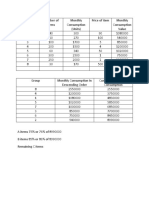
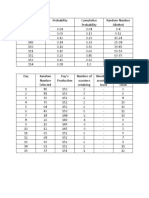
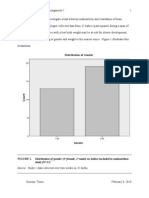
You might also like
- Practical Engineering, Process, and Reliability StatisticsFrom EverandPractical Engineering, Process, and Reliability StatisticsNo ratings yet
- Basic Statisticks 1 - Assignment - Vivek TDocument18 pagesBasic Statisticks 1 - Assignment - Vivek TSunil kumar Kurella100% (7)
- Business Stats Ken Black Case AnswersDocument54 pagesBusiness Stats Ken Black Case AnswersGaurav Sharma100% (1)
- Statistics - Practice 1 - F2020 PDFDocument6 pagesStatistics - Practice 1 - F2020 PDFHilmar Castro de GarciaNo ratings yet
- Par ReportDocument5 pagesPar ReportShyam Kishore TripathiNo ratings yet
- Basics of Statistics Part 1Document58 pagesBasics of Statistics Part 1Pulkit AggarwalNo ratings yet
- Basics of Statistics1Document63 pagesBasics of Statistics1PriyamGhoshNo ratings yet
- Lesson 5 - Quantitative Analysis and Interpretation of DataDocument78 pagesLesson 5 - Quantitative Analysis and Interpretation of Dataojs99784No ratings yet
- StatisticsDocument14 pagesStatisticsMaica Ann Joy SimbulanNo ratings yet
- Presentation of The Data Features: Tabular and GraphicDocument31 pagesPresentation of The Data Features: Tabular and GraphicTariq Bin AmirNo ratings yet
- Central Tendency and DispersionDocument61 pagesCentral Tendency and DispersionfauxNo ratings yet
- TEC301 StatisticsDocument22 pagesTEC301 StatisticsTinevimbo MugabeNo ratings yet
- Module 1: Descriptive and Inferential StatisticsDocument7 pagesModule 1: Descriptive and Inferential StatisticsWaqas KhanNo ratings yet
- Data ManagementDocument44 pagesData ManagementHi Shaira MontejoNo ratings yet
- 1 Intro To Stat & Data PresentationDocument21 pages1 Intro To Stat & Data PresentationKWANG QING XUANNo ratings yet
- Measures of Central Tendency: Mean, Mode, MedianDocument30 pagesMeasures of Central Tendency: Mean, Mode, Medianafnan nabiNo ratings yet
- Nature of Statistics Part 2Document48 pagesNature of Statistics Part 2ROYYETTE F. FERNANDEZNo ratings yet
- UALL 2044 Lecture 13Document34 pagesUALL 2044 Lecture 13PDooruNo ratings yet
- Introduction to Descriptive StatisticsDocument86 pagesIntroduction to Descriptive StatisticsEmmanuel EliyaNo ratings yet
- 2035 CH2 NotesDocument42 pages2035 CH2 Noteskejacob629No ratings yet
- Chapter Six (Statistics)Document91 pagesChapter Six (Statistics)pretoria agreement21No ratings yet
- Lecture 4 Data Analysis Summary Measures 1Document24 pagesLecture 4 Data Analysis Summary Measures 1Keaobaka TlagaeNo ratings yet
- Chapter 2 Classification and Presentation of DataDocument43 pagesChapter 2 Classification and Presentation of DataKNo ratings yet
- Stat422: Lecture 1 - Part 1Document64 pagesStat422: Lecture 1 - Part 1Azza KassemNo ratings yet
- Module 5. Organizing and Summarizing DataDocument18 pagesModule 5. Organizing and Summarizing DataHotaro OrekiNo ratings yet
- StatisticsDocument29 pagesStatisticsSakshiNo ratings yet
- Measures of Central Tendency: Mean, Mode, Median: Soumendra RoyDocument34 pagesMeasures of Central Tendency: Mean, Mode, Median: Soumendra Roybapparoy100% (1)
- Measures of Dispersion - Galos L. and Gabanan F.Document54 pagesMeasures of Dispersion - Galos L. and Gabanan F.Christian GebañaNo ratings yet
- Measures of Central Tendency: Mean, Mode, Median: ChandrappaDocument26 pagesMeasures of Central Tendency: Mean, Mode, Median: ChandrappaMd Mehedi HasanNo ratings yet
