You might also like
- DATA MINING and MACHINE LEARNING. CLASSIFICATION PREDICTIVE TECHNIQUES: SUPPORT VECTOR MACHINE, LOGISTIC REGRESSION, DISCRIMINANT ANALYSIS and DECISION TREES: Examples with MATLABFrom EverandDATA MINING and MACHINE LEARNING. CLASSIFICATION PREDICTIVE TECHNIQUES: SUPPORT VECTOR MACHINE, LOGISTIC REGRESSION, DISCRIMINANT ANALYSIS and DECISION TREES: Examples with MATLABNo ratings yet
- ML NotesDocument125 pagesML NotesAbhijit Das100% (2)
- Coincent - Data Science With Python AssignmentDocument23 pagesCoincent - Data Science With Python AssignmentSai Nikhil Nellore100% (2)
- Machine Learning: Lecture 13: Model Validation Techniques, Overfitting, UnderfittingDocument26 pagesMachine Learning: Lecture 13: Model Validation Techniques, Overfitting, UnderfittingMd Fazle Rabby100% (2)
- Machine Learning - Part 1Document80 pagesMachine Learning - Part 1cjon100% (1)
- Machine Learning Project ReportDocument4 pagesMachine Learning Project ReportAshish100% (1)
- Machine Learning NotesDocument15 pagesMachine Learning NotesxyzabsNo ratings yet
- Clustering (Unit 3)Document71 pagesClustering (Unit 3)vedang maheshwari100% (1)
- Machine Learning ModelsDocument56 pagesMachine Learning ModelsSHIKHA SHARMA100% (1)
- Machine Learning With PythonDocument41 pagesMachine Learning With Pythonsubu100% (1)
- ClassificationDocument105 pagesClassificationkarvamin100% (1)
- Machine Learning Mini-Project ReportDocument26 pagesMachine Learning Mini-Project ReportSaket SinghNo ratings yet
- Lecture 14 AutoencodersDocument39 pagesLecture 14 AutoencodersDevyansh Gupta100% (1)
- Machine Learning GuideDocument31 pagesMachine Learning GuideSana AkramNo ratings yet
- SRM Valliammai Engineering College (An Autonomous Institution)Document9 pagesSRM Valliammai Engineering College (An Autonomous Institution)sureshNo ratings yet
- UNSUPERVISED LEARNING AND DIMENSIONALITY REDUCTIONDocument58 pagesUNSUPERVISED LEARNING AND DIMENSIONALITY REDUCTIONSanaullahSunnyNo ratings yet
- Clustering K-MeansDocument28 pagesClustering K-MeansFaysal AhammedNo ratings yet
- Combined MLDocument705 pagesCombined MLAbhishekNo ratings yet
- Lecture 07 KNN 14112022 034756pmDocument24 pagesLecture 07 KNN 14112022 034756pmMisbah100% (1)
- Machine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionDocument22 pagesMachine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionKANTESH kantesh100% (1)
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- Unit 3: Classification & Regression: Question Bank and Its SolutionDocument180 pagesUnit 3: Classification & Regression: Question Bank and Its SolutionTejas NarsaleNo ratings yet
- Machine Learning Programming ExerciseDocument118 pagesMachine Learning Programming Exercisexgdsmxy100% (2)
- cp4252 Machine LearningDocument49 pagescp4252 Machine LearningSuganya C100% (1)
- Unit 4 Basics of Feature EngineeringDocument33 pagesUnit 4 Basics of Feature EngineeringYash DesaiNo ratings yet
- Jntuk R20 ML Unit-IiiDocument21 pagesJntuk R20 ML Unit-IiiMahesh100% (1)
- Introduction To Keras!: Vincent Lepetit!Document33 pagesIntroduction To Keras!: Vincent Lepetit!Serigne Modou NDIAYENo ratings yet
- Ensemble ClassifiersDocument37 pagesEnsemble Classifierstwinkz7100% (1)
- Machine Learning AssignmentDocument55 pagesMachine Learning AssignmentAkashNo ratings yet
- UNIT-1 Foundations of Deep LearningDocument51 pagesUNIT-1 Foundations of Deep Learningbhavana100% (1)
- Unit - 5.1 - Introduction To Machine LearningDocument38 pagesUnit - 5.1 - Introduction To Machine LearningHarsh officialNo ratings yet
