You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (587)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (894)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- 2010 - Caliber JEEP BOITE T355Document484 pages2010 - Caliber JEEP BOITE T355thierry.fifieldoutlook.comNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- 4-7 The Law of Sines and The Law of Cosines PDFDocument40 pages4-7 The Law of Sines and The Law of Cosines PDFApple Vidal100% (1)
- Quiz Chapter 1 Business Combinations Part 1Document6 pagesQuiz Chapter 1 Business Combinations Part 1Kaye L. Dela CruzNo ratings yet
- Key Differences Between Natural Sciences and Social SciencesDocument6 pagesKey Differences Between Natural Sciences and Social SciencesAshenPerera60% (5)
- Operational Readiness Guide - 2017Document36 pagesOperational Readiness Guide - 2017albertocm18100% (2)
- Architecture After Modernism - Diane GhirardoDocument10 pagesArchitecture After Modernism - Diane GhirardoCebo DharuNo ratings yet
- 42 SilvaDocument13 pages42 SilvaAthar KharalNo ratings yet
- Dear Friends,: Sincerely, Regards, ICMAS 2022Document1 pageDear Friends,: Sincerely, Regards, ICMAS 2022Athar KharalNo ratings yet
- ICMAS22 - Dr. Athar Kharal-BZUDocument1 pageICMAS22 - Dr. Athar Kharal-BZUAthar KharalNo ratings yet
- ICMAS22 - Information About Conference - Call For PapersDocument4 pagesICMAS22 - Information About Conference - Call For PapersAthar KharalNo ratings yet
- Aha09 - On Fuzzy Soft SetsDocument9 pagesAha09 - On Fuzzy Soft SetsAthar KharalNo ratings yet
- Aha09 - On Fuzzy Soft SetsDocument9 pagesAha09 - On Fuzzy Soft SetsAthar KharalNo ratings yet
- Kharal09 - Mappings On Fuzzy Soft ClassesDocument6 pagesKharal09 - Mappings On Fuzzy Soft ClassesAthar KharalNo ratings yet
- Kharal09 - Mappings On Fuzzy Soft ClassesDocument6 pagesKharal09 - Mappings On Fuzzy Soft ClassesAthar KharalNo ratings yet
- Laplace TransformsDocument79 pagesLaplace TransformsAthar KharalNo ratings yet
- Fuzzy Alpha Continuous Mappings 005Document10 pagesFuzzy Alpha Continuous Mappings 005Athar KharalNo ratings yet
- FND Global and FND Profile PDFDocument4 pagesFND Global and FND Profile PDFSaquib.MahmoodNo ratings yet
- Gec-Art Art Appreciation: Course Code: Course Title: Course DescriptionsDocument14 pagesGec-Art Art Appreciation: Course Code: Course Title: Course Descriptionspoleene de leonNo ratings yet
- Annual Reading Plan - Designed by Pavan BhattadDocument12 pagesAnnual Reading Plan - Designed by Pavan BhattadFarhan PatelNo ratings yet
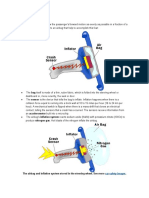
- Airbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreDocument5 pagesAirbag Inflation: The Airbag and Inflation System Stored in The Steering Wheel. See MoreShivankur HingeNo ratings yet
- Cellular Tower: Bayombong, Nueva VizcayaDocument17 pagesCellular Tower: Bayombong, Nueva VizcayaMonster PockyNo ratings yet
- Vsphere Storage PDFDocument367 pagesVsphere Storage PDFNgo Van TruongNo ratings yet
- 2024 Yoga Vidya Training FormDocument8 pages2024 Yoga Vidya Training FormJohnNo ratings yet
- Region VIII - Eastern Visayas Quickstat On: Philippine Statistics AuthorityDocument3 pagesRegion VIII - Eastern Visayas Quickstat On: Philippine Statistics AuthorityBegie LucenecioNo ratings yet
- Chapter Three 3.0 Research MethodologyDocument5 pagesChapter Three 3.0 Research MethodologyBoyi EnebinelsonNo ratings yet
- Audiology DissertationDocument4 pagesAudiology DissertationPaperWritingHelpOnlineUK100% (1)
- Trailers Parts - Rocket Trailers - Suspension & FastenersDocument24 pagesTrailers Parts - Rocket Trailers - Suspension & FastenersRocket TrailersNo ratings yet
- Sample Id: Sample Id: 6284347 Icmr Specimen Referral Form Icmr Specimen Referral Form For For Covid-19 (Sars-Cov2) Covid-19 (Sars-Cov2)Document2 pagesSample Id: Sample Id: 6284347 Icmr Specimen Referral Form Icmr Specimen Referral Form For For Covid-19 (Sars-Cov2) Covid-19 (Sars-Cov2)Praveen KumarNo ratings yet
- Topicwise Analysis For Last 10 YearsDocument20 pagesTopicwise Analysis For Last 10 YearsVAMCNo ratings yet
- Kafka Netdb 06 2011 PDFDocument15 pagesKafka Netdb 06 2011 PDFaarishgNo ratings yet
- BRTU-2000 Remote Terminal Unit for High Voltage NetworksDocument2 pagesBRTU-2000 Remote Terminal Unit for High Voltage NetworksLaurentiuNo ratings yet
- IEEE802.11b/g High Power Wireless AP/Bridge Quick Start GuideDocument59 pagesIEEE802.11b/g High Power Wireless AP/Bridge Quick Start GuideonehotminuteNo ratings yet
- Marine Ecotourism BenefitsDocument10 pagesMarine Ecotourism Benefitsimanuel wabangNo ratings yet
- 2746 PakMaster 75XL Plus (O)Document48 pages2746 PakMaster 75XL Plus (O)Samuel ManducaNo ratings yet
- To Quantitative Analysis: To Accompany by Render, Stair, Hanna and Hale Power Point Slides Created by Jeff HeylDocument94 pagesTo Quantitative Analysis: To Accompany by Render, Stair, Hanna and Hale Power Point Slides Created by Jeff HeylNino NatradzeNo ratings yet
- Ð.Ð.Á Valvoline Áóìá Áíáâáóç Ñéôóùíáó 9.6.2019: Omaäa ADocument6 pagesÐ.Ð.Á Valvoline Áóìá Áíáâáóç Ñéôóùíáó 9.6.2019: Omaäa AVagelis MoutoupasNo ratings yet
- Bajaj Internship ReportDocument69 pagesBajaj Internship ReportCoordinator ABS100% (2)
- CopyofCopyofMaldeepSingh Jawanda ResumeDocument2 pagesCopyofCopyofMaldeepSingh Jawanda Resumebob nioNo ratings yet
- University of Technology: Computer Engineering DepartmentDocument29 pagesUniversity of Technology: Computer Engineering DepartmentwisamNo ratings yet
- NAFTA CertificateDocument2 pagesNAFTA Certificateapi-522706100% (4)