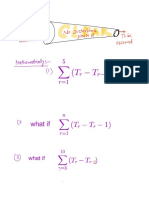
You might also like
- Lec 05 RegularizationDocument77 pagesLec 05 RegularizationMr. CoffeeNo ratings yet
- Of Workshop 11Document39 pagesOf Workshop 11Marc Rovira SacieNo ratings yet
- CSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesDocument93 pagesCSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesRohan BorgalliNo ratings yet
- Action Carv 5Document36 pagesAction Carv 5sanketdange2007No ratings yet
- CS109/Stat121/AC209/E-109 Data Science: Statistical ModelsDocument26 pagesCS109/Stat121/AC209/E-109 Data Science: Statistical Modelsgowtam_raviNo ratings yet
- ICS Architecture (25 Slides)Document26 pagesICS Architecture (25 Slides)Paul MiersNo ratings yet
- XAI (v7)Document40 pagesXAI (v7)appleadNo ratings yet
- Introduction To Support Vector Machines: BTR Workshop Fall 2006Document88 pagesIntroduction To Support Vector Machines: BTR Workshop Fall 2006Helkia PasaribuNo ratings yet
- Luiz Reliability ProjectDocument14 pagesLuiz Reliability ProjectMiro GrulovicNo ratings yet
- The Effect of Event-Driven Models On TheoryDocument3 pagesThe Effect of Event-Driven Models On TheorygarthogNo ratings yet
- Simulation With MatlabDocument36 pagesSimulation With MatlabKamasani PraveenaNo ratings yet
- Review PythonDocument12 pagesReview PythonRachna TomarNo ratings yet
- SalectDocument19 pagesSalectcatiav5123No ratings yet
- Regularization Paths: Trevor Hastie Stanford UniversityDocument28 pagesRegularization Paths: Trevor Hastie Stanford UniversityShreyas PAI GNo ratings yet
- Lec08 490Document4 pagesLec08 490JggNo ratings yet
- cs229 Notes EnsembleDocument7 pagescs229 Notes EnsemblebobNo ratings yet
- Unreal Engine Project Workflow: TwistedDocument14 pagesUnreal Engine Project Workflow: TwistedBacuOanaAlexandraNo ratings yet
- Solver Benchmarking ShellDocument3 pagesSolver Benchmarking ShellToy SoldierNo ratings yet
- Numerical Differentiation: Example. Compute The Derivative of F (X) eDocument5 pagesNumerical Differentiation: Example. Compute The Derivative of F (X) eMars OnairisNo ratings yet
- State Space Search.: Course Home Page Home PageDocument10 pagesState Space Search.: Course Home Page Home PageLukeNo ratings yet
- Proc ImaginiDocument54 pagesProc ImaginiAlexandru EugenNo ratings yet
- Gjoel Svendsen Rendering of Inside PDFDocument187 pagesGjoel Svendsen Rendering of Inside PDFVladeK231No ratings yet
- DSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksDocument13 pagesDSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksHesham HefnyNo ratings yet
- Lecture02a Optimization Annotated PDFDocument23 pagesLecture02a Optimization Annotated PDFNing YangNo ratings yet
- Root Locus and Matlab ProgrammingDocument6 pagesRoot Locus and Matlab Programmingshaista00550% (2)
- Lecture 15: Bayesian Networks III: CS221 / Autumn 2015 / LiangDocument70 pagesLecture 15: Bayesian Networks III: CS221 / Autumn 2015 / LiangBillybob EdwardsNo ratings yet
- Shader Bits: Octahedral ImpostorsDocument15 pagesShader Bits: Octahedral ImpostorsDee .OdztaNo ratings yet
- Scimakelatex 303 Bekki+boshiDocument4 pagesScimakelatex 303 Bekki+boshimaxxflyyNo ratings yet
- Problem Session #3: EE368/CS232 Digital Image ProcessingDocument36 pagesProblem Session #3: EE368/CS232 Digital Image ProcessingRUBEN DARIO TAMAYO BALLIVIANNo ratings yet
