You might also like
- Geeks GraphDocument107 pagesGeeks GraphBHARAT SINGH RAJPUROHITNo ratings yet
- Graphs: by Sonia SoansDocument18 pagesGraphs: by Sonia SoanstvsnNo ratings yet
- Unit-5: Exploring GraphsDocument77 pagesUnit-5: Exploring GraphsHACKER SPACENo ratings yet
- DFS algorithm for traversing trees and graphsDocument6 pagesDFS algorithm for traversing trees and graphsAhmad Ibrahem IbdahNo ratings yet
- Unit - 5Document34 pagesUnit - 5Sanjay KumarNo ratings yet
- oneDocument9 pagesoneawaz mustafaNo ratings yet
- GraphsDocument49 pagesGraphssocekay372No ratings yet
- DS-unit IVDocument32 pagesDS-unit IVashleyyychan06No ratings yet
- Daa NotesDocument193 pagesDaa Notesviswanath kaniNo ratings yet
- Ds Unit 5 (Graphs)Document35 pagesDs Unit 5 (Graphs)ashishmohan625No ratings yet
- Graph TraversalDocument4 pagesGraph TraversalnemonizerNo ratings yet
- Assignment # 06: Graph Search TechnquesDocument11 pagesAssignment # 06: Graph Search TechnquesAhmad MasoodNo ratings yet
- Graph Applications and AlgorithmsDocument66 pagesGraph Applications and AlgorithmssudhanNo ratings yet
- Graphs and AlgorithmsDocument7 pagesGraphs and AlgorithmsYing ChowNo ratings yet
- Archie P. Amparo MCS 501: August 11, 2012Document9 pagesArchie P. Amparo MCS 501: August 11, 2012apamparoNo ratings yet
- Ads Unit - 3Document225 pagesAds Unit - 3MonicaNo ratings yet
- GRAPHSDocument4 pagesGRAPHSNaseer AhmedNo ratings yet
- Search Algorithms in AI6Document17 pagesSearch Algorithms in AI6jhn75070No ratings yet
- Undirected GraphsDocument33 pagesUndirected GraphsAbdurezak ShifaNo ratings yet
- 2 Digital Modulations-1Document9 pages2 Digital Modulations-1Sajjad ali KhaskheliNo ratings yet
- Week 12Document7 pagesWeek 12Mohammad AbidNo ratings yet
- Trees and Graphs3Document13 pagesTrees and Graphs3Ria thanickaNo ratings yet
- BFS-DFS - Comparison of Breadth First Search and Depth First Search AlgorithmsDocument2 pagesBFS-DFS - Comparison of Breadth First Search and Depth First Search AlgorithmsPark JiminNo ratings yet
- DFS and BFS algorithmsDocument3 pagesDFS and BFS algorithmsakshat sharmaNo ratings yet
- Breadth First SearchDocument8 pagesBreadth First SearchsaumyaNo ratings yet
- DATA STRUCTURES AND ALGORITHMS - Unit 5Document35 pagesDATA STRUCTURES AND ALGORITHMS - Unit 5BOMMA SRI MUKHINo ratings yet
- Solution of Data Structure ST-2 PDFDocument21 pagesSolution of Data Structure ST-2 PDFharshitNo ratings yet
- Data Structures and Algorithm: GraphsDocument28 pagesData Structures and Algorithm: GraphsAman BazeNo ratings yet
- DS 3Document45 pagesDS 3Sreehari ENo ratings yet
- Graph Algorithms GuideDocument19 pagesGraph Algorithms GuideMrinmoy3003No ratings yet
- Progcomp Training Week 4Document5 pagesProgcomp Training Week 4Cheng LuNo ratings yet
- GraphDocument26 pagesGraphgabnarag2No ratings yet
- Data Structures Module 4 QB Complete SolutionsDocument37 pagesData Structures Module 4 QB Complete Solutions22951a67h8No ratings yet
- GeorgiaTech CS-6515: Graduate Algorithms: Graph Algorithms Flashcards by Yang Hu - BrainscapeDocument4 pagesGeorgiaTech CS-6515: Graduate Algorithms: Graph Algorithms Flashcards by Yang Hu - BrainscapeJan_SuNo ratings yet
- Week 11 GraphsDocument51 pagesWeek 11 Graphsnthha.ityuNo ratings yet
- GRAPHSDocument10 pagesGRAPHSsuperhigh06No ratings yet
- Unit 05 DSDocument27 pagesUnit 05 DSPavaniNo ratings yet
- GraphsDocument39 pagesGraphshamza4happinessNo ratings yet
- Implementation of BFS and DFS in Python Without Using Any Library FunctionDocument4 pagesImplementation of BFS and DFS in Python Without Using Any Library FunctionMaisha MashiataNo ratings yet
- Depth-First Search (DFS) Is An Algorithm For TraversingDocument7 pagesDepth-First Search (DFS) Is An Algorithm For TraversingShahnaj ParvinNo ratings yet
