You might also like
- Towardsenablingsocialanalysis OfscientificdataDocument4 pagesTowardsenablingsocialanalysis OfscientificdatavthungNo ratings yet
- COCOA: A Synthetic Data Generator for Testing AnonymizationDocument16 pagesCOCOA: A Synthetic Data Generator for Testing AnonymizationDriff SedikNo ratings yet
- The Claremont Report On Database ResearchDocument11 pagesThe Claremont Report On Database Researchfopoci8565No ratings yet
- Dark Data: Are We Solving The Right Problems?Document2 pagesDark Data: Are We Solving The Right Problems?Anand ChaudhariNo ratings yet
- Clarke, 2018Document31 pagesClarke, 20181921 Kaushal MistryNo ratings yet
- Literature Review On Cloud StorageDocument11 pagesLiterature Review On Cloud Storagec5rh6ras100% (1)
- New Approaches to Confidentiality Protection Using Synthetic Data and Remote AccessDocument10 pagesNew Approaches to Confidentiality Protection Using Synthetic Data and Remote Accessabdel_lakNo ratings yet
- #157 Green-JDocument10 pages#157 Green-JekaphrpNo ratings yet
- Quasi-Empirical Scenario Analysis and Its Application To Big Data QualityDocument21 pagesQuasi-Empirical Scenario Analysis and Its Application To Big Data QualityDxtr MedinaNo ratings yet
- Data mining: Past, present and future trends in 40 charactersDocument6 pagesData mining: Past, present and future trends in 40 characterssaajithNo ratings yet
- p198 CuzzocreaDocument6 pagesp198 CuzzocreaDaga.sld5 DagaNo ratings yet
- Nanomaterials, Nanotechnologies and Design: An Introduction for Engineers and ArchitectsFrom EverandNanomaterials, Nanotechnologies and Design: An Introduction for Engineers and ArchitectsRating: 5 out of 5 stars5/5 (2)
- Bringing Science To Digital Forensics With Standardized Forensic CorporaDocument10 pagesBringing Science To Digital Forensics With Standardized Forensic Corporachrisr310No ratings yet
- Digital Forensics and Pathway To Big Data InvestigationDocument14 pagesDigital Forensics and Pathway To Big Data InvestigationOnye olu Ezin'uloNo ratings yet
- What Is Big Data? A Consensual Definition and A Review of Key Research TopicsDocument9 pagesWhat Is Big Data? A Consensual Definition and A Review of Key Research TopicsDaniela StaciNo ratings yet
- Caelli Liu Chang Submit 4Document13 pagesCaelli Liu Chang Submit 4DenisNo ratings yet
- Industrial Applications of Formal Methods to Model, Design and Analyze Computer SystemsFrom EverandIndustrial Applications of Formal Methods to Model, Design and Analyze Computer SystemsNo ratings yet
- Data Mining ToolsDocument13 pagesData Mining ToolsMiguel Angel Riaño TrujilloNo ratings yet
- From Data Mining To Knowledge Discovery in DatabaseDocument18 pagesFrom Data Mining To Knowledge Discovery in Databasekistidi33No ratings yet
- Rijul Research PaperDocument9 pagesRijul Research PaperRijul ChauhanNo ratings yet
- From Patterns in Data To Knowledge Discovery: What Data Mining Can DoDocument5 pagesFrom Patterns in Data To Knowledge Discovery: What Data Mining Can DotiagoNo ratings yet
- DS Requirements and ChallengesDocument9 pagesDS Requirements and Challengesptx023aNo ratings yet
- Research Paper MiningDocument6 pagesResearch Paper Miningtrvlegvkg100% (1)
- Issues in Synthetic Data Generation For Advanced ManufacturingDocument10 pagesIssues in Synthetic Data Generation For Advanced ManufacturingkiloNo ratings yet
- 1 s2.0 S0306457321002089 MainDocument17 pages1 s2.0 S0306457321002089 MainjoaonitNo ratings yet
- Role of DatamingDocument12 pagesRole of Datamingsomuuma1234No ratings yet
- Toward Developing Benchmark Dataset PDFDocument18 pagesToward Developing Benchmark Dataset PDFRahmatul HusnaNo ratings yet
- A Formal Definition of Big Data Based On Its Essential FeaturesDocument12 pagesA Formal Definition of Big Data Based On Its Essential FeaturesRifqiAmaliaNofridaKuntariNo ratings yet
- The Claremont Report On Database ResearchDocument11 pagesThe Claremont Report On Database ResearchvthungNo ratings yet
