You might also like
- Applied Machine Learning For Engineers: Introduction To NumpyDocument13 pagesApplied Machine Learning For Engineers: Introduction To NumpyGilbe TestaNo ratings yet
- Numpy PandasDocument20 pagesNumpy PandasAnish pandeyNo ratings yet
- Lecture 2 Python 常用libraryDocument41 pagesLecture 2 Python 常用libraryYuanxingNo ratings yet
- Quantile Regression ExplainedDocument4 pagesQuantile Regression Explainedramesh158No ratings yet
- C 19 AmanAgarwalDocument13 pagesC 19 AmanAgarwalAman BansalNo ratings yet
- End Sem External EddelDocument7 pagesEnd Sem External EddelRAHULNo ratings yet
- Lab Record 2018-19 Mathematical Models Using Python Programming MAT451 Name: Yamuna.A Reg No:1740370Document32 pagesLab Record 2018-19 Mathematical Models Using Python Programming MAT451 Name: Yamuna.A Reg No:1740370yamunaNo ratings yet
- C 19 AmanAgarwalDocument13 pagesC 19 AmanAgarwalAman BansalNo ratings yet
- Untitled 3Document4 pagesUntitled 3Kagade AjinkyaNo ratings yet
- 統計學習CH2 Lab - Jupyter Notebook (直向)Document41 pages統計學習CH2 Lab - Jupyter Notebook (直向)張FNo ratings yet
- Name: Shreyash Kharat Homework: Hw3 (Problem 1)Document7 pagesName: Shreyash Kharat Homework: Hw3 (Problem 1)Mainak SamantaNo ratings yet
- Labpractice 2Document29 pagesLabpractice 2Rajashree Das100% (2)
- Python PractcalDocument3 pagesPython PractcalNilam PathareNo ratings yet
- Answer PDF LabDocument34 pagesAnswer PDF LabAl KafiNo ratings yet
- Brain Tumor ClassificationDocument12 pagesBrain Tumor ClassificationUltra Bloch100% (1)
- Kerr - Solve IvpDocument8 pagesKerr - Solve Ivpyulieth andrea ramirez romeroNo ratings yet
- Polarisation DataDocument10 pagesPolarisation DataNobe FelixNo ratings yet
- Estiven - Hurtado.Santos - Regresión Con Varios AlgoritmosDocument16 pagesEstiven - Hurtado.Santos - Regresión Con Varios AlgoritmosEstiven Hurtado SantosNo ratings yet
- Assignment 4Document5 pagesAssignment 4shellieratheeNo ratings yet
- ML Lab-Assignment-5Document8 pagesML Lab-Assignment-5Ajeet SinghNo ratings yet
- Content: From Import Import As Import Import Import AsDocument8 pagesContent: From Import Import As Import Import Import Asبشار الحسينNo ratings yet
- KnapsackDocument28 pagesKnapsackpricifelixNo ratings yet
- Steepest DescentDocument1 pageSteepest DescentYasaman AsiaeeNo ratings yet
- Interpolatingfunction : Bla Ndsolve ( (F ''' (T) + F (T) F '' (T) 0, F (0) 0, F ' (0) 0, F ' (100 000) 1), F, T)Document7 pagesInterpolatingfunction : Bla Ndsolve ( (F ''' (T) + F (T) F '' (T) 0, F (0) 0, F ' (0) 0, F ' (100 000) 1), F, T)Alexis CastleNo ratings yet
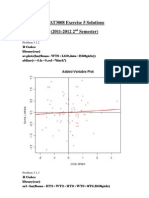
- STAT3008 Ex5 SolutionsDocument8 pagesSTAT3008 Ex5 SolutionsKewell ChongNo ratings yet
- Assignment 6.2aDocument4 pagesAssignment 6.2adashNo ratings yet
- Analisis Dinamico Eje XDocument24 pagesAnalisis Dinamico Eje XVICTOR MANUEL PAITAN MENDEZNo ratings yet
- 3.numpy: 0.0.1 ArraysDocument22 pages3.numpy: 0.0.1 ArraysAnish pandeyNo ratings yet
- Kecerdasan Artifisial Dan Masyarakat - M5Document8 pagesKecerdasan Artifisial Dan Masyarakat - M5Citra LarasatiNo ratings yet
