You might also like
- GÜREL, E., TAT, M. (2017) - SWOT Analysis - A Theoretical Review PDFDocument14 pagesGÜREL, E., TAT, M. (2017) - SWOT Analysis - A Theoretical Review PDFpaolawiesner100% (1)
- Introduction To Big Data ManagementDocument9 pagesIntroduction To Big Data ManagementNurul Akmar EmranNo ratings yet
- Data Analytics with Python: Data Analytics in Python Using PandasFrom EverandData Analytics with Python: Data Analytics in Python Using PandasRating: 3 out of 5 stars3/5 (1)
- Share Module 2 - Activity 1Document2 pagesShare Module 2 - Activity 1Rysyl Mae Moquerio100% (2)
- Big DataDocument6 pagesBig DataDivyasriNo ratings yet
- WINSEM2022-23 MAT6015 ETH VL2022230506274 ReferenceMaterialI WedFeb1500 00 00IST2023 IntroductiontoBigDataDocument20 pagesWINSEM2022-23 MAT6015 ETH VL2022230506274 ReferenceMaterialI WedFeb1500 00 00IST2023 IntroductiontoBigDataSimritha RANo ratings yet
- BDA Unit 1Document22 pagesBDA Unit 1pl.babyshalini palanisamyNo ratings yet
- Unit 1Document22 pagesUnit 1Vishal ShivhareNo ratings yet
- Keywords: Big Data Business Analytics Business Intelligence RDBMSDocument27 pagesKeywords: Big Data Business Analytics Business Intelligence RDBMSSaahil BcNo ratings yet
- BigdataDocument12 pagesBigdataTGOWNo ratings yet
- Data AnalyticsDocument5 pagesData AnalyticsLen FCNo ratings yet
- Unit I - Big Data ProgrammingDocument19 pagesUnit I - Big Data ProgrammingjasmineNo ratings yet
- Big Data Analytics - Unit 1Document43 pagesBig Data Analytics - Unit 1Johan TorresNo ratings yet
- Ccs 334Document16 pagesCcs 334Amsaveni .amsaveniNo ratings yet
- (Ca) Unit-IiDocument8 pages(Ca) Unit-IiLakshmi LakshminarayanaNo ratings yet
- Tweet Segmentation and Classification For Rumor Identification Using KNN ApproachDocument7 pagesTweet Segmentation and Classification For Rumor Identification Using KNN ApproachKumarecitNo ratings yet
- Sesi 3 Analytics and Big DataDocument28 pagesSesi 3 Analytics and Big DataalpaomegaNo ratings yet
- Reading Teks Kelompok 2Document12 pagesReading Teks Kelompok 2Bagus DiantoroNo ratings yet
- Big DataDocument3 pagesBig Datanam trầnNo ratings yet
- Pub Res Feb 20231Document5 pagesPub Res Feb 20231ael masNo ratings yet
- Getting An Overview of Big Data (Module1)Document58 pagesGetting An Overview of Big Data (Module1)Nihal KocheNo ratings yet
- Big Data Analytics NotesDocument117 pagesBig Data Analytics NotesARYAN GUPTANo ratings yet
- Demystifying Big Data RGc1.0Document10 pagesDemystifying Big Data RGc1.0Nandan Kumar100% (1)
- Big Data Research PaperDocument14 pagesBig Data Research PaperSandeep KumarNo ratings yet
- Three V of Big DataDocument4 pagesThree V of Big DataAedrian HarveyNo ratings yet
- Unit-5 DSDocument20 pagesUnit-5 DSrajkumarmtechNo ratings yet
- Bda Aiml Note Unit 1Document14 pagesBda Aiml Note Unit 1viswakranthipalagiriNo ratings yet
- 2 - 275680 - Individual Assignment 1Document15 pages2 - 275680 - Individual Assignment 1Muhammad Arif FarhanNo ratings yet
- Big Data Overview: by Prof. S.S.BudhwarDocument39 pagesBig Data Overview: by Prof. S.S.BudhwarShyam BudhwarNo ratings yet
- Data Science Vs Big DataDocument34 pagesData Science Vs Big Datapoi.tamrakarNo ratings yet
- The 365 DS Booklet PDFDocument67 pagesThe 365 DS Booklet PDFCharly Sarti100% (1)
- Harnessing The Value of Big Data AnalyticsDocument13 pagesHarnessing The Value of Big Data AnalyticsboraincNo ratings yet
- 2015KS Mediratta-Big Data Terms, Definitions and ApplicationsDocument28 pages2015KS Mediratta-Big Data Terms, Definitions and ApplicationsThe PriestNo ratings yet
- Big Data Module 1Document19 pagesBig Data Module 1AnanthvasanthaNo ratings yet
- Business Analytics & ApplicationsDocument21 pagesBusiness Analytics & ApplicationsAbhishek DubeyNo ratings yet
- Big Data 4Document2 pagesBig Data 4Otra VezNo ratings yet
