You might also like
- ML0101EN Clas SVM Cancer Py v1Document10 pagesML0101EN Clas SVM Cancer Py v1banicxNo ratings yet
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Data Assigment 1Document32 pagesData Assigment 1Sukhwinder Kaur100% (1)
- Image Classification With Convolutional Neural Networks: PlottingDocument16 pagesImage Classification With Convolutional Neural Networks: PlottingfamasyaNo ratings yet
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- Predicting Diamond Price: 2 Step MethodDocument17 pagesPredicting Diamond Price: 2 Step MethodSarajit Poddar100% (1)
- Tugas Clustering - 132021012 - Kevin Gazkia NaufalDocument6 pagesTugas Clustering - 132021012 - Kevin Gazkia NaufalkevinNo ratings yet
- Assignment 2 PDFDocument25 pagesAssignment 2 PDFBoni HalderNo ratings yet
- Adegenet TutorialDocument63 pagesAdegenet Tutorialandreea_duduNo ratings yet
- Work FlowDocument6 pagesWork Flowayushisharma.hcstNo ratings yet
- Assignment 1 - LP1Document14 pagesAssignment 1 - LP1bbad070105No ratings yet
- 1st Harvard ProjectDocument17 pages1st Harvard ProjectAlexandre Tem-PassNo ratings yet
- Cluster Analysis With RDocument11 pagesCluster Analysis With Rjohn kayNo ratings yet
- MLT Exp 09Document3 pagesMLT Exp 09Sec ArcNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Image ClassifactionDocument17 pagesImage Classifactionmk10octNo ratings yet
- GuideToIRTinvarianceUsingMIRT (ANCHOR)Document10 pagesGuideToIRTinvarianceUsingMIRT (ANCHOR)Ampeh SarokNo ratings yet
- Digits Recognition DatasetDocument4 pagesDigits Recognition DatasetJoe1No ratings yet
- Output2Document2 pagesOutput2Laptop-Dimas-249No ratings yet
- ML Ex6Document8 pagesML Ex6yefigoh133No ratings yet
- HW 1Document4 pagesHW 1Anonymous gUySMcpSqNo ratings yet
- ProjectDocument18 pagesProjectapi-525983464No ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- Clustering - Jupyter NotebookDocument11 pagesClustering - Jupyter Notebookreema dsouzaNo ratings yet
- Assignment-1 80501Document6 pagesAssignment-1 80501rishabh7aroraNo ratings yet
- Home ConstructionDocument8 pagesHome Constructionphatakpriya108No ratings yet
- 1.diagnosis Using MLDocument69 pages1.diagnosis Using MLChoral WealthNo ratings yet
- Ai/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050Document5 pagesAi/Ml Lab-4: Name: Pratik Jadhav PRN: 20190802050testNo ratings yet
- Practical Machine LearningDocument11 pagesPractical Machine Learningminhajur rahmanNo ratings yet
- Answers For End-Sem Exam Part - 2 (Deep Learning)Document20 pagesAnswers For End-Sem Exam Part - 2 (Deep Learning)Ankur BorkarNo ratings yet
- Lab 4 - Unsupervised Learning: K-Means ClusteringDocument7 pagesLab 4 - Unsupervised Learning: K-Means ClusteringFaisal zafarNo ratings yet
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- 4c Sklearn-Classification-Regression-Bkhw-Spring 2019Document20 pages4c Sklearn-Classification-Regression-Bkhw-Spring 2019Radhika KhandelwalNo ratings yet
- NBP MatchingDocument17 pagesNBP MatchingniladrioramaNo ratings yet
- Practica 2 TemperaturaDocument11 pagesPractica 2 TemperaturaJilmeNo ratings yet
- Fashion MNIST-6Document10 pagesFashion MNIST-6akif barbaros dikmenNo ratings yet
- K Means ClusteringDocument10 pagesK Means ClusteringWalid Sassi100% (1)
- Sentimen2.ipynb - ColaboratoryDocument12 pagesSentimen2.ipynb - ColaboratoryWowon PriatnaNo ratings yet
- Segmentation of Cancer TissueDocument18 pagesSegmentation of Cancer Tissuejebli mohamed amineNo ratings yet
- Lab MannualDocument49 pagesLab Mannualvickyakfan152002No ratings yet
- Part A Assignment 10Document3 pagesPart A Assignment 10B49 Pravin TeliNo ratings yet
- R Lab 4Document7 pagesR Lab 4sdcphdworkNo ratings yet
- Procedure GLMDocument37 pagesProcedure GLMMauricio González PalacioNo ratings yet
