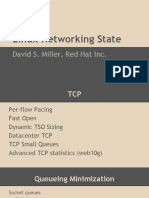
You might also like
- Fabric Proposal: A Raft-Based Ordering ServiceDocument33 pagesFabric Proposal: A Raft-Based Ordering ServiceVishal YadavNo ratings yet
- B: Providing Transparent and Generic BFT-Based Ordering Services For BlockchainsDocument10 pagesB: Providing Transparent and Generic BFT-Based Ordering Services For Blockchainszhao yiranNo ratings yet
- WAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksFrom EverandWAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksNo ratings yet
- Contentos 2.0 Sharding Strategy Based on DAppsDocument10 pagesContentos 2.0 Sharding Strategy Based on DAppsMr HungggNo ratings yet
- Ethernet Storage Guy Multimode VIF - 1597495433Document42 pagesEthernet Storage Guy Multimode VIF - 1597495433George ZavalisNo ratings yet
- Section 1 - Troubleshoot Basic Virtual Server Connectivity Issues PDFDocument31 pagesSection 1 - Troubleshoot Basic Virtual Server Connectivity Issues PDFCCNA classNo ratings yet
- Blockchain ppt3Document7 pagesBlockchain ppt3not youNo ratings yet
- Binance Smart Chain: A Parallel Chain to Enable Smart ContractsDocument15 pagesBinance Smart Chain: A Parallel Chain to Enable Smart ContractsArijayaNo ratings yet
- Journey to the Center of Linux Traffic Control: Shaping, QoSDocument25 pagesJourney to the Center of Linux Traffic Control: Shaping, QoSagusalsaNo ratings yet
- Storage and Hyper-V Part 3 ConnectivityDocument7 pagesStorage and Hyper-V Part 3 ConnectivityAlemseged HabtamuNo ratings yet
- Configure VCS communication modules LLT and GAB on new clustersDocument20 pagesConfigure VCS communication modules LLT and GAB on new clustersSalman SaluNo ratings yet
- Traffic Control HOWTODocument25 pagesTraffic Control HOWTODoug HodsonNo ratings yet
- Understanding Reef Architecture - From Concept To Code and Beyond!Document17 pagesUnderstanding Reef Architecture - From Concept To Code and Beyond!Jinpragya JainNo ratings yet
- Mapprotocol Whitepaper enDocument32 pagesMapprotocol Whitepaper enAhmad SabriNo ratings yet
- How To Implement OSPF: PC Network AdvisorDocument5 pagesHow To Implement OSPF: PC Network AdvisorKabir HindustaniNo ratings yet
- Document 2Document8 pagesDocument 2Gassara IslemNo ratings yet
- AHB SlaveDocument18 pagesAHB SlaveRam VutaNo ratings yet
- A Guide To The Kafka ProtocolDocument12 pagesA Guide To The Kafka ProtocolEzequiel Escudero FrankNo ratings yet
- A SOAP stack for the Qt frameworkDocument86 pagesA SOAP stack for the Qt frameworkAntoniel BordinNo ratings yet
- Lesson 2Document20 pagesLesson 2juantuc98No ratings yet
- PowerHA 7 1 and Multicast v1Document6 pagesPowerHA 7 1 and Multicast v1Avinash HiwaraleNo ratings yet
- Comparing Traffic Policing and Traffic Shaping For Bandwidth LimitingDocument7 pagesComparing Traffic Policing and Traffic Shaping For Bandwidth LimitingCharles DondaNo ratings yet
- Explain The Value in A Reference Architecture For The Iot?Document19 pagesExplain The Value in A Reference Architecture For The Iot?MANTHAN GHOSHNo ratings yet
- Free Pascal Remote Procedure CallDocument9 pagesFree Pascal Remote Procedure CallJose AntonioNo ratings yet
- Top Answers To Couchbase Interview QuestionsDocument3 pagesTop Answers To Couchbase Interview QuestionsPappu KhanNo ratings yet
- Scalable Linux Clusters With LVS: Considerations and Implementation, Part IIDocument9 pagesScalable Linux Clusters With LVS: Considerations and Implementation, Part IItannvncsNo ratings yet
- Sample Examination: CS 403/534 - Distributed Systems Spring 2003Document3 pagesSample Examination: CS 403/534 - Distributed Systems Spring 2003emanuelyul jimenezNo ratings yet
