You might also like
- Group Work Project: Mscfe 630 Computational FinanceDocument7 pagesGroup Work Project: Mscfe 630 Computational FinanceCMD AsiaNo ratings yet
- Raunak Nath, Tsega Kassaye Derseh: Members Identified With An "X" Above)Document5 pagesRaunak Nath, Tsega Kassaye Derseh: Members Identified With An "X" Above)umang nath100% (1)
- Mscfe CRT m2Document6 pagesMscfe CRT m2Manit Ahlawat100% (1)
- Rasinger, Sebastian Marc-Quantitative Research in Linguistics - An Introduction-Bloomsbury (2013)Document305 pagesRasinger, Sebastian Marc-Quantitative Research in Linguistics - An Introduction-Bloomsbury (2013)IvanVuleFridman100% (1)
- 5 - WQU - 622 CTSP - M5 - CompiledContentDocument34 pages5 - WQU - 622 CTSP - M5 - CompiledContentJoe NgNo ratings yet
- Mscfe XXX (Course Name) - Module X: Collaborative Review TaskDocument57 pagesMscfe XXX (Course Name) - Module X: Collaborative Review TaskManit AhlawatNo ratings yet
- Practice Quiz M4 (UngradedDocument4 pagesPractice Quiz M4 (UngradedFRANCIS YEGONo ratings yet
- MScFE 560 FM - Compiled - Notes - M2 PDFDocument21 pagesMScFE 560 FM - Compiled - Notes - M2 PDFtylerNo ratings yet
- MScFE 560 FM - Compiled - Video - Transcripts - M1Document12 pagesMScFE 560 FM - Compiled - Video - Transcripts - M1Alexandre CabrelNo ratings yet
- Worldquant University EconometricsDocument12 pagesWorldquant University EconometricsIvan SimNo ratings yet
- Practice Quiz M1 (Ungraded) - MergedDocument22 pagesPractice Quiz M1 (Ungraded) - MergedAbdullah Abdullah100% (1)
- Practice Quiz M4.5Document4 pagesPractice Quiz M4.5Iraguha LonginNo ratings yet
- MScFE 650 MLF - Video - Transcripts - M3Document19 pagesMScFE 650 MLF - Video - Transcripts - M3kknsNo ratings yet
- MScFE 650 MLF - Video - Transcripts - M2Document23 pagesMScFE 650 MLF - Video - Transcripts - M2kknsNo ratings yet
- Group Work Project: Mscfe 660 Case Studies in Risk ManagementDocument7 pagesGroup Work Project: Mscfe 660 Case Studies in Risk ManagementHo Thanh Quyen100% (1)
- MScFE 610 ECON - Compiled - Video - Transcripts - M4Document9 pagesMScFE 610 ECON - Compiled - Video - Transcripts - M4sadiqpmpNo ratings yet
- MScFE 560 FM - Compiled - Notes - M5Document21 pagesMScFE 560 FM - Compiled - Notes - M5sadiqpmp0% (1)
- MScFE 650 MLF - Video - Transcripts - M1Document17 pagesMScFE 650 MLF - Video - Transcripts - M1kknsNo ratings yet
- 3 - WQU - 622 CTSP - M3 - CompiledContentDocument31 pages3 - WQU - 622 CTSP - M3 - CompiledContentJoe Ng100% (1)
- 1 - WQU - CTSP - M1 - Compiled - ContentDocument35 pages1 - WQU - CTSP - M1 - Compiled - ContentJoe Ng100% (1)
- Group Project - Trinomial ModelDocument9 pagesGroup Project - Trinomial ModelFrancis MtamboNo ratings yet
- MScFE 620 DTSP Compiled Notes M5Document16 pagesMScFE 620 DTSP Compiled Notes M5sudokuxNo ratings yet
- MScFE 610 Econometrics - CompiledVideo - Transcripts - M2Document14 pagesMScFE 610 Econometrics - CompiledVideo - Transcripts - M2SahahNo ratings yet
- Compiled Notes: Mscfe 610 EconometricsDocument29 pagesCompiled Notes: Mscfe 610 Econometricssadiqpmp100% (1)
- Groupwork Assignment Submission 2 M5Document5 pagesGroupwork Assignment Submission 2 M5Abdullah AbdullahNo ratings yet
- WQU MScFE Discrete-Time Stochastic Processes Module 1Document52 pagesWQU MScFE Discrete-Time Stochastic Processes Module 1muwada huzairu100% (1)
- MScFE 620 DTSP-Compiled-Notes-M5Document13 pagesMScFE 620 DTSP-Compiled-Notes-M5SahahNo ratings yet
- WQU FundamentalsofStochasticFinance m1Document45 pagesWQU FundamentalsofStochasticFinance m1Shravan VenkataramanNo ratings yet
- WQU - DTSP - Module 5 - Compiled - Content PDFDocument32 pagesWQU - DTSP - Module 5 - Compiled - Content PDFvikrantNo ratings yet
- CRT 3Document7 pagesCRT 3Dickson phiriNo ratings yet
- Econometrics SyllabusDocument12 pagesEconometrics SyllabusHo Thanh QuyenNo ratings yet
