You might also like
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5806)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Complete Order To CashDocument14 pagesComplete Order To CashAvinandan SahaNo ratings yet
- UNDERSTANDING ARDUINO A Beginners Guide With Realtime Insights and Tricks To Learn Arduino ProgrammingDocument39 pagesUNDERSTANDING ARDUINO A Beginners Guide With Realtime Insights and Tricks To Learn Arduino ProgrammingLuis Baldassari100% (1)
- Log Shipping Best PracticesDocument22 pagesLog Shipping Best PracticesnikjadhavNo ratings yet
- OPC & NetworkingDocument60 pagesOPC & NetworkingAnil Nair100% (2)
- (SA22-7683-12) (V1R10) zOS - Security Server RACF Security Administrator's GuideDocument848 pages(SA22-7683-12) (V1R10) zOS - Security Server RACF Security Administrator's GuideJosé Antonio Osorio RodríguezNo ratings yet
- Oracle R12.1 ASCP User GuideDocument1,522 pagesOracle R12.1 ASCP User Guidesumeetgoenka0% (1)
- EKSDocument98 pagesEKSspNo ratings yet
- Manual BECKHOFF EtherCAT Bridge Terminal EL6695-1001 2016-02-17 enDocument112 pagesManual BECKHOFF EtherCAT Bridge Terminal EL6695-1001 2016-02-17 enGor PSNo ratings yet
- Configuration and Commissioning NEC iPASOLINK VR4 - EnglishDocument29 pagesConfiguration and Commissioning NEC iPASOLINK VR4 - Englishcamera 01100% (4)
- Bab 6Document17 pagesBab 6nindy apriliaNo ratings yet
- Uts PKSPDocument3 pagesUts PKSPnindy apriliaNo ratings yet
- Bab 5Document16 pagesBab 5nindy apriliaNo ratings yet
- Bab 3 PDFDocument8 pagesBab 3 PDFnindy apriliaNo ratings yet
- Bab 1 PDFDocument6 pagesBab 1 PDFnindy apriliaNo ratings yet
- 1b Entitas DagangDocument10 pages1b Entitas Dagangnindy apriliaNo ratings yet
- Tugas Mandiri PDFDocument2 pagesTugas Mandiri PDFnindy apriliaNo ratings yet
- Tugas Akl 1Document2 pagesTugas Akl 1nindy apriliaNo ratings yet
- Resume 5 PDFDocument6 pagesResume 5 PDFnindy apriliaNo ratings yet
- 04 10 2020 21.40.10 PDFDocument18 pages04 10 2020 21.40.10 PDFnindy apriliaNo ratings yet
- Do Gender, Educational Level, Religiosity, and Work Experience Affect The Ethical Decision-Making of U.S. Accountants?Document17 pagesDo Gender, Educational Level, Religiosity, and Work Experience Affect The Ethical Decision-Making of U.S. Accountants?nindy apriliaNo ratings yet
- DX DiagDocument29 pagesDX DiagSantosh UmachagiNo ratings yet
- Updating TPS 320ic - 600i UnitDocument21 pagesUpdating TPS 320ic - 600i UnitJuan RodriguezNo ratings yet
- Wei TungDocument31 pagesWei TungKareem AmirudinNo ratings yet
- Backtracking - Set 3 (N Queen Problem) - GeeksforGeeksDocument16 pagesBacktracking - Set 3 (N Queen Problem) - GeeksforGeeksShubham MinhasNo ratings yet
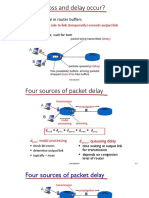
- How Do Loss and Delay Occur?: Packets Queue in Router BuffersDocument5 pagesHow Do Loss and Delay Occur?: Packets Queue in Router BuffersAnil AhmedNo ratings yet
- MultiVue Quick Guide (EPIQ Evolution 5.0 & Affiniti Continuum 3.0) NewpdfDocument5 pagesMultiVue Quick Guide (EPIQ Evolution 5.0 & Affiniti Continuum 3.0) NewpdfYT wNo ratings yet
- A Walk Through The Park On A Particularly Dim Saturn's DayDocument177 pagesA Walk Through The Park On A Particularly Dim Saturn's Daypeter panNo ratings yet
- AAVSO DSLR Photometry Software Tutorials V1-0Document58 pagesAAVSO DSLR Photometry Software Tutorials V1-0Нини СтанимироваNo ratings yet
- Programbrief CISO Aug 1-4, 2018Document20 pagesProgrambrief CISO Aug 1-4, 2018Manish GargNo ratings yet
- C-User Questionnaire V2.1Document1 pageC-User Questionnaire V2.1Lokesh ModemzNo ratings yet
- Section F PPT - Us CmaDocument165 pagesSection F PPT - Us CmaAayan QamarNo ratings yet
- Software Personnel Management: 1.problem StatementDocument2 pagesSoftware Personnel Management: 1.problem StatementaNo ratings yet
- A) Why A Hexagonal Shape Is Preferred Over Triangular or Square Cell Shapes To Represent The Cellular Architecture? JustifyDocument12 pagesA) Why A Hexagonal Shape Is Preferred Over Triangular or Square Cell Shapes To Represent The Cellular Architecture? Justifysiri20241a04a6No ratings yet
- Unit-6 - Data Visualization and Graph AnalyticsDocument27 pagesUnit-6 - Data Visualization and Graph AnalyticsNishil ShahNo ratings yet
- Multimedia Chapter 1Document16 pagesMultimedia Chapter 1Mohammad NomanNo ratings yet
- Sony Se2 Chassis Kdl26p3000 LCD TV SMDocument144 pagesSony Se2 Chassis Kdl26p3000 LCD TV SMIvo StefanovNo ratings yet
- Signal Trace Interpreter: in This DocumentDocument43 pagesSignal Trace Interpreter: in This DocumentbstrellowNo ratings yet
- CCNA Sec Chap1 Study Guide AnsDocument8 pagesCCNA Sec Chap1 Study Guide Anspulsar2004No ratings yet
- Managing Local Users and GroupsDocument6 pagesManaging Local Users and GroupspmmanickNo ratings yet
- Drone Bootcamp Brochure NCE ChandiDocument3 pagesDrone Bootcamp Brochure NCE Chandih1314397No ratings yet
- Assignment 3Document2 pagesAssignment 3Gaurav JainNo ratings yet