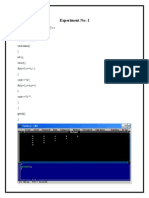
You might also like
- Vector Addition: Exercise 1 (Openmp-I) Scenario - IDocument15 pagesVector Addition: Exercise 1 (Openmp-I) Scenario - IRahul MangalNo ratings yet
- E 3 (Openmp - Iii) : Matrix MultiplicationDocument10 pagesE 3 (Openmp - Iii) : Matrix MultiplicationRahul MangalNo ratings yet
- Parallel & Distributed Computing (L31+32) : Write A Simple Openmp Program To Demonstrate The Parallel Loop ConstructDocument3 pagesParallel & Distributed Computing (L31+32) : Write A Simple Openmp Program To Demonstrate The Parallel Loop Constructmadhu agrawalNo ratings yet
- MPI Broadcast, Send-Receive & Message Size CalculationDocument7 pagesMPI Broadcast, Send-Receive & Message Size CalculationShivam AhujaNo ratings yet
- Case Study 1Document12 pagesCase Study 1Abhishek ChandramouliNo ratings yet
- Sys/types.h Sys/stat.h FCNTL.H Stdio.h Stdlib.h String.hDocument12 pagesSys/types.h Sys/stat.h FCNTL.H Stdio.h Stdlib.h String.hMohammed ElectricwalaNo ratings yet
- C Programmimg NotesDocument6 pagesC Programmimg NotesAnanya SinghNo ratings yet
- Network Simulator2 (NS2) Basic CommandsDocument4 pagesNetwork Simulator2 (NS2) Basic Commandshariharanpotter100% (7)
- Program For Bankers Algorithm For Deadlock Avoidance in CDocument6 pagesProgram For Bankers Algorithm For Deadlock Avoidance in CKarunakar EllaNo ratings yet
- C ProgrammingDocument39 pagesC ProgrammingSurya Padma100% (1)
- Python - M4Assignment SolutionDocument2 pagesPython - M4Assignment SolutionSudeeksha RavikotiNo ratings yet
- Tybcs PHPDocument33 pagesTybcs PHPPrashant JachakNo ratings yet
- Practical Slip Mcs Sem 3 Pune UniversityDocument4 pagesPractical Slip Mcs Sem 3 Pune UniversityAtul Galande0% (1)
- System Programming Lab Report 04Document12 pagesSystem Programming Lab Report 04Abdul RehmanNo ratings yet
- Employee table queries and PL/SQL programsDocument13 pagesEmployee table queries and PL/SQL programsKarthik Nsp50% (2)
- Computer Project 12 Class CBSEDocument23 pagesComputer Project 12 Class CBSENitish Jadia87% (45)
- BCA Practical ExercisesDocument12 pagesBCA Practical Exercisesanon_355047517100% (1)
- DS LabDocument16 pagesDS LabAmit Pandey50% (4)
- Few Shell Programming For Computer Science StudentsDocument28 pagesFew Shell Programming For Computer Science StudentsTanay MondalNo ratings yet
- Oops Lab FileDocument57 pagesOops Lab Filegamer king100% (1)
- C# Practical FileDocument15 pagesC# Practical FileAnshumanSrivastavNo ratings yet
- Lab ManualDocument50 pagesLab ManualPooja PrakashNo ratings yet
- System Software Lab ProgramsDocument22 pagesSystem Software Lab ProgramsAbhi Shek100% (1)
- Implementation of Code Optimization Techniques (Constant FoldingDocument21 pagesImplementation of Code Optimization Techniques (Constant FoldingDivya PriyaNo ratings yet
- TCS Input and OutputDocument8 pagesTCS Input and OutputChannu HiremathNo ratings yet
- Final StringDocument121 pagesFinal StringDayanidhiDani100% (2)
- Objective C MCQ Questions and AnswersDocument6 pagesObjective C MCQ Questions and Answersharsh5991No ratings yet
- Java CodingDocument332 pagesJava Codingakbarviveka_16156616100% (4)
- Lab ManualDocument86 pagesLab ManualabdNo ratings yet
- Capgemini Frequent Questions+Previous YearDocument57 pagesCapgemini Frequent Questions+Previous YearAyushi BoliaNo ratings yet
- Python Main Programs Set 1Document10 pagesPython Main Programs Set 1KEERTHI PRASANTH S BSC-CS(2022-23)No ratings yet
- Implement Lamport Clock Synchronization AlgorithmDocument14 pagesImplement Lamport Clock Synchronization AlgorithmKishore Kumar BoggulaNo ratings yet
- Q.2:Write A Java Program To Simulate Traffic Signal Using Multithreading. AnsDocument2 pagesQ.2:Write A Java Program To Simulate Traffic Signal Using Multithreading. AnsPrasad DutandeNo ratings yet
