
You might also like
- The Illusion of Thin-Tails Under Aggregation - SSRN-Id1987562Document4 pagesThe Illusion of Thin-Tails Under Aggregation - SSRN-Id1987562adeka1No ratings yet
- ContinueDocument2 pagesContinuejeyabalguruNo ratings yet
- The Boom of 2021Document4 pagesThe Boom of 2021Jeff McGinnNo ratings yet
- Market Timing Sin A LittleDocument16 pagesMarket Timing Sin A LittlehaginileNo ratings yet
- Delta Surface Methodology - Implied Volatility Surface by DeltaDocument9 pagesDelta Surface Methodology - Implied Volatility Surface by DeltaShirley XinNo ratings yet
- RTD ToS Fields ExamplesDocument2 pagesRTD ToS Fields ExamplesdatsnoNo ratings yet
- Automated Trading Strategies PDFDocument64 pagesAutomated Trading Strategies PDFdebourou100% (4)
- Chicago KellyDocument94 pagesChicago KellyAlex MariusNo ratings yet
- RadioActive Trading IntroductionDocument31 pagesRadioActive Trading IntroductionRavikanth Chowdary NandigamNo ratings yet
- Optimal F and The Kelly CriterionDocument8 pagesOptimal F and The Kelly Criterionsasha_fangNo ratings yet
- HMIDocument60 pagesHMIjackh01100% (1)
- A Novice Guide To Sports Betting, 85ppDocument85 pagesA Novice Guide To Sports Betting, 85ppAsteeb100% (2)
- Microscopic Simulation of Financial Markets: From Investor Behavior to Market PhenomenaFrom EverandMicroscopic Simulation of Financial Markets: From Investor Behavior to Market PhenomenaNo ratings yet
- Engineering A Synthetic Volatility Index - Sutherland ResearchDocument3 pagesEngineering A Synthetic Volatility Index - Sutherland Researchslash7782100% (1)
- Ticker History XDocument13 pagesTicker History XferrodgaNo ratings yet
- The Missing Risk Premium: Why Low Volatility Investing WorksDocument118 pagesThe Missing Risk Premium: Why Low Volatility Investing WorksMinh NguyenNo ratings yet
- Net Net USDocument70 pagesNet Net USFloris OliemansNo ratings yet
- Zechner Low-Risk AnomaliesDocument65 pagesZechner Low-Risk AnomaliesYNo ratings yet
- Aether Analytics Strategy DeckDocument21 pagesAether Analytics Strategy DeckAlex BernalNo ratings yet
- Statistical Arbitrage 6Document7 pagesStatistical Arbitrage 6TraderCat SolarisNo ratings yet
- Scott Locklin - A Bestiary of Algorithmic Trading Strategies Locklin On ScienceDocument13 pagesScott Locklin - A Bestiary of Algorithmic Trading Strategies Locklin On Sciencetedcruz4presidentNo ratings yet
- Predatory Trading IIDocument47 pagesPredatory Trading IIAlexNo ratings yet
- SSRN Id2759734Document24 pagesSSRN Id2759734teppeiNo ratings yet
- Option Pricing Under Power Laws A RobustDocument5 pagesOption Pricing Under Power Laws A RobustLucas D'AmelioNo ratings yet
- Focus On Kase Studies, Analytics and Forecasting: Presented byDocument141 pagesFocus On Kase Studies, Analytics and Forecasting: Presented byMichael Martin100% (1)
- Volatility-Based T Hi La L I Technical Analysis: Strategies For Trading The Invisble Kirk NorthingtonDocument48 pagesVolatility-Based T Hi La L I Technical Analysis: Strategies For Trading The Invisble Kirk Northingtonbhuneshwar100% (1)
- SHILLER, Robert J. (1984) Stock Prices and Social DynamicsDocument54 pagesSHILLER, Robert J. (1984) Stock Prices and Social DynamicsDouglas de Medeiros FrancoNo ratings yet
- Moskowitz Time Series Momentum PaperDocument23 pagesMoskowitz Time Series Momentum PaperthyagosmesmeNo ratings yet
- ACM The Great Vega ShortDocument10 pagesACM The Great Vega ShortwarrenprosserNo ratings yet