- Provenance and Scientific WorkflowsDocument6 pagesProvenance and Scientific WorkflowsvthungNo ratings yet
- 0801 2378 PDFDocument63 pages0801 2378 PDFKuppu KarthiNo ratings yet
- Privacy-Preserving Public Auditing Protocol For Low-Performance End Devices in CloudDocument12 pagesPrivacy-Preserving Public Auditing Protocol For Low-Performance End Devices in CloudPriyankaNo ratings yet
- Dawson ThesisDocument7 pagesDawson Thesisbsq39zpf100% (2)
- 10 Challenging Problems in Data Mining ResearchDocument8 pages10 Challenging Problems in Data Mining Researchabhi_cool25No ratings yet
- Qin 2014Document15 pagesQin 2014Aman ShahNo ratings yet
- A Conceptual Overview of Data Mining: B.N. Lakshmi., G.H. RaghunandhanDocument6 pagesA Conceptual Overview of Data Mining: B.N. Lakshmi., G.H. RaghunandhanM Alvinsyah RizalNo ratings yet
- Paul Caspi Dissertation AwardDocument8 pagesPaul Caspi Dissertation AwardBuyCheapPaperOnlineCanada100% (1)
- Crisp-Dm PaperDocument14 pagesCrisp-Dm PaperJManuelNo ratings yet
- Taxonomy of Challenges For Digital ForensicsDocument28 pagesTaxonomy of Challenges For Digital ForensicsasdasdasdasdNo ratings yet
- Survey of Knowledge Discovery and Data Mining Process ModelsDocument24 pagesSurvey of Knowledge Discovery and Data Mining Process Modelsdoud98No ratings yet
- Artigo - The Lowell Database Research Self AssessmentDocument9 pagesArtigo - The Lowell Database Research Self AssessmentJanniele SoaresNo ratings yet
- Mastering Data-Intensive Applications: Building for Scale, Speed, and ResilienceFrom EverandMastering Data-Intensive Applications: Building for Scale, Speed, and ResilienceNo ratings yet
- Sample Literature Review Cloud ComputingDocument10 pagesSample Literature Review Cloud Computingc5h4drzj100% (1)
- Computer ForensicsDocument38 pagesComputer ForensicsJuan Thompson80% (5)
- Research Paper On Surface ComputingDocument5 pagesResearch Paper On Surface Computingfv55wmg4100% (1)
- A Note On The Unification of Information Extraction and Data Mining Using Conditional-Probability, Relational ModelsDocument8 pagesA Note On The Unification of Information Extraction and Data Mining Using Conditional-Probability, Relational ModelsNgô HiềnNo ratings yet
- Three Anti-Forensics Techniques That Pose The Greatest Risks To Digital Forensic InvestigationsDocument12 pagesThree Anti-Forensics Techniques That Pose The Greatest Risks To Digital Forensic InvestigationsAziq RezaNo ratings yet
- Data Consistency in Distributed Systems: Algorithms, Programs, and DatabasesDocument22 pagesData Consistency in Distributed Systems: Algorithms, Programs, and DatabasesSarahNo ratings yet
- Video Mining Research PapersDocument5 pagesVideo Mining Research Papersh02ver8h100% (1)
- Information Fusion: Gema Bello-Orgaz, Jason J. Jung, David CamachoDocument15 pagesInformation Fusion: Gema Bello-Orgaz, Jason J. Jung, David CamachoNajd HemdanaNo ratings yet
- A Survey of Clustering Algorithms For Big Data: Taxonomy & Empirical AnalysisDocument12 pagesA Survey of Clustering Algorithms For Big Data: Taxonomy & Empirical AnalysisahmadlukyrNo ratings yet
- Veracity Assessment of Online Data - 2020 - Decision Support SystemsDocument14 pagesVeracity Assessment of Online Data - 2020 - Decision Support SystemsDhivya RangaNo ratings yet
- Research Paper On Big Data StorageDocument7 pagesResearch Paper On Big Data Storagegwjbmbvkg100% (1)
- Data Mining To Discovery of KnowledgeDocument5 pagesData Mining To Discovery of KnowledgeIJRASETPublicationsNo ratings yet
- Data Warehousing Techniques Through Four Project ExamplesDocument7 pagesData Warehousing Techniques Through Four Project ExamplesFritzie WestNo ratings yet
- Factors Affecting The Adoption of Cloud Computing: An Exploratory StudyDocument13 pagesFactors Affecting The Adoption of Cloud Computing: An Exploratory Studycaco3000No ratings yet
- DREAM3D A Digital Representation Environment For T PDFDocument17 pagesDREAM3D A Digital Representation Environment For T PDFVeerabhadra VeeramustiNo ratings yet