- Blockchain Benchmark PaperDocument13 pagesBlockchain Benchmark Paperel majdoubi DrissNo ratings yet
- Ouroboros-BFT: A Simple Byzantine Fault Tolerant Consensus ProtocolDocument21 pagesOuroboros-BFT: A Simple Byzantine Fault Tolerant Consensus Protocoljosh kilaNo ratings yet
- Rsocket: Version 5.2.5.releaseDocument20 pagesRsocket: Version 5.2.5.releaseweihnachtlicheNo ratings yet
- Roxe Chain: A Hybrid Blockchain for Global PaymentsDocument18 pagesRoxe Chain: A Hybrid Blockchain for Global PaymentsSun PearNo ratings yet
- Ccie Ei Lab Exam: Module 1Document54 pagesCcie Ei Lab Exam: Module 1Red FlagNo ratings yet
- L1 IV Questions Vmax ArchitectureDocument6 pagesL1 IV Questions Vmax Architecturemail2luckNo ratings yet
- Unit - Ii: Communication and InvocationDocument16 pagesUnit - Ii: Communication and InvocationmdayyubNo ratings yet
- Zoning in Brocade FC SAN Switch For BeginnersDocument36 pagesZoning in Brocade FC SAN Switch For Beginnersiftikhar ahmedNo ratings yet
- Kubernates Cluster On Centos 8Document28 pagesKubernates Cluster On Centos 8chandrashekar_ganesanNo ratings yet
- Student Guide FC 120 FC Basics LDocument66 pagesStudent Guide FC 120 FC Basics LVishal MulikNo ratings yet
- QRFC and TRFCDocument19 pagesQRFC and TRFCmayakuntlaNo ratings yet
- 10 Vise Konekcija Ka InternetuDocument8 pages10 Vise Konekcija Ka InternetuNikolaIvanaTerzicNo ratings yet
- DART Fast and Flexible NoC Simulation Using FPGAsDocument4 pagesDART Fast and Flexible NoC Simulation Using FPGAssalimovic23No ratings yet
- Linux Kong ResDocument10 pagesLinux Kong RespashaapiNo ratings yet
- Alfred Advanced DTBDocument5 pagesAlfred Advanced DTBMr TuchelNo ratings yet
- Frame Relay TechnologyDocument5 pagesFrame Relay TechnologyStephen Palia KadzengaNo ratings yet
- Tricks L3 SwitchDocument4 pagesTricks L3 SwitchMotojunkie TLNo ratings yet
- Reliable Design With Multiple Clock Domains: Ed Czeck, Ravi Nanavati and Joe Stoy Bluespec Inc. Waltham MA 02451, USADocument10 pagesReliable Design With Multiple Clock Domains: Ed Czeck, Ravi Nanavati and Joe Stoy Bluespec Inc. Waltham MA 02451, USAvpsampathNo ratings yet
- Oracle Streams: A High Performance Implementation For Near Real Time Asynchronous ReplicationDocument12 pagesOracle Streams: A High Performance Implementation For Near Real Time Asynchronous Replicationnimar_aroraNo ratings yet
- Ieee Wsi95Document10 pagesIeee Wsi95Møśtãfã MâhmøudNo ratings yet
- Communication and InvocationDocument14 pagesCommunication and InvocationARVINDNo ratings yet
- Concurrent, Real-Time and Distributed Programming in Java: Threads, RTSJ and RMIFrom EverandConcurrent, Real-Time and Distributed Programming in Java: Threads, RTSJ and RMINo ratings yet
- Miller Ottawa2015 KeynoteDocument15 pagesMiller Ottawa2015 Keynotehotsync101No ratings yet
- Hunters Dream enDocument21 pagesHunters Dream enPooya MahmodiNo ratings yet
- IPC Class Notes: Message Passing and Shared MemoryDocument24 pagesIPC Class Notes: Message Passing and Shared MemorySachin VaijapurNo ratings yet
- Combined To Many Logics: Iii. ImplementationDocument4 pagesCombined To Many Logics: Iii. ImplementationNandkishore PatilNo ratings yet
- Lab 5 Setting WAN Bandwidth With Token Bucket Filter TBFDocument18 pagesLab 5 Setting WAN Bandwidth With Token Bucket Filter TBFCamilo GomezNo ratings yet
- M04 - Initial Fabric Configuration V2.5Document47 pagesM04 - Initial Fabric Configuration V2.5Duong NguyenNo ratings yet
- Untitled 2Document13 pagesUntitled 2sheraz salimNo ratings yet
- Swarm V Fleet V Kubernetes V MesosDocument7 pagesSwarm V Fleet V Kubernetes V MesosudNo ratings yet