- Modelling and EvaluationDocument70 pagesModelling and EvaluationANIMESH KUMARNo ratings yet
- A Basic Introduction To Machine Learning and Data Analytics: Yolanda Gil University of Southern CaliforniaDocument118 pagesA Basic Introduction To Machine Learning and Data Analytics: Yolanda Gil University of Southern CaliforniaAbokhaled AL-ashmawiNo ratings yet
- Machine Learning Projects PDFDocument5 pagesMachine Learning Projects PDFEnglish SongsNo ratings yet
- ML Lecture 11 (K Nearest Neighbors)Document13 pagesML Lecture 11 (K Nearest Neighbors)Md Fazle RabbyNo ratings yet
- CS583 Chapter 4 Supervised LearningDocument166 pagesCS583 Chapter 4 Supervised LearningKunal DeoreNo ratings yet
- 21 Machine Learning Using Scikit Learn Ipynb Colaboratory PDFDocument23 pages21 Machine Learning Using Scikit Learn Ipynb Colaboratory PDFJagadeesh Kumar100% (1)
- Introduction to Machine Learning in 40 CharactersDocument59 pagesIntroduction to Machine Learning in 40 CharactersJAYACHANDRAN J 20PHD0157No ratings yet
- UE20CS302 Unit4 SlidesDocument312 pagesUE20CS302 Unit4 SlidesDRUVA HegdeNo ratings yet
- Missing Value TreatmentDocument22 pagesMissing Value TreatmentrphmiNo ratings yet
- Machine Learning Techniques and ApplicationsDocument113 pagesMachine Learning Techniques and ApplicationsRamakrishnaRao SoogooriNo ratings yet
- The Ultimate Collection of Machine Learning ResourcesDocument5 pagesThe Ultimate Collection of Machine Learning ResourcesSunilkumar ReddyNo ratings yet
- Soft Computing (SC) Topper SolutionDocument35 pagesSoft Computing (SC) Topper Solutionakash100% (2)
- Machine LearningDocument58 pagesMachine LearningAniket Kumar100% (2)
- Deep Learning QuestionsDocument51 pagesDeep Learning QuestionsAditi Jaiswal100% (1)
- Machine Learning Revision NotesDocument6 pagesMachine Learning Revision NotesGaurav TendolkarNo ratings yet
- Essential Math Topics for Machine LearningDocument3 pagesEssential Math Topics for Machine Learninghoney13No ratings yet
- 02 Machine Learning OverviewDocument103 pages02 Machine Learning OverviewDhouha BenzinaNo ratings yet
- L10a - Machine Learning Basic ConceptsDocument80 pagesL10a - Machine Learning Basic ConceptsMeilysaNo ratings yet
- Face Recognition Attendance SystemDocument18 pagesFace Recognition Attendance SystemChinnu D SNo ratings yet
- Classification TechniquesDocument99 pagesClassification TechniquesHemanth Kumar GNo ratings yet
- BackpropagationDocument7 pagesBackpropagationShruti JamsandekarNo ratings yet
- Datascience RoadmapDocument4 pagesDatascience RoadmapSaad Ur Rehman Aftab100% (2)
- Unit 1 - Machine Learning - WWW - Rgpvnotes.inDocument23 pagesUnit 1 - Machine Learning - WWW - Rgpvnotes.inxaiooNo ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- Support Vector Machine: Name: Sagar KumarDocument13 pagesSupport Vector Machine: Name: Sagar KumarShinigamiNo ratings yet
- 49 Machine LearningDocument300 pages49 Machine LearningBalaji VenkateswaranNo ratings yet
- Deep Learning NotesDocument44 pagesDeep Learning NotesAJAY SINGH NEGI100% (1)
- Machine Learning BitsDocument28 pagesMachine Learning Bitsvyshnavi100% (2)
- Week10 KNN PracticalDocument4 pagesWeek10 KNN Practicalseerungen jordiNo ratings yet
- Range Equation: Dr.V.R.S.MANI Associate Professor (SG/ECE) National Engineering CollegeDocument12 pagesRange Equation: Dr.V.R.S.MANI Associate Professor (SG/ECE) National Engineering CollegeMani VrsNo ratings yet