- Traits Ui SlidesDocument122 pagesTraits Ui SlidesPablo Loste RamosNo ratings yet
- Bello Et Al.: A Tutorial On Onset Detection in Music Signals 1041Document1 pageBello Et Al.: A Tutorial On Onset Detection in Music Signals 1041Pablo Loste RamosNo ratings yet
- Lorem IpsumDocument2 pagesLorem Ipsumhomeslice123No ratings yet
- Extremoduro - So Payaso DificilDocument7 pagesExtremoduro - So Payaso DificilPablo Loste RamosNo ratings yet
- Rithmically. This Means That Changes in Loudness Are Judged RelDocument1 pageRithmically. This Means That Changes in Loudness Are Judged RelPablo Loste RamosNo ratings yet
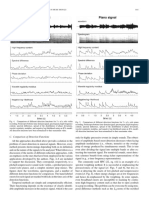
- B. Transient/Steady-State Separation A. Reduction Based On Signal Features 1) Temporal Features: When Observing The Temporal EvoDocument1 pageB. Transient/Steady-State Separation A. Reduction Based On Signal Features 1) Temporal Features: When Observing The Temporal EvoPablo Loste RamosNo ratings yet
- Zing 3Document7 pagesZing 3Pablo Loste RamosNo ratings yet
- Repertorio Booster Ordenado Tempos 151218Document1 pageRepertorio Booster Ordenado Tempos 151218Pablo Loste RamosNo ratings yet
- 4) Time-Frequency and Time-Scale Analysis: An AlternativeDocument1 page4) Time-Frequency and Time-Scale Analysis: An AlternativePablo Loste RamosNo ratings yet
- Automatic Web Page Classification: AbstractDocument10 pagesAutomatic Web Page Classification: AbstractPablo Loste RamosNo ratings yet
- Zing 2Document6 pagesZing 2Pablo Loste RamosNo ratings yet
- Documentation Pybrain PDFDocument75 pagesDocumentation Pybrain PDFPablo Loste RamosNo ratings yet
- Heuristic Algorithms For Extracting Relevant Features in Signal AnalysisDocument8 pagesHeuristic Algorithms For Extracting Relevant Features in Signal AnalysisPablo Loste RamosNo ratings yet
- Zing 4Document5 pagesZing 4Pablo Loste RamosNo ratings yet
- RMDocument1 pageRMPablo Loste RamosNo ratings yet
- Story Segmentation and Detection of Commercials in Broadcast News VideoDocument12 pagesStory Segmentation and Detection of Commercials in Broadcast News VideoPablo Loste RamosNo ratings yet
- COGNITIVEDocument20 pagesCOGNITIVEGaurav JainNo ratings yet
- ZingDocument6 pagesZingPablo Loste RamosNo ratings yet
- ADA456834Document5 pagesADA456834Pablo Loste RamosNo ratings yet
- A Computationally Efficient Speech/music Discriminator For Radio RecordingsDocument4 pagesA Computationally Efficient Speech/music Discriminator For Radio RecordingsPablo Loste RamosNo ratings yet
- Asr03 HMMGMM 4up PDFDocument20 pagesAsr03 HMMGMM 4up PDFPablo Loste RamosNo ratings yet
- Python For Audio ProcessingDocument8 pagesPython For Audio ProcessingevishounetNo ratings yet
- 1999 Waspaa Mfas PDFDocument4 pages1999 Waspaa Mfas PDFPablo Loste RamosNo ratings yet
- Some Recent Research Work at LIUM Based On The Use of CMU SphinxDocument6 pagesSome Recent Research Work at LIUM Based On The Use of CMU SphinxPablo Loste RamosNo ratings yet
- Oferta Ingles Salud Laboral y Seguridad VialDocument1 pageOferta Ingles Salud Laboral y Seguridad VialPablo Loste RamosNo ratings yet
- 10 1 1 86Document37 pages10 1 1 86Thiago SallesNo ratings yet
- Bello TSAP 2005Document13 pagesBello TSAP 2005jesusgollonetNo ratings yet
- The Cmu Sphinx-4 Speech Recognition SystemDocument4 pagesThe Cmu Sphinx-4 Speech Recognition SystemPablo Loste RamosNo ratings yet
- Audio-Speech Segmentation and Topic Detection For A Speech-Based Information Retrieval SystemDocument7 pagesAudio-Speech Segmentation and Topic Detection For A Speech-Based Information Retrieval SystemPablo Loste RamosNo ratings yet
- Effcient Voice Activity Detection Algorithms Using Long-Term Speech InformationDocument17 pagesEffcient Voice Activity Detection Algorithms Using Long-Term Speech InformationAnshuman KumarNo ratings yet
- Cash Flow StatementDocument2 pagesCash Flow StatementEvy Nonita AnggusNo ratings yet