- Cricket Score Management Mini Project PDF FreeDocument21 pagesCricket Score Management Mini Project PDF FreeAmit mahi0% (1)
- Cquiz 2Document4 pagesCquiz 2simNo ratings yet
- 1.1. Establishing A Local Area Network LANDocument5 pages1.1. Establishing A Local Area Network LANராஜ்குமார் கந்தசாமிNo ratings yet
- Practical-8: Create An Application in Android To Find Factorial of A Given Number Using Onclick EventDocument4 pagesPractical-8: Create An Application in Android To Find Factorial of A Given Number Using Onclick EventhdtrsNo ratings yet
- 15 Programs On PythonDocument6 pages15 Programs On PythonREDDY SARAGADANo ratings yet
- CN LabDocument50 pagesCN LabSockalinganathan NarayananNo ratings yet
- Java Program to Calculate Area of Circle in 5 Different WaysDocument5 pagesJava Program to Calculate Area of Circle in 5 Different WaysIrfaan Khan QasmiNo ratings yet
- Experiment No:1 Three Node Point To Point Network Aim: Simulate A Three Node Point To Point Network With Duplex Links Between Them. Set Queue Size andDocument19 pagesExperiment No:1 Three Node Point To Point Network Aim: Simulate A Three Node Point To Point Network With Duplex Links Between Them. Set Queue Size andgopinath RNo ratings yet
- Oracle Practical FileDocument9 pagesOracle Practical FileKarandeep Singh100% (2)
- BCA ProjectDocument12 pagesBCA ProjectSamala RajNo ratings yet
- Aim: Program:: Implement The Data Link Layer Framing Methods Such As Character CountDocument21 pagesAim: Program:: Implement The Data Link Layer Framing Methods Such As Character CountUmme Aaiman100% (1)
- Capability5 AssignmentDocument3 pagesCapability5 AssignmentBarbarous ShuvankarNo ratings yet
- Shell Script AlgorithmsDocument8 pagesShell Script AlgorithmsMariya James50% (2)
- Java EE694cDocument8 pagesJava EE694carchana100% (1)
- Create A Socket For HTTP For Web Page Upload and DownloadDocument15 pagesCreate A Socket For HTTP For Web Page Upload and DownloadAshish mandalNo ratings yet
- Cs8383 Oops Lab ManualDocument81 pagesCs8383 Oops Lab ManualKarthik Subramani83% (12)
- TYBCA Practical On Multithreading (File2) SolutionsDocument12 pagesTYBCA Practical On Multithreading (File2) SolutionspriyankaNo ratings yet
- 100 Shell Programs in Unix: Solutions and ExamplesDocument55 pages100 Shell Programs in Unix: Solutions and ExamplesRavinderNo ratings yet
- Data Structures and Algorithms LAB FileDocument47 pagesData Structures and Algorithms LAB FilemayankNo ratings yet
- JAVA LAB MANUALDocument28 pagesJAVA LAB MANUALMegha GargNo ratings yet
- Microprocessors Lab Viva Voce Questions 10CSL48Document4 pagesMicroprocessors Lab Viva Voce Questions 10CSL48Justin WalkerNo ratings yet
- Oops Assignment 1Document3 pagesOops Assignment 1MikeSteveNo ratings yet
- Lab Manual C++Document24 pagesLab Manual C++Sagar ManeNo ratings yet
- Face Prep Capgemini Slot Analysis 23rd Aug 2021 Slot 1Document17 pagesFace Prep Capgemini Slot Analysis 23rd Aug 2021 Slot 1HRitik SharmaNo ratings yet
- Data Structure by AnimationDocument4 pagesData Structure by AnimationSENTHIL RNo ratings yet
- UNIX Practical QuestionsDocument5 pagesUNIX Practical QuestionsRonda Cummings100% (1)
- Exercise 1 (Openmp-I)Document10 pagesExercise 1 (Openmp-I)Dhruv SakhujaNo ratings yet
- HTML Form ElementsDocument8 pagesHTML Form ElementsRahul MangalNo ratings yet
- Form Elements in JavaDocument7 pagesForm Elements in JavaRahul MangalNo ratings yet
- C-19/11 Vasant Vihar Colony ResumeDocument2 pagesC-19/11 Vasant Vihar Colony ResumeRahul MangalNo ratings yet
- Java Programming Course Code, Objectives and OutcomesDocument10 pagesJava Programming Course Code, Objectives and OutcomesRahul Mangal0% (1)
