You might also like
- Apache Spark Interview Questions BookDocument15 pagesApache Spark Interview Questions BookPraneeth Krishna100% (1)
- Install Guide For Sandisk® Memory Zone App To Use Along With Your Sandisk Ultra® Dual DrivesDocument7 pagesInstall Guide For Sandisk® Memory Zone App To Use Along With Your Sandisk Ultra® Dual DrivesGalih PranayudhaNo ratings yet
- SUN2000 2KTL 6KTL L1 Backup Box B0 B1 Luna2000 DTSU666 H ConnectionDocument1 pageSUN2000 2KTL 6KTL L1 Backup Box B0 B1 Luna2000 DTSU666 H ConnectionMiguelASilvaNo ratings yet
- Learn Well Technocraft: Hadoop/Big Data SyllabusDocument12 pagesLearn Well Technocraft: Hadoop/Big Data SyllabusSONAL S.KNo ratings yet
- Compare Hadoop and Spark.: TableDocument10 pagesCompare Hadoop and Spark.: TableconsaniaNo ratings yet
- Big Data Hadoop ArchitectDocument19 pagesBig Data Hadoop ArchitectAnonymous nQ9mMyNo ratings yet
- Tech Seminar ReportDocument5 pagesTech Seminar ReportSaikumar ThuraiNo ratings yet
- BDA-UNIT-6Document14 pagesBDA-UNIT-6belwalkarvaradNo ratings yet
- Big Data Hadoop Architect - V4Document20 pagesBig Data Hadoop Architect - V4Ali AkbarNo ratings yet
- Spark Interview Ques1Document20 pagesSpark Interview Ques1Nareshkumar NakirikantiNo ratings yet
- Hadoop Vs Spark Vs Kafka - Comparing Big Data & Distributed Streaming ToolsDocument4 pagesHadoop Vs Spark Vs Kafka - Comparing Big Data & Distributed Streaming ToolsadnanbwNo ratings yet
- Certified Hadoop and Spark Course CurriculumDocument9 pagesCertified Hadoop and Spark Course Curriculummano555No ratings yet
- Apache Spark Interview Questions and Answers For 2020Document8 pagesApache Spark Interview Questions and Answers For 2020Shashank AbhishekNo ratings yet
- Cloudera Developer Training for Spark & Hadoop (DSHDocument4 pagesCloudera Developer Training for Spark & Hadoop (DSHAiswarya NimmagaddaNo ratings yet
- Top Spark Interview QuestionsDocument32 pagesTop Spark Interview Questionssrinivas75kNo ratings yet
- "Big Data With Hadoop": Faculty Development Program OnDocument2 pages"Big Data With Hadoop": Faculty Development Program Onpartha peguNo ratings yet
- Dataengineering - v2.0 - PDF - 2 - Batch Processing of Data With Spark and Hadoop On GCP - M2 - Executing Spark On Cloud DataprocDocument67 pagesDataengineering - v2.0 - PDF - 2 - Batch Processing of Data With Spark and Hadoop On GCP - M2 - Executing Spark On Cloud DataprocEdgar SanchezNo ratings yet
- Best Hadoop Online TrainingDocument6 pagesBest Hadoop Online TrainingGeohedrick100% (1)
- Spark IntroductionDocument19 pagesSpark Introductionalpha0No ratings yet
- Apache Hadoop Training For Developers-2013 (Course Content) PDFDocument4 pagesApache Hadoop Training For Developers-2013 (Course Content) PDFDock N DenNo ratings yet
- Hadoop vs. Spark: The New Age of Big DataDocument7 pagesHadoop vs. Spark: The New Age of Big DataadnanbwNo ratings yet
- Big Data AnalyticsDocument2 pagesBig Data AnalyticsTamal DeyNo ratings yet
- Spark TutorialDocument8 pagesSpark TutorialDukool SharmaNo ratings yet
- Bigdata Hadoop Spark - PythonDocument8 pagesBigdata Hadoop Spark - PythonRishiraj PaulNo ratings yet
- It Resume FormateDocument3 pagesIt Resume Formatetiemmanuel38No ratings yet
- Apache SparkDocument25 pagesApache SparkPhillipeSantosNo ratings yet
- Big Data Hadoop & Spark: Certification TrainingDocument22 pagesBig Data Hadoop & Spark: Certification TrainingTimothy SausaNo ratings yet
- Real Time Analytics With Spark and KafkaDocument53 pagesReal Time Analytics With Spark and KafkasulogoNo ratings yet
- DVS Hadoop Development Course Content: M 1-I B DDocument4 pagesDVS Hadoop Development Course Content: M 1-I B DJayaramReddyNo ratings yet
