You might also like
- Python Programming (R18A0588) : Laboratory ManualDocument61 pagesPython Programming (R18A0588) : Laboratory ManualPriya GNo ratings yet
- OB AviDocument66 pagesOB AviAwais SiddiquiNo ratings yet
- Machine Learning - Intro to ML LabDocument68 pagesMachine Learning - Intro to ML LabvishalNo ratings yet
- Synchronous Vs Asynchronous Learning ActivitiesDocument3 pagesSynchronous Vs Asynchronous Learning Activitieswbrower100% (1)
- Living Values Education Activities For Children 3 7 Book 1 Intro and Peace PDFDocument78 pagesLiving Values Education Activities For Children 3 7 Book 1 Intro and Peace PDFRuchi KhemkaNo ratings yet
- Python Essentials 2 0 FAQDocument10 pagesPython Essentials 2 0 FAQAbdirahman ShireNo ratings yet
- 7 Teacher Manual CADocument37 pages7 Teacher Manual CAPremier Car Sales50% (2)
- Python Programming Lab ManualDocument63 pagesPython Programming Lab ManualCSE DEPT CMRTCNo ratings yet
- MIT OS Lab ManualDocument140 pagesMIT OS Lab ManualRitesh SharmaNo ratings yet
- Foundations Test Reviewer For LETDocument92 pagesFoundations Test Reviewer For LETLyka VerdaderoNo ratings yet
- Parents Involvement in Distance LearningDocument16 pagesParents Involvement in Distance LearningRomil Tumobag100% (1)
- 5 VAC Fundamental of Python Programming 19 20Document29 pages5 VAC Fundamental of Python Programming 19 20Palani ArjunanNo ratings yet
- (R18A0588) Python Programming Lab ManualDocument63 pages(R18A0588) Python Programming Lab ManualKingsterz gaming100% (1)
- Machine Learning Summer Training Report Using PythonDocument52 pagesMachine Learning Summer Training Report Using PythonDrishti Gupta27% (15)
- List of TrainingsDocument4 pagesList of TrainingsQazi TauseefNo ratings yet
- Machine Learning Summer Training Report SummaryDocument52 pagesMachine Learning Summer Training Report SummaryIshan PatwalNo ratings yet
- Machine Learning Lab ManualDocument94 pagesMachine Learning Lab Manualshyam9.r9No ratings yet
- Python Report SHREEDocument35 pagesPython Report SHREEBk BalajiNo ratings yet
- Kausshi Final InternDocument22 pagesKausshi Final InternAbiram RNo ratings yet
- Summer Training Report On PythonDocument38 pagesSummer Training Report On Pythonkaushik.umakshiNo ratings yet
- Summer Training Report - Ishan PatwalDocument21 pagesSummer Training Report - Ishan PatwalIshan PatwalNo ratings yet
- DAL Lab FileDocument38 pagesDAL Lab Filepriyank mishraNo ratings yet
- Summer Training ReportDocument16 pagesSummer Training ReportMonsta XNo ratings yet
- Saman RazalDocument8 pagesSaman RazalNarsingh Pal YadavNo ratings yet
- Report First Year UdemyDocument8 pagesReport First Year UdemyNEERAJ LAISHRAMNo ratings yet
- Machine Learning Summer Report Using PythonDocument53 pagesMachine Learning Summer Report Using PythonPranjal BajpaiNo ratings yet
- Internship Report on Text Processing in AIDocument33 pagesInternship Report on Text Processing in AIBk BalajiNo ratings yet
- Industrial TrainingDocument13 pagesIndustrial TrainingRoni SinghNo ratings yet
- Nitin Sharma Python ReportDocument68 pagesNitin Sharma Python ReportNitin SharmaNo ratings yet
- MidTerm Progress ReportDocument21 pagesMidTerm Progress ReportGurkomalpreet KaurNo ratings yet
- Narsingh Pal 2021000405Document8 pagesNarsingh Pal 2021000405Narsingh Pal YadavNo ratings yet
- "Summer Training Report": Award Bachelor of TechnologyDocument21 pages"Summer Training Report": Award Bachelor of TechnologyShivam VatsNo ratings yet
- Internship ReportDocument20 pagesInternship ReportGaurav KushwahNo ratings yet
- Nikhil MOOC ReportDocument16 pagesNikhil MOOC Reportniku13102001No ratings yet
- Python Final Report This Is Phyton SolutionDocument22 pagesPython Final Report This Is Phyton SolutionTarandeep SinghNo ratings yet
- Vegisetti Lokesh 12012015Document43 pagesVegisetti Lokesh 12012015Vikash DeepNo ratings yet
- Intership BKKDocument34 pagesIntership BKKBk BalajiNo ratings yet
- INTERNSHIP REPORT TITLEDocument35 pagesINTERNSHIP REPORT TITLEBk BalajiNo ratings yet
- Toaz - Info Fantasy Cricket Game Using Python Intershala Project PRDocument33 pagesToaz - Info Fantasy Cricket Game Using Python Intershala Project PRAbhishek NautiyalNo ratings yet