- Value and Momentum EverywhereDocument58 pagesValue and Momentum EverywhereDessy ParamitaNo ratings yet
- 2016 Book HowTheFedMovesMarkets PDFDocument198 pages2016 Book HowTheFedMovesMarkets PDFbustinjeiberNo ratings yet
- Trend-Following vs. Momentum in ETFs - Alvarez Quant TradingDocument11 pagesTrend-Following vs. Momentum in ETFs - Alvarez Quant TradingcoachbiznesuNo ratings yet
- Arrow Funds RElative StrengthDocument30 pagesArrow Funds RElative Strengthompomp13No ratings yet
- Change Point DetectionDocument23 pagesChange Point DetectionSalbani ChakraborttyNo ratings yet
- Statistical Arbitrage - Part IIDocument2 pagesStatistical Arbitrage - Part IIsamuelcwlsonNo ratings yet
- Trading Manual: Indicator OverviewDocument101 pagesTrading Manual: Indicator OverviewMrugenNo ratings yet
- John Ehlers - Non Linear FiltersDocument6 pagesJohn Ehlers - Non Linear FiltersRobert PetkovNo ratings yet
- Confidence Intervals For Kelly CriterionDocument12 pagesConfidence Intervals For Kelly Criterionsuedesuede100% (1)
- Defensive Portfolio Construction Based On Extreme VaR SCHIMIELEWSKI and STOYANOVDocument9 pagesDefensive Portfolio Construction Based On Extreme VaR SCHIMIELEWSKI and STOYANOVRuTz92No ratings yet
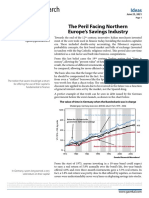
- Gavekalresearch: The Peril Facing Northern Europe'S Savings IndustryDocument3 pagesGavekalresearch: The Peril Facing Northern Europe'S Savings IndustryXavier StraussNo ratings yet
- JOIM Demystifying Managed FuturesDocument17 pagesJOIM Demystifying Managed Futuresjrallen81No ratings yet
- 172TOMLDocument4 pages172TOMLanalyst_anil14No ratings yet
- Edge Ratio of Nifty For Last 15 Years On Donchian ChannelDocument8 pagesEdge Ratio of Nifty For Last 15 Years On Donchian ChannelthesijNo ratings yet
- Model Description: Ticker NameDocument14 pagesModel Description: Ticker NameOleg KondratenkoNo ratings yet
- Societe Generale-Mind Matters-James Montier-Vanishing Value-Has The Market Rallied Too Far, Too Fast - 090520Document6 pagesSociete Generale-Mind Matters-James Montier-Vanishing Value-Has The Market Rallied Too Far, Too Fast - 090520yhlung2009No ratings yet
- SSRN Id2607730Document84 pagesSSRN Id2607730superbuddyNo ratings yet
- Aqr Words From The Wise Ed ThorpDocument22 pagesAqr Words From The Wise Ed Thorpfab62100% (1)
- Taleb PaperDocument8 pagesTaleb PaperNurtaiNo ratings yet
- 01-18-12 Stock Market Trends & ObservationsDocument163 pages01-18-12 Stock Market Trends & Observationsrkarrow100% (1)
- Half-Day Reversal - QuantPediaDocument7 pagesHalf-Day Reversal - QuantPediaJames LiuNo ratings yet
- Profile ®: IIIIIIIIIIIIIIIIIDocument346 pagesProfile ®: IIIIIIIIIIIIIIIIIWilly Pérez-Barreto MaturanaNo ratings yet
- SSRN Id593584Document28 pagesSSRN Id593584Loulou DePanamNo ratings yet
- High Probability Chart Reading John Murphy PDFDocument4 pagesHigh Probability Chart Reading John Murphy PDFomarNo ratings yet
- Introduction To Fast Fourier Transform inDocument31 pagesIntroduction To Fast Fourier Transform inALNo ratings yet
- It Pays To Be Contrary (Draft)Document24 pagesIt Pays To Be Contrary (Draft)Cornel Miron100% (1)
- The Vortex Indicator: Reliability Is Harder Than It LooksDocument5 pagesThe Vortex Indicator: Reliability Is Harder Than It Looksgochi bestNo ratings yet
- Chicago KellyDocument94 pagesChicago Kellyultr4l0rdNo ratings yet
- Cynthia Kase - Multi-Dimensional TradingDocument3 pagesCynthia Kase - Multi-Dimensional TradingGabNo ratings yet