- Spark Interview 4Document10 pagesSpark Interview 4consaniaNo ratings yet
- Spark Interview Questions: Click HereDocument35 pagesSpark Interview Questions: Click HereKeshav KrishnaNo ratings yet
- Apache Spark TutorialDocument6 pagesApache Spark Tutorialabhimanyu thakur100% (1)
- Big DataDocument7 pagesBig Datasukhpreet singhNo ratings yet
- Lesson 01 Course IntroductionDocument29 pagesLesson 01 Course IntroductionJeff NgNo ratings yet
- Rstrainings Hadoop Course Content: Curriculum For Hadoop 2.XDocument7 pagesRstrainings Hadoop Course Content: Curriculum For Hadoop 2.XOut LanderNo ratings yet
- Hadoop Interview QuestionDocument25 pagesHadoop Interview Questionsatish.sathya.a2012No ratings yet
- Cloudera Spark TrainingDocument2 pagesCloudera Spark TrainingsethurammscNo ratings yet
- Spark Interview Questions and AnswersDocument31 pagesSpark Interview Questions and Answerssrinivas75k100% (1)
- Learn Apache SparkDocument31 pagesLearn Apache Sparkabreddy2003100% (1)
- Introduction To Hadoop & SparkDocument28 pagesIntroduction To Hadoop & SparkJustin TalbotNo ratings yet
- Big Data With Hadoop & Spark - IntroductionDocument28 pagesBig Data With Hadoop & Spark - IntroductionPremjit SenguptaNo ratings yet
- Homework 4 (24 11 2022)Document2 pagesHomework 4 (24 11 2022)Prabha KNo ratings yet
- 10 SparkBasicsDocument45 pages10 SparkBasicsPetter PNo ratings yet
- Spark Vs Hadoop Features SparkDocument9 pagesSpark Vs Hadoop Features SparkconsaniaNo ratings yet
- Apache Spark Essential TrainingDocument30 pagesApache Spark Essential TrainingFernando Andrés Hinojosa VillarrealNo ratings yet
- Cloudera Developer Training For Apache SparkDocument3 pagesCloudera Developer Training For Apache SparkkeshNo ratings yet
- Apache Spark For BeginnersDocument30 pagesApache Spark For Beginnersankesh patelNo ratings yet
- DEV3600SlideGuide PDFDocument555 pagesDEV3600SlideGuide PDFcrazysookie7619No ratings yet
- Spark Interview QuestionsDocument7 pagesSpark Interview QuestionsRajesh Sugumaran100% (1)
- Apache Spark Quick GuideDocument21 pagesApache Spark Quick GuideOumaima Alfa100% (1)
- 14 SparkParallelProcessingDocument51 pages14 SparkParallelProcessingPetter PNo ratings yet
- Chicago Crime (2013) Analysis Using Pig and Visualization Using RDocument61 pagesChicago Crime (2013) Analysis Using Pig and Visualization Using RSaurabh SharmaNo ratings yet
- "Analytics Using Apache Spark": (Lightening Fast Cluster Computing)Document99 pages"Analytics Using Apache Spark": (Lightening Fast Cluster Computing)santoshi sairamNo ratings yet
- Top Answers To Spark Interview QuestionsDocument4 pagesTop Answers To Spark Interview QuestionsEjaz AlamNo ratings yet
- Research Paper On Hadoop MapreduceDocument5 pagesResearch Paper On Hadoop Mapreducefzgz6hyt100% (1)
- Big Data HadoopDocument13 pagesBig Data HadoopLakshmi Prasanna KalahastriNo ratings yet
- Heuristic Ladder: Hadoop - Big Data Analytics CourseDocument5 pagesHeuristic Ladder: Hadoop - Big Data Analytics CoursebinoyNo ratings yet
- Hadoop Big Data Skills TrainingDocument8 pagesHadoop Big Data Skills TrainingRambabu GiduturiNo ratings yet
- Teaching Big Data TechnologiesDocument8 pagesTeaching Big Data Technologiessrinivasa helwarNo ratings yet
- Kambar (Poet)Document3 pagesKambar (Poet)Manikantan KothandaramanNo ratings yet
- B Tech Cse Parttime SyallabusDocument74 pagesB Tech Cse Parttime SyallabusManikantan KothandaramanNo ratings yet
- ThiruppavaiDocument15 pagesThiruppavaiManikantan KothandaramanNo ratings yet
- 06 TNDocument28 pages06 TNManikantan KothandaramanNo ratings yet