- 1 s2.0 S2772801322000185 Main 2Document17 pages1 s2.0 S2772801322000185 Main 2Mani VrsNo ratings yet
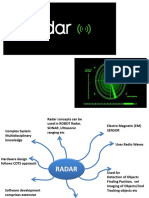
- Radar Basics ExplainedDocument51 pagesRadar Basics ExplainedMani VrsNo ratings yet
- Snoa 621 CDocument26 pagesSnoa 621 CLalit GoelNo ratings yet
- Radar PerformanceDocument8 pagesRadar PerformanceMani VrsNo ratings yet
- Range Resolution and Unambiguous Range: Dr.V.R.S. MANI Associate Professor (SG) / ECE NECDocument15 pagesRange Resolution and Unambiguous Range: Dr.V.R.S. MANI Associate Professor (SG) / ECE NECMani VrsNo ratings yet
- Radar - Velocity MeasurementDocument29 pagesRadar - Velocity MeasurementMani VrsNo ratings yet
- Radar Cross Section of Target: Dr.V.R.S.Mani Associate Professor (SG) /ECE NECDocument33 pagesRadar Cross Section of Target: Dr.V.R.S.Mani Associate Professor (SG) /ECE NECMani VrsNo ratings yet
- Analysis Short Dipole Antenna PropertiesDocument19 pagesAnalysis Short Dipole Antenna PropertiesMani VrsNo ratings yet
- Introduction To Radar Lecture 1 MaterialDocument36 pagesIntroduction To Radar Lecture 1 Materialprasad nairNo ratings yet
- Tutorial ProblemsDocument11 pagesTutorial ProblemsMani VrsNo ratings yet
- Range Resolution and Unambiguous Range: Dr.V.R.S. MANI Associate Professor (SG) / ECE NECDocument15 pagesRange Resolution and Unambiguous Range: Dr.V.R.S. MANI Associate Professor (SG) / ECE NECMani VrsNo ratings yet
- Range Resolution and Unambiguous Range: Dr.V.R.S. MANI Associate Professor (SG) / ECE NECDocument15 pagesRange Resolution and Unambiguous Range: Dr.V.R.S. MANI Associate Professor (SG) / ECE NECMani VrsNo ratings yet
- Range Equation: Dr.V.R.S.MANI Associate Professor (SG/ECE) National Engineering CollegeDocument15 pagesRange Equation: Dr.V.R.S.MANI Associate Professor (SG/ECE) National Engineering CollegeMani VrsNo ratings yet
- Lecture 2Document35 pagesLecture 2Raymond Quah Soon Kiat100% (1)
- Radar Cross Section of Target: Dr.V.R.S.Mani Associate Professor (SG) /ECE NECDocument33 pagesRadar Cross Section of Target: Dr.V.R.S.Mani Associate Professor (SG) /ECE NECMani VrsNo ratings yet
- Radar Cross Section of Target: Dr.V.R.S.Mani Associate Professor (SG) /ECE NECDocument33 pagesRadar Cross Section of Target: Dr.V.R.S.Mani Associate Professor (SG) /ECE NECMani VrsNo ratings yet
- Articles: BackgroundDocument11 pagesArticles: BackgroundMani VrsNo ratings yet
- Articles: BackgroundDocument11 pagesArticles: BackgroundMani VrsNo ratings yet
- PublishedpaperPh.d IJERA MARCHDocument9 pagesPublishedpaperPh.d IJERA MARCHPaul Ionescu IINo ratings yet
- Gradients without BackpropagationDocument10 pagesGradients without BackpropagationMark FreegattiNo ratings yet
- Handwritten Digits Recognition Using Neural NetworksDocument13 pagesHandwritten Digits Recognition Using Neural NetworksVandhana RathodNo ratings yet
- Application of Deep Learning in Food: A Review: Chuzh@zju - Edu.cn Zjqiu@zju - Edu.cnDocument19 pagesApplication of Deep Learning in Food: A Review: Chuzh@zju - Edu.cn Zjqiu@zju - Edu.cnpreethiyaNo ratings yet
- Artificial Neural Network OverviewDocument15 pagesArtificial Neural Network OverviewRashid AhmedNo ratings yet
- Group Assignment AIDocument7 pagesGroup Assignment AIKirthi VasanNo ratings yet
- A Wavelet - Based Fault LocalizationDocument5 pagesA Wavelet - Based Fault LocalizationOmar Chayña VelásquezNo ratings yet
- Long-Term Peak Load Forecasting Using LM-Feedforward Neural Network For Java-Madura-Bali Interconnection, IndonesiaDocument6 pagesLong-Term Peak Load Forecasting Using LM-Feedforward Neural Network For Java-Madura-Bali Interconnection, IndonesiaMarioNo ratings yet