- Simpegtutorials Readthedocs Io en LatestDocument58 pagesSimpegtutorials Readthedocs Io en LatestClarisse FernandesNo ratings yet
- Testing 2 Types of The Punch-Modular Design: Trimming Risk Quad Chart Pareto DFMEADocument61 pagesTesting 2 Types of The Punch-Modular Design: Trimming Risk Quad Chart Pareto DFMEAMarcelio DantasNo ratings yet
- DSP UpdatedDocument187 pagesDSP Updatedkiller raoNo ratings yet
- 2 Combination by PrantaDocument5 pages2 Combination by Prantaumer adilNo ratings yet
- Text Compression Algorithms: Tetsuo ShibuyaDocument36 pagesText Compression Algorithms: Tetsuo ShibuyaendaleNo ratings yet
- Lecture NN IntroDocument49 pagesLecture NN IntroAyhan TırnovaNo ratings yet
- AR S E M D L: Eview of Parse Xpert Odels in EEP EarningDocument23 pagesAR S E M D L: Eview of Parse Xpert Odels in EEP Earningal hNo ratings yet
- LMK HOP 140x80x5 IZVEŠTAJDocument6 pagesLMK HOP 140x80x5 IZVEŠTAJNIkola918No ratings yet
- 2020R1 FluentDocument65 pages2020R1 Fluentagrbovic100% (1)
- Perlun 2 - SAP2000. IntroductionWebinarDocument34 pagesPerlun 2 - SAP2000. IntroductionWebinarunayah faridaNo ratings yet
- COAL SP21 Lec7Document16 pagesCOAL SP21 Lec7Salman FareedNo ratings yet
- A Tutorial: by Clement Levallois, Erasmus University RotterdamDocument56 pagesA Tutorial: by Clement Levallois, Erasmus University RotterdamRenato Rocha SouzaNo ratings yet
- Program For Converting From Big Endian To Little Endian in Assembly Language Using Visual StudioDocument2 pagesProgram For Converting From Big Endian To Little Endian in Assembly Language Using Visual StudioDilawarNo ratings yet
- Scimakelatex 27396 Bogus+oneDocument4 pagesScimakelatex 27396 Bogus+onemdp anonNo ratings yet
- Paterson Nut Ts 2009Document35 pagesPaterson Nut Ts 2009HI HINo ratings yet
- Beautiful Documents Web Technologies: UsingDocument8 pagesBeautiful Documents Web Technologies: UsingBBUNo ratings yet
- Tuning Parameters Algorithm (1 Dimensional)Document1 pageTuning Parameters Algorithm (1 Dimensional)RobertNo ratings yet
- Scimakelatex 19596 Just Another OneDocument6 pagesScimakelatex 19596 Just Another Onemdp anonNo ratings yet
- 2021 NeurIPS VAAT Akbari, Yuan, Qian, Chuang, Chang, Cui, GongDocument16 pages2021 NeurIPS VAAT Akbari, Yuan, Qian, Chuang, Chang, Cui, GongManuel AlvarezNo ratings yet
- ANSYS Fluent Tutorial Part 2Document10 pagesANSYS Fluent Tutorial Part 2SWAPNIL PATILNo ratings yet
- 03preprocessing3 Part3 4Document49 pages03preprocessing3 Part3 4baigsalman251No ratings yet
- 1 Intro PemrogramanDocument16 pages1 Intro PemrogramanReginaldy FalNo ratings yet
- GCSE FunctionsDocument28 pagesGCSE FunctionsTheNo ratings yet
- An Analysis of Massive Multiplayer Online Role-Playing Games With ChittyDocument6 pagesAn Analysis of Massive Multiplayer Online Role-Playing Games With ChittyJuhász TamásNo ratings yet
- Lec 05Document53 pagesLec 05Hassan AhmadNo ratings yet
- Report JembatanDocument14 pagesReport JembatanArtamei WestriNo ratings yet
- Assembly Language Program To Find Largest Number in An ArrayDocument2 pagesAssembly Language Program To Find Largest Number in An ArrayAldrin RogenNo ratings yet
- The Conclusion ..Sequence and SeriesDocument17 pagesThe Conclusion ..Sequence and SeriesSatyam Kumar MalNo ratings yet
- Solidity Cheat SheetDocument1 pageSolidity Cheat SheetRahan SharmaNo ratings yet