- SMOTE Samples Calculation: X - Class (Y 1)Document2 pagesSMOTE Samples Calculation: X - Class (Y 1)Hsu Let Yee HninNo ratings yet
- SMOTE Samples Calculation: X - Class (Y 1)Document2 pagesSMOTE Samples Calculation: X - Class (Y 1)Hsu Let Yee HninNo ratings yet
- Lab 8Document8 pagesLab 8Aman BansalNo ratings yet
- TP6 MatlabDocument5 pagesTP6 MatlabBorith pangNo ratings yet
- Python Qazaqsha Sabak 3Document12 pagesPython Qazaqsha Sabak 3Damir MuratbaevNo ratings yet
- Nama: Asnur Saputra NIM: F1A220034 Kelas: B Prodi: S1 StatistikaDocument7 pagesNama: Asnur Saputra NIM: F1A220034 Kelas: B Prodi: S1 StatistikaAsnur SaputraNo ratings yet
- Assignment 6.1Document4 pagesAssignment 6.1dashNo ratings yet
- Q1 Gauss-Seidel Method ProgramDocument8 pagesQ1 Gauss-Seidel Method ProgramAhmed HwaidiNo ratings yet
- La Praktikum m3Document9 pagesLa Praktikum m3Ellga Yunita Nurul AzizahNo ratings yet
- Notebook 1 - NumpyDocument17 pagesNotebook 1 - Numpyksckr.20No ratings yet
- 0.0.1 Implementation of Recurrent Neural Network: #Importing The Required LibrariesDocument9 pages0.0.1 Implementation of Recurrent Neural Network: #Importing The Required LibrariesSanidhya JadaunNo ratings yet
- FS321 InformeDocument13 pagesFS321 InformePaula MontoyaNo ratings yet
- Import As Import As From Import: "Mean Squared Errors: "Document1 pageImport As Import As From Import: "Mean Squared Errors: "ulNo ratings yet
- AssessmentGroup 2 MAT423.Ipynb - ColaboratoryDocument15 pagesAssessmentGroup 2 MAT423.Ipynb - ColaboratoryNUR HIDAYAH ISHAKNo ratings yet
- Lab 8Document8 pagesLab 8Aman BansalNo ratings yet
- Import AsDocument27 pagesImport AsFozia Dawood100% (1)
- Lab 8Document8 pagesLab 8Aman BansalNo ratings yet
- EigenvaluesDocument5 pagesEigenvaluesyashsonone25No ratings yet
- Euler Explicit Jan2024Document11 pagesEuler Explicit Jan2024getachewbonga09No ratings yet
- Gaurav - Data Mining Lab AssignmentDocument36 pagesGaurav - Data Mining Lab AssignmentJJ OLATUNJINo ratings yet
- Poisonousmushrooms: 1 Importing The LibrariesDocument8 pagesPoisonousmushrooms: 1 Importing The LibrariesSamuel PeoplesNo ratings yet
- Awadhesh Kumar Maurya - KIET Weekly Coading Day 1Document7 pagesAwadhesh Kumar Maurya - KIET Weekly Coading Day 1Awadhesh MauryaNo ratings yet
- SGD For Linear RegressionDocument4 pagesSGD For Linear RegressionRahul YadavNo ratings yet
- Assignment 1Document4 pagesAssignment 1Raisa RashidNo ratings yet
- Numpy FunctionsDocument9 pagesNumpy FunctionsRamesh Kumar MojjadaNo ratings yet
- Ai Record - 65Document20 pagesAi Record - 65SidharthNo ratings yet
- Prac 6 MatplotlibDocument6 pagesPrac 6 MatplotlibheilNo ratings yet
- Prac 6 MatplotlibDocument6 pagesPrac 6 MatplotlibheilNo ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- Python Exam Practice - ExercisesDocument6 pagesPython Exam Practice - ExercisesAriyan JahanyarNo ratings yet