- Zooplus Connor LeonardDocument36 pagesZooplus Connor LeonardTimmy100% (1)
- Paper On Mcap To GDPDocument20 pagesPaper On Mcap To GDPgreyistariNo ratings yet
- Artemis Capital Q12012 Volatility at Worlds End1Document18 pagesArtemis Capital Q12012 Volatility at Worlds End1Sean GreelyNo ratings yet
- Strategic and Tactical Asset Allocation: An Integrated ApproachFrom EverandStrategic and Tactical Asset Allocation: An Integrated ApproachNo ratings yet
- Smart(er) Investing: How Academic Insights Propel the Savvy InvestorFrom EverandSmart(er) Investing: How Academic Insights Propel the Savvy InvestorNo ratings yet
- The Best of Wilmott 1: Incorporating the Quantitative Finance ReviewFrom EverandThe Best of Wilmott 1: Incorporating the Quantitative Finance ReviewNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Stock IndicatorDocument2 pagesStock IndicatordatsnoNo ratings yet
- Commercial Statement of Change: Existing Registered AgentDocument2 pagesCommercial Statement of Change: Existing Registered AgentdatsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 602 946 134 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 602 946 134 Business NamedatsnoNo ratings yet
- Commercial Statement of Change: Existing Registered AgentDocument2 pagesCommercial Statement of Change: Existing Registered AgentdatsnoNo ratings yet
- Page: 1 of 2: Work Order #: 2020012800054474 - 1 Received Date: 01/28/2020 Amount Received: $0.00Document2 pagesPage: 1 of 2: Work Order #: 2020012800054474 - 1 Received Date: 01/28/2020 Amount Received: $0.00datsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Foreign Registration Statement: Ubi NumberDocument3 pagesForeign Registration Statement: Ubi NumberdatsnoNo ratings yet
- CongratulationLetterDocument1 pageCongratulationLetterdatsnoNo ratings yet
- CertificateDocument1 pageCertificatedatsnoNo ratings yet
- FilingCorrespondence CongratulationLetterDocument1 pageFilingCorrespondence CongratulationLetterdatsnoNo ratings yet
- Bias For The DayDocument28 pagesBias For The DaydatsnoNo ratings yet
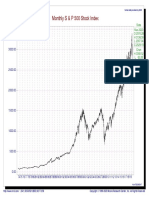
- Monthly S & P 500 Stock IndexDocument1 pageMonthly S & P 500 Stock IndexdatsnoNo ratings yet
- Basic Employee Training On Covid-19 Infection Prevention: June, 2020Document16 pagesBasic Employee Training On Covid-19 Infection Prevention: June, 2020datsnoNo ratings yet
- Guidance For Daily COVID-19 Screening of Staff and VisitorsDocument2 pagesGuidance For Daily COVID-19 Screening of Staff and VisitorsdatsnoNo ratings yet
- Guidance On Developing A COVID-19 Safety Plan For Critical InfrastructureDocument3 pagesGuidance On Developing A COVID-19 Safety Plan For Critical InfrastructuredatsnoNo ratings yet
- Aussie Dollar PDFDocument1 pageAussie Dollar PDFdatsnoNo ratings yet
- Aussie Dollar PDFDocument1 pageAussie Dollar PDFdatsnoNo ratings yet
- As of 12/31/14 10 Yrs. 25 Yrs. 50 Yrs. 75 Yrs. Since 1927 The Balanced Portfolio 60/40 Cash 1.6% 3.3% 5.4% 4.1% 3.7%Document3 pagesAs of 12/31/14 10 Yrs. 25 Yrs. 50 Yrs. 75 Yrs. Since 1927 The Balanced Portfolio 60/40 Cash 1.6% 3.3% 5.4% 4.1% 3.7%datsnoNo ratings yet
- Unified Bonds 20141008Document57 pagesUnified Bonds 20141008datsnoNo ratings yet
- Chicago Boothf Garch ScriptDocument6 pagesChicago Boothf Garch ScriptdatsnoNo ratings yet
- Column Understanding The Kelly CriterionDocument13 pagesColumn Understanding The Kelly CriterionTraderCat SolarisNo ratings yet