- Negative Binomial Regression - R Data Analysis ExamplesDocument11 pagesNegative Binomial Regression - R Data Analysis ExamplesFhano HendrianNo ratings yet
- MirtDocument103 pagesMirtisra.sza72No ratings yet
- Heart Disease Classification ML Assignment - Jupyter NotebookDocument7 pagesHeart Disease Classification ML Assignment - Jupyter Notebookfurole sammyceNo ratings yet
- MNTC313Assignment5 2021Document2 pagesMNTC313Assignment5 2021PeterNo ratings yet
- GokulDocument10 pagesGokulcomputerg00007No ratings yet
- Deep Learning Lab (Ai&ds)Document39 pagesDeep Learning Lab (Ai&ds)BELMER GLADSON Asst. Prof. (CSE)No ratings yet
- Maxbox Starter100 Data Science StoryDocument10 pagesMaxbox Starter100 Data Science StoryMax KleinerNo ratings yet
- R Project 1Document36 pagesR Project 1AlvinBurhaniNo ratings yet
- Nomor 3 UtsDocument6 pagesNomor 3 UtsNita FerdianaNo ratings yet
- Confusion MatrixDocument6 pagesConfusion MatrixamirNo ratings yet
- October 11, 2020: 0.1 Applied Machine Learning, Module 1: A Simple Classification TaskDocument4 pagesOctober 11, 2020: 0.1 Applied Machine Learning, Module 1: A Simple Classification TaskengsamerhozinNo ratings yet
- R Code For Discriminant and Cluster AnalysisDocument23 pagesR Code For Discriminant and Cluster AnalysisNguyễn OanhNo ratings yet
- DS LabDocument31 pagesDS Lab018 NeelimaNo ratings yet
- Ai - Phase 3Document9 pagesAi - Phase 3Manikandan NNo ratings yet
- Package Rminer': R Topics DocumentedDocument43 pagesPackage Rminer': R Topics DocumentedGayathri Prasanna ShrinivasNo ratings yet
- Package NNTRF': July 28, 2020Document7 pagesPackage NNTRF': July 28, 2020juardoNo ratings yet
- Selenium Java Environment SetupDocument7 pagesSelenium Java Environment SetupJoe1No ratings yet
- Selenium 1: Introduction To SeleniumDocument7 pagesSelenium 1: Introduction To SeleniumpriyanshuNo ratings yet
- Selenium Testing ProcessDocument9 pagesSelenium Testing ProcessJoe1No ratings yet
- Java For SeleniumDocument9 pagesJava For SeleniumJoe1No ratings yet
- Selenium Class 3 Selenium Testing Process Part 2 PDFDocument7 pagesSelenium Class 3 Selenium Testing Process Part 2 PDFJoe1No ratings yet
- POMDocument8 pagesPOMJoe1No ratings yet
- MATHDocument52 pagesMATHJoe1No ratings yet
- Troubleshooting TipsDocument3 pagesTroubleshooting TipsJoe1No ratings yet
- Employees Mod DB PDFDocument1 pageEmployees Mod DB PDFJoe1No ratings yet
- Power BIDocument32 pagesPower BIDeepak Arya100% (4)
- Data Dictionary - Unsupervised Customers PDFDocument1 pageData Dictionary - Unsupervised Customers PDFJoe1No ratings yet
- Windows Quickstart Instructions: Step 1: Download AnacondaDocument7 pagesWindows Quickstart Instructions: Step 1: Download AnacondaJoe1No ratings yet
- SQLDocument13 pagesSQLJoe1No ratings yet
- Worksheet 2Document3 pagesWorksheet 2Joe1No ratings yet
- Worksheet 1Document3 pagesWorksheet 1Joe1No ratings yet
- Business ScenarioDocument1 pageBusiness ScenarioJoe1No ratings yet
- Hive and ImpalaDocument46 pagesHive and ImpalaJoe1No ratings yet
- SELECT From NobelDocument13 pagesSELECT From NobelJoe1No ratings yet
- Big Data Hadoop and Spark Developer: Hbase SupportDocument27 pagesBig Data Hadoop and Spark Developer: Hbase SupportJoe1No ratings yet
- PigDocument39 pagesPigJoe1No ratings yet
- HDFS and YARNDocument91 pagesHDFS and YARNJoe1No ratings yet
- SELECT From WORLD TutorialDocument13 pagesSELECT From WORLD TutorialJoe1No ratings yet
- Regular Expressions in PythonDocument16 pagesRegular Expressions in PythonJoe1No ratings yet
- Knn1 HouseVotesDocument2 pagesKnn1 HouseVotesJoe1No ratings yet
- Decision Tree and EDA With Functions: Import Pandas As PDDocument9 pagesDecision Tree and EDA With Functions: Import Pandas As PDJoe1No ratings yet
- Beautiful Soup 4Document78 pagesBeautiful Soup 4Siva TarunNo ratings yet
- Random Forest: Random Forest Has Classifier For Classification and Regressor For RegressionDocument9 pagesRandom Forest: Random Forest Has Classifier For Classification and Regressor For RegressionJoe1No ratings yet