- WQU - Econometrics - Module2 - Compiled ContentDocument73 pagesWQU - Econometrics - Module2 - Compiled ContentYumiko Huang100% (1)
- WQU - MScFE - Discrete-Time Stochastic Processes - Module 1 PDFDocument52 pagesWQU - MScFE - Discrete-Time Stochastic Processes - Module 1 PDFmuwada huzairuNo ratings yet
- MScFE 620 DTSP - Compiled - Video - Transcripts - M1 PDFDocument14 pagesMScFE 620 DTSP - Compiled - Video - Transcripts - M1 PDFRocApplyNo ratings yet
- Practice Quiz M4.3Document4 pagesPractice Quiz M4.3Iraguha LonginNo ratings yet
- Practice Quiz M4 2Document4 pagesPractice Quiz M4 2sadiqpmpNo ratings yet
- WQU - MScFE - Discrete-Time Stochastic Processes - M2 PDFDocument35 pagesWQU - MScFE - Discrete-Time Stochastic Processes - M2 PDFmuwada huzairu100% (1)
- Unit 2: Elements of Financial Markets: Price Determination and DiscoveryDocument3 pagesUnit 2: Elements of Financial Markets: Price Determination and DiscoverychiranshNo ratings yet
- Quiz M4Document4 pagesQuiz M4FRANCIS YEGONo ratings yet
- MScFE 620 DTSP - Compiled - Notes - M1 PDFDocument25 pagesMScFE 620 DTSP - Compiled - Notes - M1 PDFRocApplyNo ratings yet
- WQU Resource Links Video Lecture SeriesDocument8 pagesWQU Resource Links Video Lecture SeriesDeepak JainNo ratings yet
- (21/04) Mscfe 660 Case Studies in Risk Management (C20-S1) Module 5: The 2008 Global Financial Crisis Practice Quiz M5 (Ungraded)Document4 pages(21/04) Mscfe 660 Case Studies in Risk Management (C20-S1) Module 5: The 2008 Global Financial Crisis Practice Quiz M5 (Ungraded)Abdullah AbdullahNo ratings yet
- Practice Quiz M4 3Document4 pagesPractice Quiz M4 3sadiqpmpNo ratings yet
- (19 - 10) MScFE 622 Continuous-Time Stochastic Processes (C19-S2) - Module 5 Problem SetDocument5 pages(19 - 10) MScFE 622 Continuous-Time Stochastic Processes (C19-S2) - Module 5 Problem SetMoses E.M.K.TommieNo ratings yet
- MScFE 620 DTSP - Video - Transcripts - M1Document14 pagesMScFE 620 DTSP - Video - Transcripts - M1vikrantNo ratings yet
- (21/04) Mscfe 660 Case Studies in Risk Management (C20-S1) Module 5: The 2008 Global Financial Crisis Practice Quiz M5 (Ungraded)Document4 pages(21/04) Mscfe 660 Case Studies in Risk Management (C20-S1) Module 5: The 2008 Global Financial Crisis Practice Quiz M5 (Ungraded)Abdullah AbdullahNo ratings yet
- MScFE 610 ECON - Compiled - Video - Transcripts - M6Document18 pagesMScFE 610 ECON - Compiled - Video - Transcripts - M6sadiqpmpNo ratings yet
- 4.5 Wing Incidence (i) : C − α C C S SDocument1 page4.5 Wing Incidence (i) : C − α C C S SAshutosh KumarNo ratings yet
- WorldQuant+University+Catalog+2 6 19 PDFDocument50 pagesWorldQuant+University+Catalog+2 6 19 PDFRaphael Durães0% (1)
- MSCFE 620 Group SubmissionDocument9 pagesMSCFE 620 Group SubmissionGauravNo ratings yet
- Practice Quiz M5.4Document4 pagesPractice Quiz M5.4Iraguha LonginNo ratings yet
- Practice Quiz M4 5 PDFDocument5 pagesPractice Quiz M4 5 PDFsadiqpmpNo ratings yet
- WQU Annual Report Highlights Online MSFE ProgramDocument40 pagesWQU Annual Report Highlights Online MSFE ProgramImam slaouiNo ratings yet
- DTSP - Compiled Content - Module 7 PDFDocument29 pagesDTSP - Compiled Content - Module 7 PDFvikrantNo ratings yet
- MScFE 560 Financial Markets Quiz M4Document9 pagesMScFE 560 Financial Markets Quiz M4Iraguha LonginNo ratings yet
- WQU Financial Markets Module 5 Compiled ContentDocument29 pagesWQU Financial Markets Module 5 Compiled Contentvikrant50% (2)
- CalculusDocument24 pagesCalculusLorraine SabbaghNo ratings yet
- UGBS 202 Business Mathematics: Session 2 - DifferentiationDocument27 pagesUGBS 202 Business Mathematics: Session 2 - DifferentiationChristiana AdinireNo ratings yet
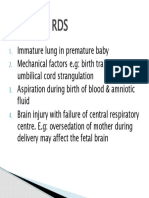
- Causes of RDSDocument1 pageCauses of RDSkknsNo ratings yet
- CessarDocument4 pagesCessarkknsNo ratings yet
- MScFE 650 MLF - Video - Transcripts - M1Document17 pagesMScFE 650 MLF - Video - Transcripts - M1kknsNo ratings yet