- ITTC - Recommended Procedures: CFD, Resistance and Flow Uncertainty Analysis in CFD Examples For Resistance and FlowDocument12 pagesITTC - Recommended Procedures: CFD, Resistance and Flow Uncertainty Analysis in CFD Examples For Resistance and FlowSurya Chala PraveenNo ratings yet
- Implementation of An Air-Entrainment Model in Interfoam: CFD With Opensource SoftwareDocument46 pagesImplementation of An Air-Entrainment Model in Interfoam: CFD With Opensource SoftwareSurya Chala PraveenNo ratings yet
- Procedure For Estimation and Reporting of Uncertainty Due To Discretization in CFD ApplicationsDocument4 pagesProcedure For Estimation and Reporting of Uncertainty Due To Discretization in CFD ApplicationsSurya Chala PraveenNo ratings yet
- Towards A Cfd-Based Prediction of Ship PerformanceDocument12 pagesTowards A Cfd-Based Prediction of Ship PerformanceSurya Chala PraveenNo ratings yet
- ExternalAero SEA Ugm 2015Document43 pagesExternalAero SEA Ugm 2015Surya Chala PraveenNo ratings yet
- Robotic TunaDocument9 pagesRobotic TunaSurya Chala PraveenNo ratings yet
- Hamilton Series BrochureDocument12 pagesHamilton Series BrochureSurya Chala PraveenNo ratings yet
- Uinl O: (12) Ulllted States Patent (10) Patent N0.: US 7,762,776 B2Document11 pagesUinl O: (12) Ulllted States Patent (10) Patent N0.: US 7,762,776 B2Surya Chala PraveenNo ratings yet
- Effects of Motion at Sea On Crew Performance - Stevens & Parsons - 2002 PDFDocument19 pagesEffects of Motion at Sea On Crew Performance - Stevens & Parsons - 2002 PDFSurya Chala PraveenNo ratings yet
- Interference Resistance of Multi-Hulls Per Thin-Ship Theory: Ronald W. YeungDocument4 pagesInterference Resistance of Multi-Hulls Per Thin-Ship Theory: Ronald W. YeungSurya Chala PraveenNo ratings yet
- Technical Report - Discharge Facilities For Oil Recovered at Sea PDFDocument356 pagesTechnical Report - Discharge Facilities For Oil Recovered at Sea PDFSurya Chala PraveenNo ratings yet
- GUIDELINES-No.37Guidelines For Towage at Sea, 2012 (Full Permission)Document45 pagesGUIDELINES-No.37Guidelines For Towage at Sea, 2012 (Full Permission)NMHaNo ratings yet
- Binaries - GL Leaflet For Inclining Test - V21 - tcm4-599587Document13 pagesBinaries - GL Leaflet For Inclining Test - V21 - tcm4-599587Surya Chala PraveenNo ratings yet
- 832 Swamp TestDocument1 page832 Swamp TestSurya Chala PraveenNo ratings yet
- Cat 12Document4 pagesCat 12Surya Chala PraveenNo ratings yet
- Easter in RomaniaDocument5 pagesEaster in RomaniaDragos IonutNo ratings yet
- (Music of The African Diaspora) Robin D. Moore-Music and Revolution - Cultural Change in Socialist Cuba (Music of The African Diaspora) - University of California Press (2006) PDFDocument367 pages(Music of The African Diaspora) Robin D. Moore-Music and Revolution - Cultural Change in Socialist Cuba (Music of The African Diaspora) - University of California Press (2006) PDFGabrielNo ratings yet
- BIOCHEM REPORT - OdtDocument16 pagesBIOCHEM REPORT - OdtLingeshwarry JewarethnamNo ratings yet
- Sophia Vyzoviti - Super SurfacesDocument73 pagesSophia Vyzoviti - Super SurfacesOptickall Rmx100% (1)
