You might also like
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- KRA2Document1 pageKRA2Keppy AricangoyNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Probability and StatisticsDocument4 pagesProbability and StatisticsKeppy AricangoyNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Input Data Sheet For E-Class Record: Region Division School Name School Id School YearDocument24 pagesInput Data Sheet For E-Class Record: Region Division School Name School Id School YearKeppy AricangoyNo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- History of Geometry (Hand-Out)Document4 pagesHistory of Geometry (Hand-Out)Keppy Aricangoy100% (1)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Input Data Sheet For E-Class Record: Region Division School Name School Id School YearDocument24 pagesInput Data Sheet For E-Class Record: Region Division School Name School Id School YearKeppy AricangoyNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Learning Environment and Diversity of LearnersDocument1 pageLearning Environment and Diversity of LearnersKeppy AricangoyNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- KRA3Document1 pageKRA3Keppy AricangoyNo ratings yet
- Content Knowledge and PedagogyDocument1 pageContent Knowledge and PedagogyKeppy AricangoyNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Input Data Sheet For E-Class Record: Region Division School Name School Id School YearDocument19 pagesInput Data Sheet For E-Class Record: Region Division School Name School Id School YearKeppy AricangoyNo ratings yet
- Class Record: Region Ivision School Name School Id School YearDocument26 pagesClass Record: Region Ivision School Name School Id School YearKeppy AricangoyNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- SALN Form 2017 Downloadable Word and PDF FileDocument2 pagesSALN Form 2017 Downloadable Word and PDF FileKeppy AricangoyNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- A TeacherDocument1 pageA TeacherKeppy AricangoyNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Bel Is Elementary School Test Item Analysis in Music V: Total Mastery LevelDocument2 pagesBel Is Elementary School Test Item Analysis in Music V: Total Mastery LevelKeppy AricangoyNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Student Teacher'S Daily Evaluation Sheet On/Off-Campus InternshipDocument2 pagesStudent Teacher'S Daily Evaluation Sheet On/Off-Campus InternshipKeppy AricangoyNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Input Data Sheet For E-Class Record: Region Division School Name School Id School YearDocument11 pagesInput Data Sheet For E-Class Record: Region Division School Name School Id School YearKeppy AricangoyNo ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Clearance: Experiential Learning OfficeDocument1 pageClearance: Experiential Learning OfficeKeppy AricangoyNo ratings yet
- Profile CTDocument1 pageProfile CTKeppy AricangoyNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- CertificationDocument1 pageCertificationKeppy AricangoyNo ratings yet
- Final PaperDocument17 pagesFinal PaperKeppy AricangoyNo ratings yet
- Best LPDocument3 pagesBest LPKeppy AricangoyNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- ActivitiesDocument3 pagesActivitiesKeppy AricangoyNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
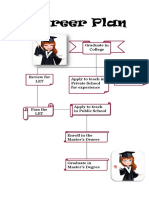
- Career PlanDocument1 pageCareer PlanKeppy AricangoyNo ratings yet
- Algebra IndexDocument10 pagesAlgebra IndexKeppy AricangoyNo ratings yet
- Given The Sequenc1Document1 pageGiven The Sequenc1Keppy AricangoyNo ratings yet
- WaysDocument1 pageWaysKeppy AricangoyNo ratings yet
- Observation 2Document2 pagesObservation 2Keppy AricangoyNo ratings yet
- OBDocument3 pagesOBKeppy AricangoyNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- History of Geometry (Hand-Out)Document4 pagesHistory of Geometry (Hand-Out)Keppy Aricangoy100% (1)
- Observation 3Document1 pageObservation 3Keppy AricangoyNo ratings yet
- Assignment 1 PDFDocument4 pagesAssignment 1 PDFVincent YanNo ratings yet
- GENG5507 STATS Lecture Week1 IntroductionDocument22 pagesGENG5507 STATS Lecture Week1 IntroductionRuby WrightNo ratings yet
- 38a Simultaneous Equations - H - Question PaperDocument11 pages38a Simultaneous Equations - H - Question PaperStories By SanahNo ratings yet
- Mathematics: Quarter 2 - Module 1Document33 pagesMathematics: Quarter 2 - Module 1Yanyan Alfante80% (5)
