You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- Telecommunications Engineering: Ele5Tel 1Document31 pagesTelecommunications Engineering: Ele5Tel 1Basit KhanNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Work Health and Safety Policy SamplesDocument3 pagesWork Health and Safety Policy SamplesNg Khai KeongNo ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Sample Exam SolutionDocument8 pagesSample Exam SolutionBasit KhanNo ratings yet
- Telecommunications Engineering: Dr. David Tay Room BG434 X 2529 D.tay@latrobe - Edu.auDocument21 pagesTelecommunications Engineering: Dr. David Tay Room BG434 X 2529 D.tay@latrobe - Edu.auBasit KhanNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Telecommunications Engineering Bandpass Modulation Demodulation TechniquesDocument36 pagesTelecommunications Engineering Bandpass Modulation Demodulation TechniquesBasit KhanNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Classification and nature of hardware faultsDocument9 pagesClassification and nature of hardware faultsBasit KhanNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Lecture Slides 2Document26 pagesLecture Slides 2Basit KhanNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Telecommunications Engineering: Ele5Tel 1Document31 pagesTelecommunications Engineering: Ele5Tel 1Basit KhanNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- 1.1 Fault Classification (Ebook)Document8 pages1.1 Fault Classification (Ebook)Basit KhanNo ratings yet
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Lecture Slides 3Document35 pagesLecture Slides 3Basit KhanNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Building Materials: 1. Building Stones 2. Bricks and Clay Products 3. Timber and Wood ProductsDocument31 pagesBuilding Materials: 1. Building Stones 2. Bricks and Clay Products 3. Timber and Wood ProductsBasit KhanNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- BSBWOR502A Class Assessment ProjectDocument4 pagesBSBWOR502A Class Assessment ProjectBasit KhanNo ratings yet
- 07374221Document6 pages07374221Basit KhanNo ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- AdHoc On-Demand Distance Vector RoutingDocument11 pagesAdHoc On-Demand Distance Vector Routingapi-3741689No ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- 04fault TolerantNetworksDocument23 pages04fault TolerantNetworksBasit KhanNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- 06705367Document6 pages06705367Basit KhanNo ratings yet
- 07019822Document5 pages07019822Basit KhanNo ratings yet
- BSBWOR502B Assessment 3Document5 pagesBSBWOR502B Assessment 3Basit KhanNo ratings yet
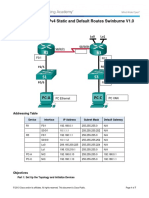
- 2.2.2.5 Lab - Configuring IPv4 Static and Default Routes - Swinburne - V1.0Document7 pages2.2.2.5 Lab - Configuring IPv4 Static and Default Routes - Swinburne - V1.0Basit KhanNo ratings yet
- Lecture Slides 3Document35 pagesLecture Slides 3Basit KhanNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- AdHoc On-Demand Distance Vector RoutingDocument11 pagesAdHoc On-Demand Distance Vector Routingapi-3741689No ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2219)
- Week 9 - 10 Border Gateway Protocol (BGP) LectureDocument78 pagesWeek 9 - 10 Border Gateway Protocol (BGP) LectureBasit KhanNo ratings yet
- Pte Imp Things and LinksDocument1 pagePte Imp Things and LinksBasit KhanNo ratings yet
- Modulation and Coding LectureDocument29 pagesModulation and Coding LectureBasit KhanNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Week 7 - Lecture 13 - Link State ProtocolsDocument30 pagesWeek 7 - Lecture 13 - Link State ProtocolsBasit KhanNo ratings yet
- A Survey On Routing Protocols For Wireless Sensor NetworksDocument25 pagesA Survey On Routing Protocols For Wireless Sensor NetworksThang Nguyen DucNo ratings yet
- Assignment No. 10Document32 pagesAssignment No. 10Basit Khan100% (1)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (119)
- Lecture Slides 3Document35 pagesLecture Slides 3Basit KhanNo ratings yet
- 04a1 Revision OSI TCP IPDocument19 pages04a1 Revision OSI TCP IPBasit KhanNo ratings yet
- ISO 9001:2015 certified Fargo Courier with over 100 branchesDocument1 pageISO 9001:2015 certified Fargo Courier with over 100 branchesMuchiri NahashonNo ratings yet
- 11 Letter WordsDocument637 pages11 Letter WordstrakdsNo ratings yet
- ThesisDocument5 pagesThesisPaul StNo ratings yet