- Paeds OphthalDocument74 pagesPaeds OphthalkknsNo ratings yet
- Classroom Climate and Learning EnvironmentDocument16 pagesClassroom Climate and Learning EnvironmentHermie Cardenas100% (4)
- Mary Whiton CalkinsDocument10 pagesMary Whiton CalkinsNiharikaBishtNo ratings yet
- Working StylesDocument7 pagesWorking StylesHichem FakhfekhNo ratings yet
- Major Assignment 2 Socio-Cultural Analysis 1Document17 pagesMajor Assignment 2 Socio-Cultural Analysis 1api-709376968No ratings yet
- Organizational Behavior of McDonaldDocument14 pagesOrganizational Behavior of McDonaldHimanshu SappalNo ratings yet
- Grammar 10th 3 TermDocument24 pagesGrammar 10th 3 TermGonzalez YinaNo ratings yet
- Bahasa InggrisDocument8 pagesBahasa InggrisRizkiOktasariNo ratings yet
- Question Tags: Learn How to Form Questions at the End of SentencesDocument36 pagesQuestion Tags: Learn How to Form Questions at the End of SentencesAna Paula VillelaNo ratings yet
- Introduction To Pain: MakassarDocument55 pagesIntroduction To Pain: MakassarNizwan ShamNo ratings yet
- Business CommunicationDocument323 pagesBusiness CommunicationRadhika AggarwalNo ratings yet
- Behaviour Change Communication AonDocument11 pagesBehaviour Change Communication Aonjoseph OngomaNo ratings yet
- The Edusemiotics of Images. Essays On The Art-Science TarotDocument74 pagesThe Edusemiotics of Images. Essays On The Art-Science TarotCamila Cárdenas NeiraNo ratings yet
- WLP LifeSkills Quarter1 Week1 Module1 Personal DevelopmentDocument7 pagesWLP LifeSkills Quarter1 Week1 Module1 Personal DevelopmentAlhena ValloNo ratings yet
- Module 1 Introduction To Building and Enhancing NewDocument29 pagesModule 1 Introduction To Building and Enhancing NewDanilo de la CruzNo ratings yet
- Who Am I? (Values Education Sample Lesson Plan For All School LevelsDocument3 pagesWho Am I? (Values Education Sample Lesson Plan For All School LevelsJessa Mae de GuzmanNo ratings yet
- Chapter 4 (Synopsis - Framework)Document11 pagesChapter 4 (Synopsis - Framework)muhd syahmiNo ratings yet
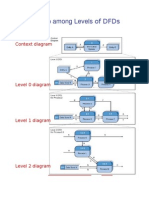
- Relationship Among Levels of DFDsDocument8 pagesRelationship Among Levels of DFDssunny_242574No ratings yet
- 8 Parts of Speech in EnglishDocument51 pages8 Parts of Speech in EnglisharmanoticNo ratings yet
- Nothingness and EventDocument32 pagesNothingness and EventDavid GodarziNo ratings yet
- Update Y2 Lesson Plan Week 15 U7Document17 pagesUpdate Y2 Lesson Plan Week 15 U7Anonymous fK0Wns5X0No ratings yet
- Unit 1: Happiness: What Are The Characteristics of Happy People?Document26 pagesUnit 1: Happiness: What Are The Characteristics of Happy People?Vũ Thanh TúNo ratings yet
- Assessment - Classification ModelDocument6 pagesAssessment - Classification Modelsvpriya233282No ratings yet
- 13.history of The Development of Didactics of Foreign Languages: From The Grammar Translation To Current ApproachesDocument9 pages13.history of The Development of Didactics of Foreign Languages: From The Grammar Translation To Current ApproachesTeresa Pajarón LacaveNo ratings yet
- Service Quality and Students Satisfaction On The School CanteenDocument19 pagesService Quality and Students Satisfaction On The School Canteenjonathan baco100% (1)
- History of Linguistics: From Ancient Speculation to Modern ScienceDocument4 pagesHistory of Linguistics: From Ancient Speculation to Modern SciencemerlotteNo ratings yet
- Influence of Private Schooling on Learning OutcomesDocument2 pagesInfluence of Private Schooling on Learning Outcomes4D RAGUINI, Meeka EllaNo ratings yet
- What Is Test..draftDocument4 pagesWhat Is Test..draftJhonabell AlejanNo ratings yet
- Projectile Motion Introduction Simulation Activity1Document6 pagesProjectile Motion Introduction Simulation Activity1NK - 10CE 703543 Turner Fenton SSNo ratings yet
- Elm-490 Step Template QTDocument20 pagesElm-490 Step Template QTapi-455658662No ratings yet