- Aiml Lab Mannual 7TH SemDocument35 pagesAiml Lab Mannual 7TH Sembiraa9128No ratings yet
- Ai & ML Lab ManualDocument41 pagesAi & ML Lab ManualAnand DuraiswamyNo ratings yet
- Advance Python Programming ApplicationsDocument14 pagesAdvance Python Programming ApplicationssįleňT HĕąrťNo ratings yet
- Lab Manual LPII 2Document43 pagesLab Manual LPII 2Abhishek PatilNo ratings yet
- Python Programming Manual-21CSL46Document43 pagesPython Programming Manual-21CSL46Ankith Jain100% (1)
- Oop 5 A B Lab Manual 2018 19student1Document64 pagesOop 5 A B Lab Manual 2018 19student1Shalynee SuthaharNo ratings yet
- SC File DHRUV GOEL 44114802717Document50 pagesSC File DHRUV GOEL 44114802717Dhruv GoelNo ratings yet
- Teerthankar Mahaveer University: Database of Fantasy Cricket Game in PythonDocument32 pagesTeerthankar Mahaveer University: Database of Fantasy Cricket Game in PythonArpit SinghNo ratings yet
- Fantasy Cricket Game Using Python Intershala ProjectDocument33 pagesFantasy Cricket Game Using Python Intershala Projectkohinoor kamble100% (1)
- Sakthivel Intern RecDocument22 pagesSakthivel Intern Recsakthivel99900No ratings yet
- Java LabDocument66 pagesJava LabselaiwatNo ratings yet
- Intership BKKDocument34 pagesIntership BKKBk BalajiNo ratings yet
- Artificial Intelligence: K.R. Road, V V Puram, Bangalore-560004Document33 pagesArtificial Intelligence: K.R. Road, V V Puram, Bangalore-560004SURAJ VISHAWAKARMANo ratings yet
- OOPS ManualDocument60 pagesOOPS ManualDisha NijhawanNo ratings yet
- Report (Intenship 2022)Document35 pagesReport (Intenship 2022)Naveen PranouvNo ratings yet
- project file college management system1Document14 pagesproject file college management system1Kamaldeep SinghNo ratings yet
- Python for ML Internship ReportDocument13 pagesPython for ML Internship ReportRitik PanwarNo ratings yet
- Practical 1to10Document32 pagesPractical 1to10hetprajapati2004217No ratings yet
- ITS Report by AmanDocument30 pagesITS Report by AmanAmaan KhokarNo ratings yet
- Python Programming & Data Science Lab ManualDocument25 pagesPython Programming & Data Science Lab ManualSYEDANo ratings yet
- OSTL LabManualDocument36 pagesOSTL LabManualpradnya kingeNo ratings yet
- 22EEE136 PythonLabManualFinalDocument68 pages22EEE136 PythonLabManualFinalcharannaikd03No ratings yet
- KNN, KmeansDocument41 pagesKNN, Kmeanskirsagar akashNo ratings yet
- Cs Project Grade Xi - Akhil CHDocument50 pagesCs Project Grade Xi - Akhil CHakhilnz06No ratings yet
- Vision of The Institute: 4. To Inculcate Professional Behavior, Positive Attitude, and Communication SkillsDocument8 pagesVision of The Institute: 4. To Inculcate Professional Behavior, Positive Attitude, and Communication SkillsNeha KhanNo ratings yet
- PDF Summer Training ReportDocument20 pagesPDF Summer Training ReportNaresh KadyanNo ratings yet
- SECOND YEAR Industrial Training - 3CS7-30 PythonDocument26 pagesSECOND YEAR Industrial Training - 3CS7-30 PythonShubham DwivediNo ratings yet
- Machine Learning with Python: A Comprehensive Guide with a Practical ExampleFrom EverandMachine Learning with Python: A Comprehensive Guide with a Practical ExampleNo ratings yet
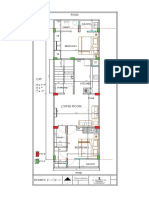
- Architectural plan dimensionsDocument1 pageArchitectural plan dimensionsharshit gargNo ratings yet
- Construction plan dimensionsDocument1 pageConstruction plan dimensionsharshit gargNo ratings yet
- Document summaryDocument1 pageDocument summaryharshit gargNo ratings yet
- R.K. Architects and Engineers: (Min or Depth of Lintel)Document1 pageR.K. Architects and Engineers: (Min or Depth of Lintel)harshit gargNo ratings yet
- Foundation plan and section detailsDocument1 pageFoundation plan and section detailsharshit gargNo ratings yet
- 15x45 FINALDocument1 page15x45 FINALharshit gargNo ratings yet
- sysparm Stack &sysparm ViewDocument1 pagesysparm Stack &sysparm Viewharshit gargNo ratings yet
- Experiment 1: Aim: Understanding of Machine Learning AlgorithmsDocument7 pagesExperiment 1: Aim: Understanding of Machine Learning Algorithmsharshit gargNo ratings yet
- ML Lab ManualDocument47 pagesML Lab Manualharshit gargNo ratings yet