- Prescription AssignmentDocument6 pagesPrescription AssignmentChiela Alcantara BagnesNo ratings yet
- NCC - Binding The Nation Together - National Integration - NDocument4 pagesNCC - Binding The Nation Together - National Integration - Nselva_raj215414No ratings yet
- Self-Learning Materials in Arts: Line Is A Point or A Dot Drawn Continuously, It Can Be Either Straight or CurveDocument12 pagesSelf-Learning Materials in Arts: Line Is A Point or A Dot Drawn Continuously, It Can Be Either Straight or CurveElc Elc ElcNo ratings yet
- PH600 CH 10 Problems PDFDocument5 pagesPH600 CH 10 Problems PDFMike GaoNo ratings yet
- Using Non-Fiction BooklistDocument6 pagesUsing Non-Fiction BooklistTracyNo ratings yet
- James Et Al-2017-Earth Surface Processes and LandformsDocument20 pagesJames Et Al-2017-Earth Surface Processes and Landformsqwerrty1029384756No ratings yet
- Michael Irving Jensen - The Political Ideology of Hamas - A Grassroots Perspective (Library of Modern Middle East Studies) - I. B. Tauris (2009)Document217 pagesMichael Irving Jensen - The Political Ideology of Hamas - A Grassroots Perspective (Library of Modern Middle East Studies) - I. B. Tauris (2009)Andreea Toma100% (1)
- Constitution of India, Law and Engineering QuantumDocument143 pagesConstitution of India, Law and Engineering QuantumKnowledge Factory100% (5)
- Resistivityandresistancemeasurements PDFDocument18 pagesResistivityandresistancemeasurements PDFAshok KumarNo ratings yet
- Direction: Read Each Question Carefully. Choose The Letter of The CorrectDocument4 pagesDirection: Read Each Question Carefully. Choose The Letter of The CorrectHanna Grace HonradeNo ratings yet
- Differentiation Between Complex Tic and Eyelid Myoclonia With Absences: Pediatric Case Report and Brief Review of The LiteratureDocument5 pagesDifferentiation Between Complex Tic and Eyelid Myoclonia With Absences: Pediatric Case Report and Brief Review of The LiteratureAperito InternationalNo ratings yet
- Research About Child Labour in Chocolate IndustryDocument4 pagesResearch About Child Labour in Chocolate Industryduha Abu FarhahNo ratings yet
- Chronicle of the Lodge Fraternitas SaturniDocument4 pagesChronicle of the Lodge Fraternitas SaturniCanKoris100% (1)
- Qdoc - Tips HR Bangalore HR DBDocument27 pagesQdoc - Tips HR Bangalore HR DBHarshitNo ratings yet
- CONCEPTMAPDocument1 pageCONCEPTMAPAziil LiizaNo ratings yet
- Child StudyDocument4 pagesChild Studyapi-265383776No ratings yet
- Henry Derozio and Toru Dutt - Pioneers of Indian English PoetryDocument14 pagesHenry Derozio and Toru Dutt - Pioneers of Indian English PoetrySwatarup KapporNo ratings yet
- Pasan Ko Ang DaigdigDocument1 pagePasan Ko Ang DaigdigJermaine Rae Arpia Dimayacyac0% (1)
- Is Umeme Worth 300 BillionsDocument5 pagesIs Umeme Worth 300 Billionsisaac setabiNo ratings yet
- Axe - Positioning - v0.2Document6 pagesAxe - Positioning - v0.2Karthik Kota100% (1)
- G8DLL Q2W6 LC32-34Document17 pagesG8DLL Q2W6 LC32-34Joemard FranciscoNo ratings yet
- Konseling Tentang Kesehatan ReproduksiDocument2 pagesKonseling Tentang Kesehatan ReproduksiClarissa JulianaNo ratings yet
- DLP Format - FilipinoDocument4 pagesDLP Format - FilipinoLissa Mae MacapobreNo ratings yet
- Handbook of Psychiatry 2021Document73 pagesHandbook of Psychiatry 2021Dragutin Petrić100% (2)
- Concept of Professional Ethics and BioethicsDocument21 pagesConcept of Professional Ethics and BioethicsTina TalmadgeNo ratings yet
- ProbationDocument3 pagesProbationElsile BetitoNo ratings yet
- CiviljointpdfDocument8 pagesCiviljointpdfAyashu PandeyNo ratings yet
- An Introduction To Identification & Intervention For Children With Sensory Processing DifficultiesDocument92 pagesAn Introduction To Identification & Intervention For Children With Sensory Processing DifficultiesFrancisca CondutoNo ratings yet
- Finding the Common Point of Convex SetsDocument18 pagesFinding the Common Point of Convex SetsAditya PillaiNo ratings yet