- CSE 3099 Industrial Internship Viva Voce Panel Details - Phase-I - Students - 18-09-2019Document31 pagesCSE 3099 Industrial Internship Viva Voce Panel Details - Phase-I - Students - 18-09-2019Rahul MangalNo ratings yet
- AWS Storage Gateway - User Guide - API Version 30-06-2013Document523 pagesAWS Storage Gateway - User Guide - API Version 30-06-2013Jonathan RuverNo ratings yet
- The software tools that enable user interaction are called applicationsDocument7 pagesThe software tools that enable user interaction are called applicationshinaavermaNo ratings yet
- Interfacing GLCD With LPC2148 ARM: Arm How-To GuideDocument21 pagesInterfacing GLCD With LPC2148 ARM: Arm How-To GuideShubham JadhavNo ratings yet
- W970suw PDFDocument104 pagesW970suw PDFEdu Kees MorelloNo ratings yet
- Configure Static IP Address On Ubuntu 20 04 ServerDocument3 pagesConfigure Static IP Address On Ubuntu 20 04 ServerFavour GodspowerNo ratings yet
- Windows Display Driver Model EnhancementsDocument60 pagesWindows Display Driver Model EnhancementsPrashant GautamNo ratings yet
- A Comprehensive Survey On Resource Allocation Strategies in Fog - Cloud Environments - Sensors-23-04413Document25 pagesA Comprehensive Survey On Resource Allocation Strategies in Fog - Cloud Environments - Sensors-23-04413Serge WouansiNo ratings yet
- Distributed Systems Exercise IDocument2 pagesDistributed Systems Exercise IKorir KevynneNo ratings yet
- How To Write An OData Channel Gateway Service. Part 2 - The Runtime Data Provider ClassDocument39 pagesHow To Write An OData Channel Gateway Service. Part 2 - The Runtime Data Provider Class263497No ratings yet
- Howto Unicode PDFDocument13 pagesHowto Unicode PDFMonish PNo ratings yet
- File HandlingDocument3 pagesFile HandlingMahesh Chandra UpadhyayNo ratings yet
- Design Method of CAN BUS Network Communication Structure For Electric VehicleDocument4 pagesDesign Method of CAN BUS Network Communication Structure For Electric VehicleEdda RdaaNo ratings yet
- Bina Sarana Informatika: Computer NetworkingDocument23 pagesBina Sarana Informatika: Computer NetworkingSaepul SabioNo ratings yet
- Dellemc Poweredge Brochure PDFDocument14 pagesDellemc Poweredge Brochure PDFAther AliNo ratings yet
- ZabbixDocument45 pagesZabbixRodulfo Enrique González BairesNo ratings yet
- Intel Update ProcedureDocument5 pagesIntel Update Proceduretiara_kusumaningtyasNo ratings yet
- SCADAPack 32 ControllerDocument66 pagesSCADAPack 32 Controllersergio_costa_28No ratings yet
- Gurpreet Singh Bedi - CVDocument1 pageGurpreet Singh Bedi - CVGurpreet SinghNo ratings yet
- Commodore World Issue 04Document60 pagesCommodore World Issue 04Steven D100% (1)
- Software SpecificationDocument3 pagesSoftware SpecificationJustine TorioNo ratings yet
- PARTSDocument5 pagesPARTSJosh TuibeoNo ratings yet
- Honeywell - Icon ConsolesDocument4 pagesHoneywell - Icon ConsolesBouazzaNo ratings yet
- MINIKIT Neo 2 HD - User Guide - UK PDFDocument16 pagesMINIKIT Neo 2 HD - User Guide - UK PDFZamfir ConstantinNo ratings yet
- Lab Tutorial SlidesDocument72 pagesLab Tutorial SlidesssbhfmstNo ratings yet
- Logcat 1592929311484Document11 pagesLogcat 1592929311484Leonardo HoyoNo ratings yet
- CS4000 Service and Maintenance Manual PDFDocument72 pagesCS4000 Service and Maintenance Manual PDFAthul Tuttu100% (1)
- OOP Vs SPDocument3 pagesOOP Vs SPWynster Suemitsu CaloniaNo ratings yet
- Toad Data Point Datasheet 68635 PDFDocument2 pagesToad Data Point Datasheet 68635 PDFAshrafulNo ratings yet
- 0RECORDMODE and Delta Type Concepts in Delta ManagementDocument11 pages0RECORDMODE and Delta Type Concepts in Delta ManagementBharath PamarthiNo ratings yet
- TI Silent700 Acm 72Document4 pagesTI Silent700 Acm 72Delbert RicardoNo ratings yet