- Implementing Machine Learning in Radiology Practice and ResearchDocument15 pagesImplementing Machine Learning in Radiology Practice and ResearchfreteerNo ratings yet
- Artificial Neural Networks Generalize Ballistic Trajectory LearningDocument6 pagesArtificial Neural Networks Generalize Ballistic Trajectory LearningTaylor MontedoNo ratings yet
- Fuzzy Logic and Neural Networks MCQDocument40 pagesFuzzy Logic and Neural Networks MCQNikhil TiwariNo ratings yet
- Morales-Lopez2020 Article CataractDetectionAndClassificaDocument14 pagesMorales-Lopez2020 Article CataractDetectionAndClassificaOscar Julian Perdomo CharryNo ratings yet
- L. Aydin Yegildirek, And: So RBF'S) - in This ToDocument12 pagesL. Aydin Yegildirek, And: So RBF'S) - in This TosalimNo ratings yet
- Ann in AbaqusDocument8 pagesAnn in AbaqusNikhil ChandanNo ratings yet
- Grad-CAM: Visual Explanations from Deep NetworksDocument23 pagesGrad-CAM: Visual Explanations from Deep NetworksAulia SabriNo ratings yet
- 1 s2.0 0017931095003320 MainDocument4 pages1 s2.0 0017931095003320 MainAbdur RashidNo ratings yet
- Computerised Paper Evaluation Using Neural NetworkDocument15 pagesComputerised Paper Evaluation Using Neural NetworkKishori SwathiNo ratings yet
- Capsule Neural Network and Its Implementation For Object Recognition in Resource-Limited DevicesDocument103 pagesCapsule Neural Network and Its Implementation For Object Recognition in Resource-Limited DevicesNguyen Van BinhNo ratings yet
- Project ReportDocument49 pagesProject ReportMohd VohraNo ratings yet
- A Quick Review of Machine Learning Algorithms: Susmita RayDocument5 pagesA Quick Review of Machine Learning Algorithms: Susmita RayMukesh KumarNo ratings yet
- Back Propagation Neural Networks: Substance Use & Misuse February 1998Document38 pagesBack Propagation Neural Networks: Substance Use & Misuse February 1998Blaise Chinemerem IhezieNo ratings yet
- Updated Paper ID-118Document5 pagesUpdated Paper ID-118jrlionel30No ratings yet
- A Computer Model For The Schillinger System of Musical Composition PDFDocument137 pagesA Computer Model For The Schillinger System of Musical Composition PDFMichael BonettNo ratings yet
- Patrick Henry Winston - Artificial Intelligence-Pearson (1992)Document774 pagesPatrick Henry Winston - Artificial Intelligence-Pearson (1992)Sebastian AHNo ratings yet
- PINNeikEikonal Solution Using Physics-Informed Neural NetworksDocument13 pagesPINNeikEikonal Solution Using Physics-Informed Neural Networksshib ganguliNo ratings yet
- Pattern Recognition: Assignment No:2Document13 pagesPattern Recognition: Assignment No:2Millo KayNo ratings yet
- Soft ComputingDocument92 pagesSoft ComputingEco Frnd Nikhil ChNo ratings yet
- Understanding Neural Networks. We Explore How Neural Networks Function - by Tony Yiu - Towards Data ScienceDocument18 pagesUnderstanding Neural Networks. We Explore How Neural Networks Function - by Tony Yiu - Towards Data ScienceDerrick TayNo ratings yet
- Detecting The Financial Statement Fraud The Analysis of The Differences Between Data Mining Techniques and Experts' JudgmentsDocument12 pagesDetecting The Financial Statement Fraud The Analysis of The Differences Between Data Mining Techniques and Experts' JudgmentsMohsin Ul Amin KhanNo ratings yet
- Soft Computing Unit 1 and 2 QuestionsDocument3 pagesSoft Computing Unit 1 and 2 QuestionsHarshali Y. Patil100% (3)