- JNTUA Artificial Intelligence Lab Manual R20Document33 pagesJNTUA Artificial Intelligence Lab Manual R20lalithasree2020No ratings yet
- Sarthak Tomar53 Unit-4 DAADocument9 pagesSarthak Tomar53 Unit-4 DAAHarsh Vardhan HBTUNo ratings yet
- Graph Chapter DFS and ApplicationsDocument7 pagesGraph Chapter DFS and ApplicationsMöušťåfåMåhṁöudNo ratings yet
- GraphDocument15 pagesGraphmugiii321No ratings yet
- Pathfinding and Graph Search AlgorithmsDocument15 pagesPathfinding and Graph Search AlgorithmsNasser SalehNo ratings yet
- Discrete Structure PresentationDocument34 pagesDiscrete Structure PresentationFᴀsᴇᴇʜ̶ ʜ̶ᴀʀᴏᴏɴNo ratings yet
- Grade 10. 3.9-3.13Document36 pagesGrade 10. 3.9-3.13Улдана ГарифоллакызыNo ratings yet
- Breadth-First Search (BFS) Is An Algorithm ForDocument4 pagesBreadth-First Search (BFS) Is An Algorithm ForOrly DahanNo ratings yet
- E-Lecture Data Structures and AlgorithmsDocument66 pagesE-Lecture Data Structures and AlgorithmsManish KumarNo ratings yet
- I008 - Khemal - Experiment - PAI - 2Document10 pagesI008 - Khemal - Experiment - PAI - 2Khemal DesaiNo ratings yet
- Implementing Bubble Sort AlgorithmDocument6 pagesImplementing Bubble Sort AlgorithmhariniNo ratings yet
- Advance Data StructureDocument6 pagesAdvance Data StructureNeha RaiNo ratings yet
- BFS DFS ReferenceDocument4 pagesBFS DFS ReferenceThomas RamosNo ratings yet
- TheoryDocument82 pagesTheoryNibedan PalNo ratings yet
- DSC Unit-4Document30 pagesDSC Unit-4Bandi SirishaNo ratings yet
- GraphsDocument7 pagesGraphsEklavya SudanNo ratings yet
- CS3401 ALG UNIT 2 NOTES EduEnggDocument25 pagesCS3401 ALG UNIT 2 NOTES EduEnggSabeshNo ratings yet
- DS Q ADocument28 pagesDS Q Akingsourabh1074No ratings yet
- Shamil March Diploma Report On Procurement StagesDocument4 pagesShamil March Diploma Report On Procurement StagesShamil IqbalNo ratings yet
- STP Analysis On Hero Lectro Electric Cycle: Assignment - IDocument2 pagesSTP Analysis On Hero Lectro Electric Cycle: Assignment - IShamil Iqbal100% (2)
- Shamil Diploma March PLC Stages of NokiaDocument2 pagesShamil Diploma March PLC Stages of NokiaShamil IqbalNo ratings yet
- Assignment Indigo LCCDocument1 pageAssignment Indigo LCCShamil IqbalNo ratings yet
- Assignment Vaccine ExportDocument2 pagesAssignment Vaccine ExportShamil IqbalNo ratings yet
- Assignment Shamil March Diploma SustainabilityDocument2 pagesAssignment Shamil March Diploma SustainabilityShamil IqbalNo ratings yet
- Alang Port - World's Largest Ship GraveyardDocument2 pagesAlang Port - World's Largest Ship GraveyardShamil IqbalNo ratings yet
- Assignment Indigo LCCDocument1 pageAssignment Indigo LCCShamil IqbalNo ratings yet
- 18bca0045 VL2019205003182 DaDocument12 pages18bca0045 VL2019205003182 DaShamil IqbalNo ratings yet
- Canadian Institutions Providing Logistics CoursesDocument1 pageCanadian Institutions Providing Logistics CoursesShamil IqbalNo ratings yet
- Learn Java Programming Fundamentals in this CourseDocument2 pagesLearn Java Programming Fundamentals in this CourseShamil IqbalNo ratings yet
- Copy FileDocument3 pagesCopy FileShamil IqbalNo ratings yet
- Cbm&Volume WeightDocument1 pageCbm&Volume WeightShamil IqbalNo ratings yet
- STP Analysis On Hero Lectro Electric Cycle: Assignment - IDocument2 pagesSTP Analysis On Hero Lectro Electric Cycle: Assignment - IShamil Iqbal100% (2)
- Cpu SchedulingDocument15 pagesCpu SchedulingShamil IqbalNo ratings yet
- Linux 2Document10 pagesLinux 2Shamil IqbalNo ratings yet
- Cpu SchedulingDocument15 pagesCpu SchedulingShamil IqbalNo ratings yet
- MCA Entrance SyllabusDocument4 pagesMCA Entrance SyllabusShamil IqbalNo ratings yet
- Java Assessment 2Document16 pagesJava Assessment 2Shamil IqbalNo ratings yet
- Cpu SchedulingDocument15 pagesCpu SchedulingShamil IqbalNo ratings yet
- Assessment Linux 2Document7 pagesAssessment Linux 2Shamil IqbalNo ratings yet