- Soft Computing: Submitted By: Name: Harshit Garg Roll No: 04414802716 Batch: 8-C-3Document1 pageSoft Computing: Submitted By: Name: Harshit Garg Roll No: 04414802716 Batch: 8-C-3harshit gargNo ratings yet
- viden-K66-STQA-12017-09-18 22 - 30 - 25 PDFDocument40 pagesviden-K66-STQA-12017-09-18 22 - 30 - 25 PDFharshit gargNo ratings yet
- Soft Computing 42714802716 - 19Document6 pagesSoft Computing 42714802716 - 19harshit gargNo ratings yet
- Configure ETL access for Informatica PowerCenterDocument4 pagesConfigure ETL access for Informatica PowerCenterharshit gargNo ratings yet
- UntitledDocument1 pageUntitledharshit gargNo ratings yet
- Class 6Document59 pagesClass 6harshit gargNo ratings yet
- Software Testing Quality Assurance LabDocument10 pagesSoftware Testing Quality Assurance Labharshit gargNo ratings yet
- Assignment Design ExerciseDocument2 pagesAssignment Design Exerciseharshit gargNo ratings yet
- Class 7Document37 pagesClass 7harshit gargNo ratings yet
- Class 8Document49 pagesClass 8harshit gargNo ratings yet
- Dmbi AssignmentDocument7 pagesDmbi Assignmentharshit gargNo ratings yet
- Class 4Document77 pagesClass 4harshit gargNo ratings yet
- CLASS2Document71 pagesCLASS2harshit gargNo ratings yet
- CLASS1Document33 pagesCLASS1harshit gargNo ratings yet
- 10 Science Notes 09 Heredity and Evolution 1Document16 pages10 Science Notes 09 Heredity and Evolution 1harshit gargNo ratings yet
- 10Document13 pages10harshit gargNo ratings yet
- GP Nomination Form Individual Category - ALS - FinalDocument8 pagesGP Nomination Form Individual Category - ALS - FinalMARY JANE VILLOCERO100% (1)
- Introduction To Number: Related Areas of Learning and DevelopmentDocument3 pagesIntroduction To Number: Related Areas of Learning and DevelopmentKLS-KAFRABDOU KAUMEYANo ratings yet
- Moscoso-Rios National High School Weekly Home Learning Plan (Grade 7-Mapeh)Document2 pagesMoscoso-Rios National High School Weekly Home Learning Plan (Grade 7-Mapeh)KD MagbanuaNo ratings yet
- Psychological First Aid Activity PlanDocument3 pagesPsychological First Aid Activity PlanRey Bryan BiongNo ratings yet
- Education AIDocument1 pageEducation AIKHUBAIB AHMEDNo ratings yet
- Study Skills Assessment ResultsDocument3 pagesStudy Skills Assessment ResultsNsow1177No ratings yet
- Performance Task 1 - Attempt Review RSCH 122Document6 pagesPerformance Task 1 - Attempt Review RSCH 122John Dexter LanotNo ratings yet
- Collaborative Learning TechnologiesDocument6 pagesCollaborative Learning TechnologiesLeah Patricia GoNo ratings yet
- IB Nov 2018 Exam ScheduleDocument5 pagesIB Nov 2018 Exam ScheduleAnonymous FM0tPhyfN50% (2)
- Reflection Place ValueDocument3 pagesReflection Place ValueHessa MohammedNo ratings yet
- Emotional Intelligence for Workplace LeadersDocument11 pagesEmotional Intelligence for Workplace LeadersJeromeNo ratings yet
- General Areas of EducationDocument40 pagesGeneral Areas of EducationkyozumeNo ratings yet
- ANN Deep Learning Course Structure AUG-DEC2023Document1 pageANN Deep Learning Course Structure AUG-DEC2023blend.saketkumarNo ratings yet
- Interactive White Board AssignmentDocument1 pageInteractive White Board Assignmentstephenb1309No ratings yet
- File 1Document5 pagesFile 1Rifdi JohariNo ratings yet
- Conversación en InglesDocument3 pagesConversación en InglesJhon Jairo SánchezNo ratings yet
- READING 1: Good Teachers Are Made, Not BornDocument2 pagesREADING 1: Good Teachers Are Made, Not BornNante Longos-Rivas Galanida-ManteNo ratings yet
- The Effect of WebQuest in Improving Reading ComprehensionDocument16 pagesThe Effect of WebQuest in Improving Reading ComprehensionSri AstutiNo ratings yet
- E Ipcrf Ebacuado, Joynalyn F.Document9 pagesE Ipcrf Ebacuado, Joynalyn F.Joynalyn Ebacuado- AdvientoNo ratings yet
- Tecnicas de NatacionDocument189 pagesTecnicas de NatacionJJMETALNo ratings yet
- Classroom Instruction Delivery Alignment Map: Alegria, Murcia, Negros OccidentalDocument8 pagesClassroom Instruction Delivery Alignment Map: Alegria, Murcia, Negros OccidentalRolyn RolynNo ratings yet
- Parent Letter (2nd Semester)Document1 pageParent Letter (2nd Semester)mishi19No ratings yet
- Brendan Barry ResumeDocument2 pagesBrendan Barry Resumeapi-546267758No ratings yet