- Random Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBDocument17 pagesRandom Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBJoe1No ratings yet
- Knn1 MinMaxScalarDocument13 pagesKnn1 MinMaxScalarJoe1No ratings yet
- NycDocument12 pagesNycJoe1No ratings yet
- Optimization Process of Biodiesel Production With Ultrasound Assisted by Using Central Composite Design MethodsDocument47 pagesOptimization Process of Biodiesel Production With Ultrasound Assisted by Using Central Composite Design MethodsMiftahFakhriansyahNo ratings yet
- Contoh Reflection PaperDocument2 pagesContoh Reflection PaperClaudia KandowangkoNo ratings yet
- Supply ForecastingDocument17 pagesSupply ForecastingBhavesh RahamatkarNo ratings yet
- 4.section 3 - Routine MaintenanceDocument96 pages4.section 3 - Routine MaintenanceMyo minNo ratings yet
- E4-E5 - Text - Chapter 2. ISO 9001-2015 QUALITY MANAGEMENT SYSTEMDocument17 pagesE4-E5 - Text - Chapter 2. ISO 9001-2015 QUALITY MANAGEMENT SYSTEMAGM S&M-CMNo ratings yet
- Inversor Abb 3 8kwDocument2 pagesInversor Abb 3 8kwapi-290643326No ratings yet
- Advances in Agronomy v.84Document333 pagesAdvances in Agronomy v.84luisiunesNo ratings yet
- 20 Best Cognac CocktailsDocument1 page20 Best Cognac CocktailsHL XanticNo ratings yet
- 2nd Term Biology Ss3Document20 pages2nd Term Biology Ss3Wisdom Lawal (Wizywise)No ratings yet
- The Mystique of The Dominant WomanDocument8 pagesThe Mystique of The Dominant WomanDorothy HaydenNo ratings yet
- Full Download Small Animal Care and Management 4th Edition Warren Test BankDocument35 pagesFull Download Small Animal Care and Management 4th Edition Warren Test Bankkrzyszhugvik6100% (20)
- Babok Framework Overview: BA Planning & MonitoringDocument1 pageBabok Framework Overview: BA Planning & MonitoringJuan100% (1)
- Powador 7700 - 7900 8600 - 9600: OriginalDocument52 pagesPowador 7700 - 7900 8600 - 9600: Originalashraf-84No ratings yet
- Bonding and Adhesives in DentistryDocument39 pagesBonding and Adhesives in DentistryZahn ÄrztinNo ratings yet
- Information HumaLyzer Primus Setting Update and Extension enDocument3 pagesInformation HumaLyzer Primus Setting Update and Extension enluisoft88No ratings yet
- Rovers - CH - 2 - Drug TherapyDocument28 pagesRovers - CH - 2 - Drug TherapyKhalid Bin AliNo ratings yet
- FS011 Audit Plan Stage 2Document2 pagesFS011 Audit Plan Stage 2Ledo Houssien0% (1)
- BrainPOP Nutrition Quiz242342Document1 pageBrainPOP Nutrition Quiz242342MathableNo ratings yet
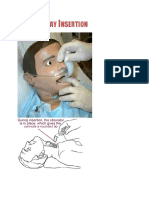
- Oral Airway InsertionDocument3 pagesOral Airway InsertionSajid HolyNo ratings yet
- 168 Visual Perceptual SkillsDocument3 pages168 Visual Perceptual Skillskonna4539No ratings yet
- Evaluation of Whole-Body Vibration (WBV) On Ready Mixed Concrete Truck DriversDocument8 pagesEvaluation of Whole-Body Vibration (WBV) On Ready Mixed Concrete Truck DriversmariaNo ratings yet
- Quotation: Kentex CargoDocument2 pagesQuotation: Kentex CargoMalueth AnguiNo ratings yet
- Msds Aluminium SulfatDocument5 pagesMsds Aluminium SulfatduckshaNo ratings yet
- Consolidation of ClayDocument17 pagesConsolidation of ClayMD Anan MorshedNo ratings yet
- 5 Keto Pancake RecipesDocument7 pages5 Keto Pancake RecipesBai Morales VidalesNo ratings yet
- Esc200 12Document1 pageEsc200 12Anzad AzeezNo ratings yet
- Safety at Hand PDFDocument48 pagesSafety at Hand PDFAdesijiBlessingNo ratings yet
- LivingScience CBSE CompanionDocument56 pagesLivingScience CBSE Companionnjlenovo95% (19)
- Sialoree BotoxDocument5 pagesSialoree BotoxJocul DivinNo ratings yet
- Diagnostic Evaluation and Management of The Solitary Pulmonary NoduleDocument21 pagesDiagnostic Evaluation and Management of The Solitary Pulmonary NoduleGonzalo Leal100% (1)