- Mathematical Statistics: Instructor: Dr. Deshi YeDocument42 pagesMathematical Statistics: Instructor: Dr. Deshi YeAhmed Kadem ArabNo ratings yet
- SPC Statistics: Histograms, Distributions & Hypothesis TestsDocument158 pagesSPC Statistics: Histograms, Distributions & Hypothesis Testsgeletaw mitawNo ratings yet
- Quantitative Data AnalysisDocument31 pagesQuantitative Data Analysisakoeljames8543No ratings yet
- Unit 2Document11 pagesUnit 2Ragha RamojuNo ratings yet
- Frequency Distribution Lecture 2 3Document11 pagesFrequency Distribution Lecture 2 3rafid RafuuNo ratings yet
- Displaying and Describing Quantitative DataDocument49 pagesDisplaying and Describing Quantitative DataJosh PotashNo ratings yet
- Collecting PresentingDocument18 pagesCollecting PresentingCHEONG SHIN YEENo ratings yet
- Measures of central tendency for grouped dataDocument22 pagesMeasures of central tendency for grouped dataSande Alota BocoNo ratings yet
- Descriptive Stats and EDA in RDocument36 pagesDescriptive Stats and EDA in REmmanuel Adjei OdameNo ratings yet
- Lecture 4 Measure of Central Tendency Ungrouped Freq DistDocument28 pagesLecture 4 Measure of Central Tendency Ungrouped Freq DistGeckoNo ratings yet
- Unit 4Document17 pagesUnit 4nehaprajapati882388No ratings yet
- Data Analytics TheoryDocument54 pagesData Analytics TheoryChandra MohanNo ratings yet
- Summarize Engineering Data with Descriptive StatisticsDocument74 pagesSummarize Engineering Data with Descriptive StatisticsEunnicePanaligan100% (1)
- Basic Statistical Descriptions of Data: Dr. Amiya Ranjan PandaDocument35 pagesBasic Statistical Descriptions of Data: Dr. Amiya Ranjan PandaAnu agarwalNo ratings yet
- Measures Central Tendency Mean Mode MedianDocument26 pagesMeasures Central Tendency Mean Mode MedianHetal Koringa patelNo ratings yet
- 2.central Tendency and DispersionDocument114 pages2.central Tendency and DispersionMohi SharmaNo ratings yet
- Mathematical AnalysisDocument46 pagesMathematical AnalysisGilbert Dwasi100% (1)
- Gtu 302 Biostatistics: Descriptive StatisticsDocument57 pagesGtu 302 Biostatistics: Descriptive StatisticsLimYiNo ratings yet
- 3 Descriptive Statistics PDFDocument58 pages3 Descriptive Statistics PDFCharlyne Mari FloresNo ratings yet
- Stats LectDocument77 pagesStats LectChristopherNo ratings yet
- Measure of Central TendancyDocument27 pagesMeasure of Central TendancySadia HakimNo ratings yet
- Standard Deviation Made EasyDocument8 pagesStandard Deviation Made EasyShe LagundinoNo ratings yet
- Statistics Lecture Course 2015-2016Document67 pagesStatistics Lecture Course 2015-2016hohoNo ratings yet
- Mean Median and Mode - 09012022 - Business StatisticsDocument93 pagesMean Median and Mode - 09012022 - Business StatisticsAkshil NagdaNo ratings yet
- Measures of Central Tendency and Dispersion ExplainedDocument51 pagesMeasures of Central Tendency and Dispersion ExplainedmakidaNo ratings yet
- Frequency Distribution: A Frequency Distribution Is Constructed For Three Main ReasonsDocument15 pagesFrequency Distribution: A Frequency Distribution Is Constructed For Three Main ReasonsBhawna JoshiNo ratings yet
- FSS 204 Lecture 2-1-1Document12 pagesFSS 204 Lecture 2-1-1Abioye DanielNo ratings yet
- MODULE 3 - Data ManagementDocument21 pagesMODULE 3 - Data ManagementCIELICA BURCANo ratings yet
- Chapter 5 - RMDocument22 pagesChapter 5 - RMhumaNo ratings yet