- Big Data ContentDocument7 pagesBig Data Contenthats1234100% (1)
- BigData, Data Mining and Machine Learning Ch1&2Document5 pagesBigData, Data Mining and Machine Learning Ch1&2aswagadaNo ratings yet
- Big Data AnalysisDocument30 pagesBig Data AnalysisAdithya GutthaNo ratings yet
- Data Science: Lesson 2Document6 pagesData Science: Lesson 2lia immie rigoNo ratings yet
- Introduction To Big Data - PresentationDocument30 pagesIntroduction To Big Data - PresentationMohamed RachdiNo ratings yet
- Big Data Module 1Document14 pagesBig Data Module 1OK BYENo ratings yet
- BIG DATA Technology: SubtitleDocument34 pagesBIG DATA Technology: SubtitleDhavan KumarNo ratings yet
- Chapter - 2 - Data ScienceDocument32 pagesChapter - 2 - Data Scienceaschalew woldeyesusNo ratings yet
- Big Data SeminarDocument27 pagesBig Data SeminarAlemayehu Getachew100% (1)
- Unit 5 Concepts of Big Data and Data LakeDocument15 pagesUnit 5 Concepts of Big Data and Data Lakejaysukhv234No ratings yet
- Ethiopin Tecica University Departement of Ict Cours Title: Big DataDocument15 pagesEthiopin Tecica University Departement of Ict Cours Title: Big DatagudissagabissaNo ratings yet
- Big Data Analytics - Unit1Document31 pagesBig Data Analytics - Unit1Prabha JoshiNo ratings yet
- Aws Data Analytics FundamentalsDocument15 pagesAws Data Analytics Fundamentals4139 NIVEDHA S100% (1)
- Mittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataDocument6 pagesMittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataNitin PatidarNo ratings yet
- Big Data UNIT1Document23 pagesBig Data UNIT1Keshava VarmaNo ratings yet
- Chapter 9 Business IntelligenceDocument3 pagesChapter 9 Business IntelligenceMardhiah RamlanNo ratings yet
- Mittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataDocument6 pagesMittal School of Business: Course Code: CAP348 Course Title: Introduction To Big DataNitin PatidarNo ratings yet
- BIG Data Analysis Assign - FinalDocument21 pagesBIG Data Analysis Assign - FinalBehailu DemissieNo ratings yet
- Big Data UnitDocument16 pagesBig Data UnitAkanshaJainNo ratings yet
- Big Data Analytics PDFDocument22 pagesBig Data Analytics PDFSAYYAD RAFINo ratings yet
- Big Data Analytics: A Literature Review Paper: Abstract. in The Information Era, Enormous Amounts of Data Have BecomeDocument14 pagesBig Data Analytics: A Literature Review Paper: Abstract. in The Information Era, Enormous Amounts of Data Have BecomeDolphingNo ratings yet
- Big Data: Beginning With Capture, Organize, Integrate, Analyze, and ActDocument23 pagesBig Data: Beginning With Capture, Organize, Integrate, Analyze, and Actsofimukhtar100% (1)
- IV Unit Big Data AnalysisDocument17 pagesIV Unit Big Data Analysisgowrishankar nayanaNo ratings yet
- Business AnalyticsDocument46 pagesBusiness AnalyticsMuhammed Althaf VK100% (3)
- Big Data AnalyticsDocument8 pagesBig Data AnalyticsSiva PrakashNo ratings yet
- Unit I Introduction To Big Data: 1.1 DefinitionDocument16 pagesUnit I Introduction To Big Data: 1.1 DefinitionvinodkharNo ratings yet
- Ssoar-2017-Neyestani-Seven Basic Tools of QualityDocument11 pagesSsoar-2017-Neyestani-Seven Basic Tools of QualityYUNASRIL SYARIEFNo ratings yet
- Provided by K-State Research ExchangeDocument80 pagesProvided by K-State Research ExchangeAngga Riyandi SNo ratings yet
- Protokoler Lions Club 2018 2019Document21 pagesProtokoler Lions Club 2018 2019Angga Riyandi SNo ratings yet
- Pellet Mill HandbookDocument21 pagesPellet Mill HandbookAngga Riyandi SNo ratings yet
- 006 URS Back CoaterDocument1 page006 URS Back CoaterAngga Riyandi SNo ratings yet
- Angga Riyandi. S: Coating Line AutomationDocument48 pagesAngga Riyandi. S: Coating Line AutomationAngga Riyandi SNo ratings yet
- Lumber DryingDocument144 pagesLumber Dryingabrfin100% (9)