- TypeFinderReport ENFPDocument10 pagesTypeFinderReport ENFPBassant AdelNo ratings yet
- TOPIC I: Moral and Non-Moral ProblemsDocument6 pagesTOPIC I: Moral and Non-Moral ProblemsHaydee Christine SisonNo ratings yet
- Jordana Wagner Leadership Inventory Outcome 2Document22 pagesJordana Wagner Leadership Inventory Outcome 2api-664984112No ratings yet
- Respiratory Examination OSCE GuideDocument33 pagesRespiratory Examination OSCE GuideBasmah 7No ratings yet
- English Lesson Plan 6 AugustDocument10 pagesEnglish Lesson Plan 6 AugustKhairunnisa FazilNo ratings yet
- Teuku Tahlil Prosiding38491Document30 pagesTeuku Tahlil Prosiding38491unosa unounoNo ratings yet
- Chapter 8 - FluidDocument26 pagesChapter 8 - FluidMuhammad Aminnur Hasmin B. HasminNo ratings yet
- (Abhijit Champanerkar, Oliver Dasbach, Efstratia K (B-Ok - Xyz)Document273 pages(Abhijit Champanerkar, Oliver Dasbach, Efstratia K (B-Ok - Xyz)gogNo ratings yet
- Em - 1110 1 1005Document498 pagesEm - 1110 1 1005Sajid arNo ratings yet
- History of Drugs (Autosaved)Document68 pagesHistory of Drugs (Autosaved)Juan TowTowNo ratings yet
- Framework For Marketing Management Global 6Th Edition Kotler Solutions Manual Full Chapter PDFDocument33 pagesFramework For Marketing Management Global 6Th Edition Kotler Solutions Manual Full Chapter PDFWilliamThomasbpsg100% (9)
- Saxonville CaseDocument2 pagesSaxonville Casel103m393No ratings yet
- Stockholm KammarbrassDocument20 pagesStockholm KammarbrassManuel CoitoNo ratings yet
- HRM and The Business EnvironmentDocument18 pagesHRM and The Business Environmentsuzzette91No ratings yet
- Chapter 019Document28 pagesChapter 019Esteban Tabares GonzalezNo ratings yet
- MOtivating Your Teenager PDFDocument66 pagesMOtivating Your Teenager PDFElleMichelle100% (1)
- Some Problems in Determining The Origin of The Philippine Word Mutya' or Mutia'Document34 pagesSome Problems in Determining The Origin of The Philippine Word Mutya' or Mutia'Irma ramosNo ratings yet
- Configuration Steps - Settlement Management in S - 4 HANA - SAP BlogsDocument30 pagesConfiguration Steps - Settlement Management in S - 4 HANA - SAP Blogsenza100% (4)
- Iso 20816 8 2018 en PDFDocument11 pagesIso 20816 8 2018 en PDFEdwin Bermejo75% (4)
- Oda A La InmortalidadDocument7 pagesOda A La InmortalidadEmy OoTeam ClésNo ratings yet
- Literature Review On Catfish ProductionDocument5 pagesLiterature Review On Catfish Productionafmzyodduapftb100% (1)
- Kami Export - Document PDFDocument2 pagesKami Export - Document PDFapi-296608066No ratings yet
- Capacitor Banks in Power System Part FourDocument4 pagesCapacitor Banks in Power System Part FourTigrillo100% (1)
- HIS Unit COMBINES Two Birthdays:: George Washington's BirthdayDocument9 pagesHIS Unit COMBINES Two Birthdays:: George Washington's BirthdayOscar Panez LizargaNo ratings yet
- Urinary Tract Infection in Children: CC MagbanuaDocument52 pagesUrinary Tract Infection in Children: CC MagbanuaVanessa YunqueNo ratings yet
- Test Statistics Fact SheetDocument4 pagesTest Statistics Fact SheetIra CervoNo ratings yet