- HAProxy in KubernetesDocument15 pagesHAProxy in KubernetesShirazNo ratings yet
- FAS Architecture GuideDocument33 pagesFAS Architecture GuideShareFile ProNo ratings yet
- COBOL Xped Users GuideDocument198 pagesCOBOL Xped Users Guideatiwari50% (1)
- Secunia CSI Best Practice GuideDocument62 pagesSecunia CSI Best Practice GuidemahadvikaNo ratings yet
- BP CustomerSupplier Enhancement Cookbook CustomerEdition 110 FinalDocument24 pagesBP CustomerSupplier Enhancement Cookbook CustomerEdition 110 FinalGagandeep WaliaNo ratings yet
- BIZAGi Modeler User GuideDocument875 pagesBIZAGi Modeler User GuideAbdenbi SaadiNo ratings yet
- Data Protection For Oracle Installation and User's Guide For UNIX and LinuxDocument82 pagesData Protection For Oracle Installation and User's Guide For UNIX and LinuxAyhan AyNo ratings yet
- PAN OS 6.0 Admin Guide PDFDocument348 pagesPAN OS 6.0 Admin Guide PDFalexanderNo ratings yet
- Test - DML - SELECT Statement - DE Courseware - ElearnDocument7 pagesTest - DML - SELECT Statement - DE Courseware - ElearnmirapakayeNo ratings yet
- Elements of Programming InterviewsDocument1 pageElements of Programming InterviewsAnand Prakash0% (1)
- NZSQL CommandsDocument27 pagesNZSQL Commandschandu5757No ratings yet
- FSNotes5, Better Than ObsidianDocument9 pagesFSNotes5, Better Than ObsidianDaniel Q.No ratings yet
- Handout6 Address Bookcode LumsDocument13 pagesHandout6 Address Bookcode LumsJameel MemonNo ratings yet
- QuesDocument12 pagesQuesCharlie ChampNo ratings yet
- SybaseIQ Vs SybaseASEDocument48 pagesSybaseIQ Vs SybaseASEqevedouNo ratings yet
- Archiving and Purging: You Know you need toDocument18 pagesArchiving and Purging: You Know you need tomazhar_83No ratings yet
- Huawei Firewall USG5300 Configuring System ParametersDocument4 pagesHuawei Firewall USG5300 Configuring System ParametersElizabeth RichNo ratings yet
- Mean StackDocument33 pagesMean StackyaswanthNo ratings yet
- Online Payments Three Party Interface API: PaystationDocument8 pagesOnline Payments Three Party Interface API: Paystationsivasankar_rajNo ratings yet
- Linux & Devops.: Kubernetes Kubectl Commands CheatsheetDocument8 pagesLinux & Devops.: Kubernetes Kubectl Commands CheatsheetRpl MarseilleNo ratings yet
- The Online Student Registration System Is An Web Based Portal Developed in ASPDocument4 pagesThe Online Student Registration System Is An Web Based Portal Developed in ASPnidhi7770% (1)
- Abhinav PaigwarDocument2 pagesAbhinav PaigwarDivyyaPandeyNo ratings yet
- Pharos Install Packages and Mobile PrintingDocument11 pagesPharos Install Packages and Mobile PrintingKevin Severud100% (3)
- OID Admin GuideDocument788 pagesOID Admin Guidesunandkumar549No ratings yet
- IDBS BiTs Set2Document4 pagesIDBS BiTs Set2Kumara Swamy BNo ratings yet
- Treinamento KACE SMADocument183 pagesTreinamento KACE SMAValériaNo ratings yet
- SCEIS Data Cleansing GuidelinesDocument8 pagesSCEIS Data Cleansing GuidelinesArjun GhattamneniNo ratings yet
- Minecraft Behavior and Resource PacksDocument5 pagesMinecraft Behavior and Resource Packsmaria carmenza moreno mirañaNo ratings yet
- Dhis2 End User Manual V 2.30Document109 pagesDhis2 End User Manual V 2.30wolex 7No ratings yet
- Call FunctionDocument14 pagesCall Functionkumarm1981No ratings yet
- OS Support for Building Distributed Applications: Java ThreadsDocument49 pagesOS Support for Building Distributed Applications: Java ThreadsDiego MedinaNo ratings yet
- DVM Data Reduction Potential - Cloud Solution - IntroductionDocument22 pagesDVM Data Reduction Potential - Cloud Solution - IntroductionAhlam HanaNo ratings yet