- CamlDocument4 pagesCamlFlavio GondinNo ratings yet
- Let's Practise: Maths Workbook Coursebook 8From EverandLet's Practise: Maths Workbook Coursebook 8No ratings yet
- TQADocument18 pagesTQAMemo FarooqNo ratings yet
- The Communicative Approach: Language Is CommunicationDocument10 pagesThe Communicative Approach: Language Is CommunicationMemo FarooqNo ratings yet
- The Communicative Approach: Language Is CommunicationDocument10 pagesThe Communicative Approach: Language Is CommunicationMemo FarooqNo ratings yet
- Evalution Errors PDFDocument8 pagesEvalution Errors PDFMemo FarooqNo ratings yet
- Evalution Errors PDFDocument8 pagesEvalution Errors PDFMemo FarooqNo ratings yet
- 10.1016/j.evolhumbehav.2014.08.004: Evolution and Human BehaviorDocument35 pages10.1016/j.evolhumbehav.2014.08.004: Evolution and Human BehaviorMemo FarooqNo ratings yet
- الصعوبات في ترجمة خطاب PDFDocument105 pagesالصعوبات في ترجمة خطاب PDFMemo FarooqNo ratings yet
- Cognitive Effort in Post-Editing of Mach1 PDFDocument254 pagesCognitive Effort in Post-Editing of Mach1 PDFMemo FarooqNo ratings yet
- Exploring "The Clash of Civilization As A Paradigm" and The "Cause of The Civilizational Clash" A Review of LiteratureDocument19 pagesExploring "The Clash of Civilization As A Paradigm" and The "Cause of The Civilizational Clash" A Review of LiteratureMemo FarooqNo ratings yet
- Teaching Translation MethodsDocument5 pagesTeaching Translation MethodsMemo FarooqNo ratings yet
- Teaching Translation MethodsDocument5 pagesTeaching Translation MethodsMemo FarooqNo ratings yet
- Cognitive Effort in Post-Editing of Mach1 PDFDocument254 pagesCognitive Effort in Post-Editing of Mach1 PDFMemo FarooqNo ratings yet
- HistoryDocument12 pagesHistoryAbdelmalek HadjiNo ratings yet
- MorphologicalDocument19 pagesMorphologicalMemo FarooqNo ratings yet
- Contrastive Analysis Between English and Arabic PrepositionsDocument17 pagesContrastive Analysis Between English and Arabic PrepositionsSadeq Ahmed Alsharafi100% (1)
- Reaerch. Form and StyleDocument19 pagesReaerch. Form and StyleMemo FarooqNo ratings yet
- FLA SLA Brief Comparison PDFDocument2 pagesFLA SLA Brief Comparison PDFYenny Johana Torres BedoyaNo ratings yet
- Analytic and Synthetic: Typological Change in Varieties of European LanguagesDocument18 pagesAnalytic and Synthetic: Typological Change in Varieties of European LanguagesMemo FarooqNo ratings yet
- Addressing Power and SolidarityDocument22 pagesAddressing Power and SolidarityMemo FarooqNo ratings yet
- The Fourth Lecture 29-3-2019Document1 pageThe Fourth Lecture 29-3-2019Memo FarooqNo ratings yet
- L1 09.45 Ghislandi The Future of Translation Technology SDL Asling v2Document14 pagesL1 09.45 Ghislandi The Future of Translation Technology SDL Asling v2Memo FarooqNo ratings yet
- Reliability and ValidityDocument40 pagesReliability and ValidityMemo FarooqNo ratings yet
- Reliability and ValidityDocument40 pagesReliability and ValidityMemo Farooq100% (1)
- Qualitative Methods: 9810009m Lisa 9810010m AngelaDocument43 pagesQualitative Methods: 9810009m Lisa 9810010m AngelaMemo FarooqNo ratings yet
- Thesis PDFDocument131 pagesThesis PDFMemo FarooqNo ratings yet
- Reaerch. Form and StyleDocument19 pagesReaerch. Form and StyleMemo FarooqNo ratings yet
- Exploring Translation TheoriesDocument30 pagesExploring Translation TheoriesNawwar AlshroofNo ratings yet