- Betting With The Kelly CriterionDocument9 pagesBetting With The Kelly CriterionTimNo ratings yet
- Probability and Risk Management For Sports BettingDocument95 pagesProbability and Risk Management For Sports Bettingfromthe nowNo ratings yet
- Column 24 Understanding The Kelly Criterion 2Document7 pagesColumn 24 Understanding The Kelly Criterion 2TraderCat SolarisNo ratings yet
- An Adaptive Kelly Betting Strategy For Finite Repeated GamesDocument9 pagesAn Adaptive Kelly Betting Strategy For Finite Repeated GamesDavid Esteban Meneses RendicNo ratings yet
- Can You Do Better Than Kelly in The Short Run ?: Sid BrowneDocument15 pagesCan You Do Better Than Kelly in The Short Run ?: Sid Brownecuitao42No ratings yet
- Kelly Portfolio OptimizationDocument19 pagesKelly Portfolio OptimizationRiccardo RoncoNo ratings yet
- Optimal Betting Strategy Win Draw LossDocument6 pagesOptimal Betting Strategy Win Draw Losskasjdhasd sldhasdNo ratings yet
- Kelly Criterion in Poker - ..Document2 pagesKelly Criterion in Poker - ..Brian JonesNo ratings yet
- CMT Level2 ReadingDocument8 pagesCMT Level2 ReadingNeon 02No ratings yet
- Understanding The Kelly Capital Growth Investment StrategyDocument7 pagesUnderstanding The Kelly Capital Growth Investment Strategygforce_haterNo ratings yet
- Optimal Betting Strategy Win Draw LossDocument5 pagesOptimal Betting Strategy Win Draw LossZoranMatuško0% (1)
- Winselmann Kai WHU Diss 2018Document102 pagesWinselmann Kai WHU Diss 2018David Esteban Meneses RendicNo ratings yet
- [World Scientific Handbook in Financial Economic Series] Leonard C. MacLean, Edward O. Thorp, William T. Ziemba - The Kelly Capital Growth Investment Criterion_ Theory and Practice (2011, World Scientific Publishing Company).pdfDocument883 pages[World Scientific Handbook in Financial Economic Series] Leonard C. MacLean, Edward O. Thorp, William T. Ziemba - The Kelly Capital Growth Investment Criterion_ Theory and Practice (2011, World Scientific Publishing Company).pdfArun100% (6)
- 100 Bagger NotesDocument1 page100 Bagger NotesarianashokNo ratings yet
- M Sipko PDFDocument64 pagesM Sipko PDFDenisOliveraNo ratings yet
- Best Position Sizing in TradingDocument27 pagesBest Position Sizing in TradingSiva No Fear33% (3)
- Gamblers RuinDocument6 pagesGamblers RuinKarioca No RioNo ratings yet
- Risk Over Reward: Betting Size: Kelly Criterion and Portfolio VarianceDocument4 pagesRisk Over Reward: Betting Size: Kelly Criterion and Portfolio VarianceAri David PaulNo ratings yet
- Money Management MethodsDocument18 pagesMoney Management MethodsEduardo PáezNo ratings yet
- Understanding The Kelly CriterionDocument15 pagesUnderstanding The Kelly CriterionChua Yong Sheng DarrenNo ratings yet
- Understanding Fortunes FormulaDocument5 pagesUnderstanding Fortunes FormulaTraderCat Solaris0% (2)
- Predict Total GoalsDocument40 pagesPredict Total GoalsnambanambaaaNo ratings yet
- Report Randall JF GAMBLINGDocument58 pagesReport Randall JF GAMBLINGNeeraj RaiNo ratings yet




































































































![[World Scientific Handbook in Financial Economic Series] Leonard C. MacLean, Edward O. Thorp, William T. Ziemba - The Kelly Capital Growth Investment Criterion_ Theory and Practice (2011, World Scientific Publishing Company).pdf](https://imgv2-2-f.scribdassets.com/img/document/408623297/149x198/f95008e220/1688435422?v=1)