- CH15 - Chemical - Equilibrium - Compatibility ModeDocument20 pagesCH15 - Chemical - Equilibrium - Compatibility ModeRuth AjieNo ratings yet
- Integer and Mixed Integer Linear Programs: Center For Transportation & LogisticsDocument41 pagesInteger and Mixed Integer Linear Programs: Center For Transportation & Logisticsramchand sovaniNo ratings yet
- QB of MathsDocument6 pagesQB of MathsashutoshNo ratings yet
- QUIZZESDocument10 pagesQUIZZESJocel CanatoyNo ratings yet
- STM Unit 3 - Domain TestingDocument11 pagesSTM Unit 3 - Domain TestingSanthosh MaddilaNo ratings yet
- Java-Fundamentals-Regular-Expressions-ExerciseDocument6 pagesJava-Fundamentals-Regular-Expressions-Exerciseamaya fallsNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Library GenesisDocument9 pagesLibrary GenesisEzie Neill Farro0% (1)
- MTH 215 MATH 215 mth215 Math 215 QUANTITATIVE REASONING IDocument24 pagesMTH 215 MATH 215 mth215 Math 215 QUANTITATIVE REASONING IBestMATHcourseNo ratings yet
- Searching and Sorting AlgorithmsDocument9 pagesSearching and Sorting AlgorithmsMartine Mpandamwike Jr.No ratings yet
- Third Periodical Exam in Math 8Document3 pagesThird Periodical Exam in Math 8Jewel Pj100% (1)
- Level - 1: (Problems Based On Fundamentals) Basic Concepts of Real FunctionsDocument49 pagesLevel - 1: (Problems Based On Fundamentals) Basic Concepts of Real FunctionsA Good YoutuberNo ratings yet
- Personal StatementDocument3 pagesPersonal StatementNathan PearsonNo ratings yet
- Extra Credit Proof of Fundamental TheoremDocument15 pagesExtra Credit Proof of Fundamental TheoremDaniel KozakevichNo ratings yet
- Sparsem: A Sparse Matrix Package For RDocument9 pagesSparsem: A Sparse Matrix Package For Ranibal.vmezaNo ratings yet
- Math 6 - Q1WK7 - Day 2Document15 pagesMath 6 - Q1WK7 - Day 2Jeffrey Catacutan FloresNo ratings yet
- SparkNotes - SAT Subject Test - Math Level 2 - Trigonometric Identities PDFDocument5 pagesSparkNotes - SAT Subject Test - Math Level 2 - Trigonometric Identities PDFjkll12345No ratings yet
- Math 112-Plane and Spherical Trigometry SyllabusDocument2 pagesMath 112-Plane and Spherical Trigometry SyllabusHarold Taylor0% (1)
- Proposal AzDocument15 pagesProposal AzwesigashuNo ratings yet
- ch3 PDFDocument34 pagesch3 PDFAndrew BorgNo ratings yet
- A&P 2401 Lab SyllabusDocument6 pagesA&P 2401 Lab SyllabusCesar GarciaNo ratings yet
- Math 37 Course GuideDocument4 pagesMath 37 Course GuidePau BorlagdanNo ratings yet
- EMT 3200 Group #4 Curve FittingDocument50 pagesEMT 3200 Group #4 Curve FittingelioNo ratings yet
- Scie Method Lesson 4Document8 pagesScie Method Lesson 4vicNo ratings yet
- Chapter 1 Digital Systems and Binary NumbersDocument100 pagesChapter 1 Digital Systems and Binary NumbersVandana JoshiNo ratings yet
- Math 1210 Course ReflectionDocument2 pagesMath 1210 Course Reflectionapi-404828055No ratings yet
- 04 - Logic Gates and Boolean AlgebraDocument44 pages04 - Logic Gates and Boolean AlgebraGirishNo ratings yet
- Quantum Spirituality: Science, Gnostic Mysticism, and Connecting with Source ConsciousnessFrom EverandQuantum Spirituality: Science, Gnostic Mysticism, and Connecting with Source ConsciousnessRating: 4 out of 5 stars4/5 (6)
- Packing for Mars: The Curious Science of Life in the VoidFrom EverandPacking for Mars: The Curious Science of Life in the VoidRating: 4 out of 5 stars4/5 (1395)
- Summary and Interpretation of Reality TransurfingFrom EverandSummary and Interpretation of Reality TransurfingRating: 5 out of 5 stars5/5 (5)
- Knocking on Heaven's Door: How Physics and Scientific Thinking Illuminate the Universe and the Modern WorldFrom EverandKnocking on Heaven's Door: How Physics and Scientific Thinking Illuminate the Universe and the Modern WorldRating: 3.5 out of 5 stars3.5/5 (64)
- A Beginner's Guide to Constructing the Universe: The Mathematical Archetypes of Nature, Art, and ScienceFrom EverandA Beginner's Guide to Constructing the Universe: The Mathematical Archetypes of Nature, Art, and ScienceRating: 4 out of 5 stars4/5 (51)
- Dark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseFrom EverandDark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseRating: 3.5 out of 5 stars3.5/5 (69)
- A Brief History of Time: From the Big Bang to Black HolesFrom EverandA Brief History of Time: From the Big Bang to Black HolesRating: 4 out of 5 stars4/5 (2193)