- Ba 18bca0045Document10 pagesBa 18bca0045Shamil IqbalNo ratings yet
- Railway Reservation Oops ProjectDocument24 pagesRailway Reservation Oops ProjectShamil IqbalNo ratings yet
- Quick SortDocument4 pagesQuick SortShamil IqbalNo ratings yet
- Ds Da-2 Lab 18bca0045Document23 pagesDs Da-2 Lab 18bca0045Shamil IqbalNo ratings yet
- HW 1 SolnDocument3 pagesHW 1 Solngooseneck06No ratings yet
- 207B-Discrete Mathematics PDFDocument18 pages207B-Discrete Mathematics PDFAjaySharmaNo ratings yet
- Inf 3015 - GraphDocument14 pagesInf 3015 - GraphLyse NdifoNo ratings yet
- Qurtuba University BFS Algorithm ScenarioDocument7 pagesQurtuba University BFS Algorithm ScenarioWasim SajjadNo ratings yet
- Understanding Probability 3rd Edition. Henk Tijms. Cambridge University Press 2012.Document6 pagesUnderstanding Probability 3rd Edition. Henk Tijms. Cambridge University Press 2012.Chavobar0% (2)
- Problem StatementsDocument18 pagesProblem StatementsNishant GauravNo ratings yet
- Biteranta John Vincent - 2nd Year BsitDocument29 pagesBiteranta John Vincent - 2nd Year Bsitapi-619829083No ratings yet
- GMF Unit 1 SA Exam 2018Document14 pagesGMF Unit 1 SA Exam 2018PNo ratings yet
- Algorithms: Minimum Spanning Trees (MST) SolutionsDocument14 pagesAlgorithms: Minimum Spanning Trees (MST) SolutionsergrehgeNo ratings yet
- The Graph Tech Ecosystem Visualization LinkuriousDocument117 pagesThe Graph Tech Ecosystem Visualization Linkurious1977amNo ratings yet
- Myp - Fpip - Command TermsDocument3 pagesMyp - Fpip - Command Termsapi-207781408No ratings yet
- AIML Lab FileDocument5 pagesAIML Lab FileAyush KarleNo ratings yet
- Lecture 2 - Uniformed SearchDocument50 pagesLecture 2 - Uniformed SearchMamunur RashidNo ratings yet
- Social Media Minning Chapter 6Document42 pagesSocial Media Minning Chapter 6Raul Andres Camacho CruzNo ratings yet
- MCQ on Discrete Mathematics TopicsDocument6 pagesMCQ on Discrete Mathematics TopicsBoomika.S 5009No ratings yet
- GraphTheory SlidesDocument84 pagesGraphTheory SlidessharmaegayangosNo ratings yet
- Data Structures Lab: List of ExercisesDocument28 pagesData Structures Lab: List of ExercisesPranav KumarNo ratings yet
- Introduction to Graphs (Part I-IIIDocument69 pagesIntroduction to Graphs (Part I-IIIKaushil KundaliaNo ratings yet
- Networkx: Network Analysis With PythonDocument47 pagesNetworkx: Network Analysis With PythonAnonymous 8gkFKi8EzNo ratings yet
- Recognizing Relating Edges in Graphs Without Cycles of Length 6Document10 pagesRecognizing Relating Edges in Graphs Without Cycles of Length 6OBXONo ratings yet
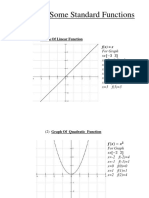
- Graphs of standard functions visualizedDocument12 pagesGraphs of standard functions visualizedghazi membersNo ratings yet
- Lecture 13 State Minimization of Sequential MachinesDocument42 pagesLecture 13 State Minimization of Sequential MachinesShiraz HusainNo ratings yet
- Title: Implement Depth-First Search: Department of Computer Science and EngineeringDocument5 pagesTitle: Implement Depth-First Search: Department of Computer Science and EngineeringSazeda SultanaNo ratings yet
- Methods and Models For Combinatorial OptimizationDocument17 pagesMethods and Models For Combinatorial OptimizationVictor Hugo Males BravoNo ratings yet
- CS 6505 Lectures 3 & 4: Greedy Algorithms and MatroidsDocument5 pagesCS 6505 Lectures 3 & 4: Greedy Algorithms and MatroidsDineshGargNo ratings yet
- Signal Flow Graphs LectureDocument41 pagesSignal Flow Graphs Lecturedanish azharNo ratings yet
- ASSIGNMENT-4 SolutionDocument5 pagesASSIGNMENT-4 SolutionpriyanshuNo ratings yet
- CurriculumSyllabusBTCS 1 1 1Document60 pagesCurriculumSyllabusBTCS 1 1 1abhyudaya_anandNo ratings yet
- Assignment 4solutionDocument5 pagesAssignment 4solutionSherin zafarNo ratings yet