAssignment No. 3: 1. Plot of Loss Function J Vs Number of Iterationssun_917443954No ratings yet
- ReadDocument1 pageReadsun_917443954No ratings yet
- Free SF Kingston LicenseDocument1 pageFree SF Kingston Licensesun_917443954No ratings yet
- LEadDocument2 pagesLEadsun_917443954No ratings yet
- Free SF Kingston LicenseDocument1 pageFree SF Kingston Licensesun_917443954No ratings yet
- HW1Document4 pagesHW1sun_917443954No ratings yet
- CSCE 5063-001: Assignment 2: 1 Implementation of SVM Via Gradient DescentDocument5 pagesCSCE 5063-001: Assignment 2: 1 Implementation of SVM Via Gradient Descentsun_917443954No ratings yet
- An Overview and Comparative Analysis of Recurrent Neural Networks For Short Term Load ForecastingDocument41 pagesAn Overview and Comparative Analysis of Recurrent Neural Networks For Short Term Load ForecastingPietroManzoniNo ratings yet
- Beyond A Gaussian Denoiser: Residual Learning of Deep CNN For Image DenoisingDocument14 pagesBeyond A Gaussian Denoiser: Residual Learning of Deep CNN For Image Denoisingvishnukiran goliNo ratings yet
- Unconstrained Optimization III: Topics We'll CoverDocument3 pagesUnconstrained Optimization III: Topics We'll CoverMohammadAliNo ratings yet
- Comparative Study of Optimization Algorithm in Deep CNN-Based Model For Sign Language Recognition - SpringerLinkDocument5 pagesComparative Study of Optimization Algorithm in Deep CNN-Based Model For Sign Language Recognition - SpringerLinkRajesh RajanNo ratings yet
- cs224n 2023 Lecture01 Wordvecs1Document40 pagescs224n 2023 Lecture01 Wordvecs1jon prasetio bawuesNo ratings yet
- Machine Learning BitsDocument28 pagesMachine Learning Bitsvyshnavi100% (2)
- An Introduction To Deep Learning For The Physical LayerDocument13 pagesAn Introduction To Deep Learning For The Physical Layerjun zhaoNo ratings yet
- Daily Dose of Data Science - ArchiveDocument292 pagesDaily Dose of Data Science - ArchiveSeema SinghNo ratings yet
- Cs 224 NDocument128 pagesCs 224 NANH Đỗ QuốcNo ratings yet
- Control Approaches For Magnetic LevitationDocument11 pagesControl Approaches For Magnetic Levitationambachew bizunehNo ratings yet
- Machine Learning Approach For Computing Optical Properties of A Photonic Crystal FiberDocument12 pagesMachine Learning Approach For Computing Optical Properties of A Photonic Crystal FiberfaisalbanNo ratings yet
- Ait401 DL SyllubusDocument13 pagesAit401 DL SyllubusReemaNo ratings yet
- CS229 Lecture Notes: Supervised LearningDocument293 pagesCS229 Lecture Notes: Supervised LearningmahithaNo ratings yet
- Development of A Convolutional Neural Network-Based Ethnicity Classification Model From Facial ImagesDocument6 pagesDevelopment of A Convolutional Neural Network-Based Ethnicity Classification Model From Facial ImagesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 361 Project CodeDocument10 pages361 Project CodeskdlfNo ratings yet
- Deep Learning Tutorial Release 0.1Document173 pagesDeep Learning Tutorial Release 0.1lerhlerhNo ratings yet
- Data Science Lab Assignment: Name: Vemula Yaminee Jyothsna Roll No: 20BM6JP44Document2 pagesData Science Lab Assignment: Name: Vemula Yaminee Jyothsna Roll No: 20BM6JP44Jyothsna VemulaNo ratings yet
- SCSA3015 Deep Learning Unit 4 PDFDocument30 pagesSCSA3015 Deep Learning Unit 4 PDFpooja vikirthiniNo ratings yet
- Applied Sciences: Beyond Stochastic Gradient Descent For Matrix Completion Based Indoor LocalizationDocument21 pagesApplied Sciences: Beyond Stochastic Gradient Descent For Matrix Completion Based Indoor Localizationrafik.zayaniNo ratings yet
- Quick Review of ML Algorithms 139Document5 pagesQuick Review of ML Algorithms 139cheintNo ratings yet
- An Overview of Gradient Descent Optimization Algorithms PDFDocument12 pagesAn Overview of Gradient Descent Optimization Algorithms PDFsharkieNo ratings yet
- POA - Tracker MACHINE LEARNINGDocument48 pagesPOA - Tracker MACHINE LEARNINGOriginal Hybrid100% (1)
- ML Terminologies PDFDocument44 pagesML Terminologies PDFKapildev KumarNo ratings yet
- CS-6777 Liu AbsDocument103 pagesCS-6777 Liu AbsILLA PAVAN KUMAR (PA2013003013042)No ratings yet
- Ml@ok QuestionsDocument16 pagesMl@ok QuestionsINV SHRNo ratings yet
- Latent Factor Analysis For High-Dimensional and Sparse Matrices - YuanDocument99 pagesLatent Factor Analysis For High-Dimensional and Sparse Matrices - YuanJuan RodriguezNo ratings yet
- Natural Language Processing With PyTorch - Build Intelligent Language Applications Using Deep Learning PDFDocument210 pagesNatural Language Processing With PyTorch - Build Intelligent Language Applications Using Deep Learning PDFTornike Yandareli100% (5)
- Classification of Stars, Galaxies and QuasarsDocument8 pagesClassification of Stars, Galaxies and QuasarsInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Applied Sciences: A Waste Classification Method Based On A Multilayer Hybrid Convolution Neural NetworkDocument19 pagesApplied Sciences: A Waste Classification Method Based On A Multilayer Hybrid Convolution Neural NetworkĐức Võ Phạm DuyNo ratings yet
- Lab2 Linear RegressionDocument18 pagesLab2 Linear RegressionJuan Zarate100% (1)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziFrom Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNo ratings yet
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeFrom EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeRating: 4.5 out of 5 stars4.5/5 (69)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)From EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Rating: 4 out of 5 stars4/5 (1)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)
- Midjourney Mastery - The Ultimate Handbook of PromptsFrom EverandMidjourney Mastery - The Ultimate Handbook of PromptsRating: 4.5 out of 5 stars4.5/5 (2)
- The Digital Mind: How Science is Redefining HumanityFrom EverandThe Digital Mind: How Science is Redefining HumanityRating: 4.5 out of 5 stars4.5/5 (2)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)