- Manufacturer: National Instruments Board Assembly Part NumbersDocument3 pagesManufacturer: National Instruments Board Assembly Part NumberspaulpuscasuNo ratings yet
- Display Image in RDLC Report (Microsoft Report Viewer)Document1 pageDisplay Image in RDLC Report (Microsoft Report Viewer)Aung TikeNo ratings yet
- Mitel SX-50 Attendant Console Users GuideDocument87 pagesMitel SX-50 Attendant Console Users GuideRay FerryNo ratings yet
- 250 - Windows ShellcodingDocument116 pages250 - Windows ShellcodingSaw GyiNo ratings yet
- Os Unit 6Document65 pagesOs Unit 6tseNo ratings yet
- Image Classification Using Deep Learning in MatlabDocument12 pagesImage Classification Using Deep Learning in MatlabAshutosh LembheNo ratings yet
- Oriswin DG Suite: User ManualDocument70 pagesOriswin DG Suite: User ManualJuanGabrielVillamizarNo ratings yet
- TUV Maintenance Overide ProcedureDocument3 pagesTUV Maintenance Overide ProcedurejidhinmlcetNo ratings yet
- Standard-Eqp Oq Uv Vis.01.05Document22 pagesStandard-Eqp Oq Uv Vis.01.05Ramon FogarolliNo ratings yet
- LS6 - Digicit - M01 (V1.2)Document40 pagesLS6 - Digicit - M01 (V1.2)als midsayap150% (2)
- Availability Is Not Equal To ReliabilityDocument5 pagesAvailability Is Not Equal To ReliabilityIwan AkurNo ratings yet
- Advanced Meter Management: DetailsDocument2 pagesAdvanced Meter Management: DetailsAndrei SerbanescuNo ratings yet
- Software Requirement Specification: Online Shopping SystemDocument5 pagesSoftware Requirement Specification: Online Shopping SystemShoobhàm ŽdtNo ratings yet
- Robert M. Cruz: Web Developer - SEO Specialist - ICD-10 Coder - Bookeeper - Financial Market ProfessionalDocument4 pagesRobert M. Cruz: Web Developer - SEO Specialist - ICD-10 Coder - Bookeeper - Financial Market ProfessionalRobert CruzNo ratings yet
- Data Analysis In: Dr. Lai Jiangshan Lai@ibcas - Ac.cnDocument42 pagesData Analysis In: Dr. Lai Jiangshan Lai@ibcas - Ac.cnMagesa M. ManduNo ratings yet
- Report On Embedded & IoT Final3Document6 pagesReport On Embedded & IoT Final3Vi LNo ratings yet
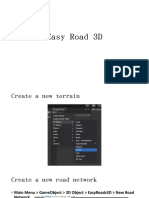
- Easy RoadDocument11 pagesEasy Road許峻嘉No ratings yet
- JWT Social Auth with ASP.NET Core & Xamarin EssentialsDocument10 pagesJWT Social Auth with ASP.NET Core & Xamarin EssentialshsuyipNo ratings yet
- Tle/Tvl Computer Systems Servicing: Department of EducationDocument16 pagesTle/Tvl Computer Systems Servicing: Department of EducationCj Gan100% (1)
- UntitledDocument26 pagesUntitledHunter ZNo ratings yet
- MFL67891020 10Document20 pagesMFL67891020 10Achary BhaswanthNo ratings yet
- Lesson4 Review Question Mark John Ace FloresDocument2 pagesLesson4 Review Question Mark John Ace FloresAce FloresNo ratings yet
- 1 Introduction To IBM Cloud Private - IBM Cloud Garage PDFDocument9 pages1 Introduction To IBM Cloud Private - IBM Cloud Garage PDFMakusNo ratings yet
- ICT Search and Evaluation SkillsDocument47 pagesICT Search and Evaluation SkillsRomel Jasen BibosoNo ratings yet
- DplReference enDocument702 pagesDplReference enCarlos Fuentes CamposNo ratings yet
- Unlocking The Power of Jira Extending Into A Scaled Agile Portfolio Management Solution With OnePlan 072023Document24 pagesUnlocking The Power of Jira Extending Into A Scaled Agile Portfolio Management Solution With OnePlan 072023OnePlanNo ratings yet
- Students Smart Phone Status Report by MandalDocument1 pageStudents Smart Phone Status Report by MandalSn PandiyarajanNo ratings yet
- Introduction to Computer Security and TrendsDocument11 pagesIntroduction to Computer Security and TrendsBen TenNo ratings yet
- HB Sil sq2 Am1 SFC enDocument20 pagesHB Sil sq2 Am1 SFC enmajid asgariNo ratings yet