- Analisa Kakao v2 - SummaryDocument42 pagesAnalisa Kakao v2 - SummaryAngga Riyandi SNo ratings yet
- YogeshPatil AnalyticsDocument3 pagesYogeshPatil AnalyticsNaga Ravi Thej KasibhatlaNo ratings yet
- InvoiceDocument1 pageInvoiceAkhil Patel BandariNo ratings yet
- Name Engineering Standard Number: Cummins Internal Use OnlyDocument9 pagesName Engineering Standard Number: Cummins Internal Use OnlypathinathanNo ratings yet
- Strategic Management Concepts Competitiveness and Globalization 11th Edition Hitt Solutions ManualDocument26 pagesStrategic Management Concepts Competitiveness and Globalization 11th Edition Hitt Solutions ManualBrettFreemanrefc100% (43)
- Christopher Morrison Analysis Project-4Document12 pagesChristopher Morrison Analysis Project-4api-624308446No ratings yet
- Quiz Section 5 Cia Part 1 Governance, Risk Management, and ControlDocument15 pagesQuiz Section 5 Cia Part 1 Governance, Risk Management, and ControlMitch MinglanaNo ratings yet
- Controversies in Digital EthicsDocument393 pagesControversies in Digital EthicsAlyssa Marie SantosNo ratings yet
- Law Commission of Bangladesh.Document6 pagesLaw Commission of Bangladesh.Nishat Chowdhury DolonNo ratings yet
- CMSNR Sale Tax v. K. KelukuttyDocument2 pagesCMSNR Sale Tax v. K. KelukuttyjaishreeNo ratings yet
- Task 6 (U20 - D1)Document7 pagesTask 6 (U20 - D1)JadeNo ratings yet
- Arun Jyothi - RSDocument22 pagesArun Jyothi - RSMOHAMMED KHAYYUMNo ratings yet
- Communication Management Plan PDFDocument17 pagesCommunication Management Plan PDFUmair BaigNo ratings yet
- l4m7 Questions 1Document19 pagesl4m7 Questions 1Dejanira ScottNo ratings yet
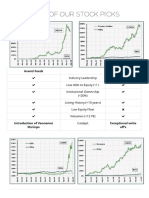
- Some of Our Stock Picks: Avanti Feeds Finolex CablesDocument3 pagesSome of Our Stock Picks: Avanti Feeds Finolex CablesSam vermNo ratings yet
- Number of Posts: 3 Contract Type: Indefinite About Us: Forex DealerDocument2 pagesNumber of Posts: 3 Contract Type: Indefinite About Us: Forex DealerArmando GuerraNo ratings yet
- SectionA Group 3 RAOBDA ReportDocument7 pagesSectionA Group 3 RAOBDA ReportIsha ChaudharyNo ratings yet
- V 6 o JDks 4Document3 pagesV 6 o JDks 4Noel JenningsNo ratings yet
- Aggregate PlanningDocument3 pagesAggregate PlanningAdityaNo ratings yet
- WSCSS - Worksheets 3 Parent 2023 01Document6 pagesWSCSS - Worksheets 3 Parent 2023 01mom2asherloveNo ratings yet
- Capítulo 05 - OM Solutions (8 Edición) - Barry Render y Jay HeizerDocument11 pagesCapítulo 05 - OM Solutions (8 Edición) - Barry Render y Jay HeizerAntonio LMNo ratings yet
- Computerized Accounting in Ghana The Shi PDFDocument8 pagesComputerized Accounting in Ghana The Shi PDFKhalid AhmedNo ratings yet
- EMS Sequence & InteractionDocument1 pageEMS Sequence & InteractionAbusaada2012No ratings yet
- Department of Trade and Industry: 3L Publication Code 380-20170714-41Document4 pagesDepartment of Trade and Industry: 3L Publication Code 380-20170714-41paympmnpNo ratings yet
- Tsupreme Ourt: 31/epuhlic of TbeDocument16 pagesTsupreme Ourt: 31/epuhlic of TbeMonocrete Construction Philippines, Inc.No ratings yet
- Lecture 17 BH CH 9 Stock and Their Valuation Part 1Document30 pagesLecture 17 BH CH 9 Stock and Their Valuation Part 1Alif SultanliNo ratings yet
- Chapter 11 Performance Measurement in Decentralized OrganizationsDocument28 pagesChapter 11 Performance Measurement in Decentralized OrganizationsMariam MahmoudNo ratings yet
- Value Stream Mapping in A Discrete Manufacturing: A Case StudyDocument13 pagesValue Stream Mapping in A Discrete Manufacturing: A Case StudyVõ Hồng HạnhNo ratings yet
- Income DeterminationDocument82 pagesIncome DeterminationPaulo BatholomayoNo ratings yet
- What's New in Windows 10 (Windows 10)Document56 pagesWhat's New in Windows 10 (Windows 10)NirNo ratings yet