- Conditionals MixedDocument2 pagesConditionals MixedAurelia Mihaela SoleaNo ratings yet
- Ks3 Mathematics 2009 Level 3 5 Paper 2Document28 pagesKs3 Mathematics 2009 Level 3 5 Paper 2spopsNo ratings yet
- Acute cholecystitis pathogenesis, diagnosis and clinical featuresDocument38 pagesAcute cholecystitis pathogenesis, diagnosis and clinical featuresAdrian BăloiNo ratings yet
- Fitness To Work Offshore GuidelineDocument28 pagesFitness To Work Offshore GuidelineMohd Zaha Hisham100% (2)
- Military Organization of the Anglo-Saxon FyrdDocument24 pagesMilitary Organization of the Anglo-Saxon FyrdMiguel TrindadeNo ratings yet
- Measuring Speed of Light LabDocument5 pagesMeasuring Speed of Light LabTanzid SultanNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Speaking Tasks 8 - B1+Document2 pagesSpeaking Tasks 8 - B1+Wayra EvelynNo ratings yet
- Real Estate Appraisal Report PDFDocument55 pagesReal Estate Appraisal Report PDFSteven Bailey100% (4)
- ShakespeareDocument4 pagesShakespeareVrinda PatilNo ratings yet
- REduce BAil 22Document2 pagesREduce BAil 22Pboy SolanNo ratings yet
- Verbal and Nonverbal Communication - Business Communication Skills For ManagersDocument7 pagesVerbal and Nonverbal Communication - Business Communication Skills For ManagersCINDY BALANONNo ratings yet
- Jopillo Vs PeopleDocument1 pageJopillo Vs PeopleivybpazNo ratings yet
- De Onde Eu Te VejoDocument2 pagesDe Onde Eu Te VejoBianca Oliveira CoelhoNo ratings yet
- 3 Week Lit 121Document48 pages3 Week Lit 121Cassandra Dianne Ferolino MacadoNo ratings yet
- Problem Based Learning Integrating 21 Century Skills: Prepared By:-Alamelu Manggai Ponnusamy Santha Kumari KrishnanDocument18 pagesProblem Based Learning Integrating 21 Century Skills: Prepared By:-Alamelu Manggai Ponnusamy Santha Kumari KrishnanAlamelu Manggai PonnusamyNo ratings yet
- Modernist PoetryDocument14 pagesModernist PoetryFaisal JahangirNo ratings yet
- SHCT 167 Reeves - English Evangelicals and Tudor Obedience, C. 1527-1570 2013 PDFDocument222 pagesSHCT 167 Reeves - English Evangelicals and Tudor Obedience, C. 1527-1570 2013 PDFL'uomo della Rinascitá100% (1)
- Secret Techniques of IN10SE - The October Man SequenceDocument7 pagesSecret Techniques of IN10SE - The October Man SequenceAnonymous 2gIWpUcA8R33% (3)
- Lol Wellness Principles For Dynamic LivingDocument171 pagesLol Wellness Principles For Dynamic LivingTumwine Kahweza ProsperNo ratings yet
- Blooms Taxonomy and Costas Level of QuestioningDocument6 pagesBlooms Taxonomy and Costas Level of QuestioningChris Tine100% (1)
- Article 405: The Penal-Code With AmendmentsDocument2 pagesArticle 405: The Penal-Code With Amendmentsropal salamNo ratings yet
- Equivalence Above Word LevelDocument26 pagesEquivalence Above Word Levelykanariya50% (4)
- GrammarDocument10 pagesGrammarRidhan RahmahNo ratings yet
- Truth V.S. OpinionDocument19 pagesTruth V.S. OpinionBek Ah100% (2)
- PROM PPT UpdatedDocument26 pagesPROM PPT Updatedsaurabh chauhanNo ratings yet
- Puppets in GreeceDocument6 pagesPuppets in GreeceStathis Markopoulos100% (1)
- Music in The United KingdomDocument33 pagesMusic in The United KingdomIonut PetreNo ratings yet
- CompTIA Security+ All-in-One Exam Guide, Sixth Edition (Exam SY0-601)From EverandCompTIA Security+ All-in-One Exam Guide, Sixth Edition (Exam SY0-601)Rating: 5 out of 5 stars5/5 (1)
- Chip War: The Quest to Dominate the World's Most Critical TechnologyFrom EverandChip War: The Quest to Dominate the World's Most Critical TechnologyRating: 4.5 out of 5 stars4.5/5 (227)
- Computer Science: A Concise IntroductionFrom EverandComputer Science: A Concise IntroductionRating: 4.5 out of 5 stars4.5/5 (14)
- CompTIA A+ Certification All-in-One Exam Guide, Eleventh Edition (Exams 220-1101 & 220-1102)From EverandCompTIA A+ Certification All-in-One Exam Guide, Eleventh Edition (Exams 220-1101 & 220-1102)Rating: 5 out of 5 stars5/5 (2)
- Amazon Web Services (AWS) Interview Questions and AnswersFrom EverandAmazon Web Services (AWS) Interview Questions and AnswersRating: 4.5 out of 5 stars4.5/5 (3)
- CompTIA A+ Complete Review Guide: Core 1 Exam 220-1101 and Core 2 Exam 220-1102From EverandCompTIA A+ Complete Review Guide: Core 1 Exam 220-1101 and Core 2 Exam 220-1102Rating: 5 out of 5 stars5/5 (2)
- Chip War: The Fight for the World's Most Critical TechnologyFrom EverandChip War: The Fight for the World's Most Critical TechnologyRating: 4.5 out of 5 stars4.5/5 (82)