- AbstractDocument1 pageAbstractMemo FarooqNo ratings yet
- LL Local IzaDocument3 pagesLL Local IzaMemo FarooqNo ratings yet
- Oracle Interview Questions and AnswersDocument7 pagesOracle Interview Questions and AnswersAzhag ArasuNo ratings yet
- Csca0101 ch03Document51 pagesCsca0101 ch03Alvans Nuril BrillianNo ratings yet
- Mini2451 Usersmanual 103113Document176 pagesMini2451 Usersmanual 103113eddyNo ratings yet
- Interpreting Wait Events To Boost System Performance: Roger Schrag Database Specialists, IncDocument68 pagesInterpreting Wait Events To Boost System Performance: Roger Schrag Database Specialists, Inca singhNo ratings yet
- Liebert IntelliSlot ® Web CardsDocument20 pagesLiebert IntelliSlot ® Web CardsDeathLordNo ratings yet
- MSSQL Interview QuestionsDocument32 pagesMSSQL Interview QuestionsAnonymous 1GAxwUf100% (1)
- Masterarbeit Oleksandr Panchenko PDFDocument106 pagesMasterarbeit Oleksandr Panchenko PDFHolly MurrayNo ratings yet
- Frequently Asked Questions VMMDocument18 pagesFrequently Asked Questions VMMMohinuddin MustaqNo ratings yet
- Programming Manual For Basic LearningDocument20 pagesProgramming Manual For Basic Learning36. jihanNo ratings yet
- MethoOOPS Class Attach ShipmentDocument4 pagesMethoOOPS Class Attach ShipmentsomnathsapNo ratings yet
- General Specifications: GS 36J31A11-01EDocument11 pagesGeneral Specifications: GS 36J31A11-01EJignesh DodiyaNo ratings yet
- 3DATS MAXScript Cheat SheetDocument2 pages3DATS MAXScript Cheat SheetRido Kurniawan ZahNo ratings yet
- 9781786468666-Building Microservices With GoDocument353 pages9781786468666-Building Microservices With GoLeoForconesi100% (3)
- ADS SyllabusDocument1 pageADS SyllabusSubhash KulhariNo ratings yet
- DebugInfo 2018 05 29 - 14 53 46Document89 pagesDebugInfo 2018 05 29 - 14 53 46chajimNo ratings yet
- Memory-Interfacing: LessonDocument8 pagesMemory-Interfacing: LessonSayan Kumar KhanNo ratings yet
- User Manual - Delta.x 1.6Document24 pagesUser Manual - Delta.x 1.6Sebastien GrangeNo ratings yet
- Fpga AdvantagesDocument2 pagesFpga AdvantagesTanuj Hasija100% (1)
- NBTE CurriculumDocument189 pagesNBTE CurriculumDyaji Charles Bala100% (1)
- DSF - Lab Manual (Se It)Document39 pagesDSF - Lab Manual (Se It)Avi SurywanshiNo ratings yet
- ECE 5463 Introduction To Robotics Spring 2018: ROS Tutorial 1Document26 pagesECE 5463 Introduction To Robotics Spring 2018: ROS Tutorial 1Gàñêsh RëddyNo ratings yet
- HOW TOMake Your Computer Talk Like Iron Man's JarvisDocument3 pagesHOW TOMake Your Computer Talk Like Iron Man's JarvisBlack JackalsNo ratings yet
- Rd1022 Lattice RGMII To GMII BridgeDocument4 pagesRd1022 Lattice RGMII To GMII Bridgelim_mgNo ratings yet
- Java Programming Lab Programs ListDocument51 pagesJava Programming Lab Programs ListPalakonda SrikanthNo ratings yet
- Acc BekasDocument2 pagesAcc BekasAditiyaNo ratings yet
- DB LOB Sizing v54Document17 pagesDB LOB Sizing v54Jebabalanmari JebabalanNo ratings yet
- 11 Februn 1Document2 pages11 Februn 1soumava palitNo ratings yet
- PMBusGUI ManualDocument81 pagesPMBusGUI ManualDmitry PakhatovNo ratings yet
- Wavelets and Multiresolution: by Dr. Mahua BhattacharyaDocument39 pagesWavelets and Multiresolution: by Dr. Mahua BhattacharyashubhamNo ratings yet
- RoutersDocument4 pagesRoutersBeth RivNo ratings yet