- Unit IiDocument66 pagesUnit Ii05Bala SaatvikNo ratings yet
- Frequency Distribution GraphsDocument26 pagesFrequency Distribution GraphsKenneth TanniNo ratings yet
- UntitledDocument43 pagesUntitledMuhammad AreebNo ratings yet
- Quantitative Data AnalysisDocument27 pagesQuantitative Data AnalysisHaneef Mohamed100% (1)
- Introduction To Statistics: Prof. Christos AgiakloglouDocument31 pagesIntroduction To Statistics: Prof. Christos AgiakloglouRosendo Antonio BarrientosNo ratings yet
- Strategic Management: Prof Bharat NadkarniDocument34 pagesStrategic Management: Prof Bharat NadkarniRajat ShettyNo ratings yet
- Exercise For Basic Stat 2Document16 pagesExercise For Basic Stat 2Rajat ShettyNo ratings yet
- Sasco CorporationDocument2 pagesSasco CorporationRajat ShettyNo ratings yet
- Bullwhip Effect in Supply Chains - Plenty of Practical Evidence and Solid Theoretical BackgroundDocument28 pagesBullwhip Effect in Supply Chains - Plenty of Practical Evidence and Solid Theoretical BackgroundRajat ShettyNo ratings yet
- Strategic Management: Business Strategies and Corporate StrategiesDocument22 pagesStrategic Management: Business Strategies and Corporate StrategiesRajat ShettyNo ratings yet
- Models in Strategic ManagementDocument110 pagesModels in Strategic ManagementRajat ShettyNo ratings yet
- Strategic Management: Environmental & Organisational AppraisalDocument42 pagesStrategic Management: Environmental & Organisational AppraisalRajat ShettyNo ratings yet
- Strategic Management EssentialsDocument40 pagesStrategic Management EssentialsRajat ShettyNo ratings yet
- Strategic MGMT Mintzberg McKinsey Blue Red OceanDocument26 pagesStrategic MGMT Mintzberg McKinsey Blue Red OceanRajat ShettyNo ratings yet
- ABC AnalysisDocument1 pageABC AnalysisRajat ShettyNo ratings yet
- Globalisation Strategies Prof Bharat NadkarniDocument15 pagesGlobalisation Strategies Prof Bharat NadkarniRajat ShettyNo ratings yet
- Google Case StudyDocument1 pageGoogle Case StudyRajat ShettyNo ratings yet
- Decision Making: Prof Bharat NadkarniDocument38 pagesDecision Making: Prof Bharat NadkarniRajat ShettyNo ratings yet
- Competitive Strategy 1Document73 pagesCompetitive Strategy 1karan chhabraNo ratings yet
- Dell Case StudyDocument2 pagesDell Case StudyWarang0% (1)
- GE MatrixDocument13 pagesGE MatrixRajat ShettyNo ratings yet
- Supply Chain ManagementDocument4 pagesSupply Chain ManagementRajat ShettyNo ratings yet
- L3 Yield Management, Overbooking EtcDocument58 pagesL3 Yield Management, Overbooking EtcRajat ShettyNo ratings yet
- Supply Chain Management NotesDocument6 pagesSupply Chain Management NotesRajat ShettyNo ratings yet
- L 4 Strategy Types and ChoicesDocument118 pagesL 4 Strategy Types and ChoicesRajat Shetty100% (1)
- Characteristics of Mass ProductionDocument7 pagesCharacteristics of Mass ProductionRajat ShettyNo ratings yet
- SimulationDocument1 pageSimulationRajat ShettyNo ratings yet
- L 1 Introduction To Strategic MGMTDocument84 pagesL 1 Introduction To Strategic MGMTRajat ShettyNo ratings yet
- L 3 Strategic Planning, Concepts, Operational Planning EtcDocument56 pagesL 3 Strategic Planning, Concepts, Operational Planning EtcRajat ShettyNo ratings yet
- Offshoring and Outsourcing Risks and CapabilitiesDocument68 pagesOffshoring and Outsourcing Risks and CapabilitiesRajat ShettyNo ratings yet
- L4 Manufacturing Resource Planning - IiDocument74 pagesL4 Manufacturing Resource Planning - IiRajat ShettyNo ratings yet
- L 2 Vision Mission Goals EtcDocument88 pagesL 2 Vision Mission Goals EtcRajat ShettyNo ratings yet
- L3 Capacity Planning and ManagementDocument90 pagesL3 Capacity Planning and ManagementRajat ShettyNo ratings yet
- l2 MATERIALS REQUIREMENT PLANNING - IDocument80 pagesl2 MATERIALS REQUIREMENT PLANNING - IRajat ShettyNo ratings yet
- L5 MRP - Ii, Jit and MRP IiDocument48 pagesL5 MRP - Ii, Jit and MRP IiRajat ShettyNo ratings yet
- TPK PPT B.inggrsDocument7 pagesTPK PPT B.inggrsRiyska AmaliaNo ratings yet
- Chapter One: Definition of Statistics: The Word "Statistics" Has Different Meanings To Different Person's .WhenDocument30 pagesChapter One: Definition of Statistics: The Word "Statistics" Has Different Meanings To Different Person's .WhenTadesse AyalewNo ratings yet
- HeteroscedasticityDocument16 pagesHeteroscedasticityKarthik BalajiNo ratings yet
- Chap 003Document15 pagesChap 003Shahmir Hamza AhmedNo ratings yet
- Statistics MCQsDocument9 pagesStatistics MCQsSandesh LohakareNo ratings yet
- Stats Chap03 BlumanDocument86 pagesStats Chap03 BlumanAnonymous IlzpPFINo ratings yet
- Research Method and Senior Project Questions and AnswersDocument106 pagesResearch Method and Senior Project Questions and AnswersMequanent AbebawNo ratings yet
- Estimation and Sampling Answer by WWW - Studyrift.infoDocument14 pagesEstimation and Sampling Answer by WWW - Studyrift.infoSaif Ur RehmanNo ratings yet
- Statistics For The Behavioral Sciences 9th Edition Gravetter Test BankDocument4 pagesStatistics For The Behavioral Sciences 9th Edition Gravetter Test Bankgeoramadartoice8jd0100% (18)
- Study Guide For ECO 3411Document109 pagesStudy Guide For ECO 3411asd1084No ratings yet
- 5-Point Summary, Stem & Leaf Plot, and Z-ScoreDocument7 pages5-Point Summary, Stem & Leaf Plot, and Z-ScoreTonia DousayNo ratings yet
- Stat - Prob 11 - Q3 - SLM - WK5Document12 pagesStat - Prob 11 - Q3 - SLM - WK5Angelica CamaraoNo ratings yet
- STA201 - Assignment 2 Question (Spring2023)Document3 pagesSTA201 - Assignment 2 Question (Spring2023)Alif Bin AsadNo ratings yet
- Research MethodologyDocument18 pagesResearch MethodologyusamaNo ratings yet
- Hasil PraktikumDocument41 pagesHasil PraktikumHasanah EkaNo ratings yet
- Measure of PositionDocument13 pagesMeasure of PositionTrisha Park100% (2)
- Demisse Dalecha Thiesis June2019 - 2Document153 pagesDemisse Dalecha Thiesis June2019 - 2wagogNo ratings yet
- Pronósticos Medición Del Error: Ing. Msc. Luis Eduardo Leguizamon CastellanosDocument15 pagesPronósticos Medición Del Error: Ing. Msc. Luis Eduardo Leguizamon CastellanosJuan Gabriel PáezNo ratings yet
- Dispersion in MathsDocument3 pagesDispersion in MathsVihar PatelNo ratings yet
- Exercise Lecture 4 - Summary MeasureDocument6 pagesExercise Lecture 4 - Summary MeasureAura LeeNo ratings yet
- Business Statistics: Shalabh Singh Room No: 231 Shalabhsingh@iim Raipur - Ac.inDocument58 pagesBusiness Statistics: Shalabh Singh Room No: 231 Shalabhsingh@iim Raipur - Ac.inDipak Kumar PatelNo ratings yet
- S1 Specimen MSDocument6 pagesS1 Specimen MSHeng ChocNo ratings yet
- Introduction to Statistics & Graphs Chapter OutlineDocument60 pagesIntroduction to Statistics & Graphs Chapter OutlineLaiba ZahirNo ratings yet
- Module 2 - Session 1Document18 pagesModule 2 - Session 1Elimer EspinaNo ratings yet
- CIT 2101 - VariationDocument24 pagesCIT 2101 - VariationKristian VillabrozaNo ratings yet