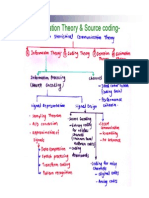
You might also like
- COMM 552 - Information Theory and Coding Lecture - Huffman's Minimum Redundancy CodeDocument23 pagesCOMM 552 - Information Theory and Coding Lecture - Huffman's Minimum Redundancy CodeDonia Mohammed AbdeenNo ratings yet
- Huffman Coding TechniqueDocument13 pagesHuffman Coding TechniqueAnchal RathoreNo ratings yet
- Introduction To Digital Communications and Information TheoryDocument8 pagesIntroduction To Digital Communications and Information TheoryRandall GloverNo ratings yet
- Module 3: Shannon-Fano, Huffman Coding and Data CompressionDocument16 pagesModule 3: Shannon-Fano, Huffman Coding and Data CompressionSagar C VNo ratings yet
- Data Compression TechniquesDocument11 pagesData Compression Techniquessmile00972No ratings yet
- (Karrar Shakir Muttair) CodingDocument33 pages(Karrar Shakir Muttair) CodingAHMED DARAJNo ratings yet
- Huffman CodingDocument23 pagesHuffman CodingNazeer BabaNo ratings yet
- Source Coding OmpressionDocument34 pagesSource Coding Ompression최규범No ratings yet
- Huffman Coding 1Document54 pagesHuffman Coding 1dipu ghoshNo ratings yet
- ECEVSP L03 Compression2Document40 pagesECEVSP L03 Compression2HuayiLI1No ratings yet
- Source Coding Theory: TSBK01 Image Coding and Data CompressionDocument14 pagesSource Coding Theory: TSBK01 Image Coding and Data CompressionsrinivaskaredlaNo ratings yet
- TSBK01 Optimal Source Coding Theory LimitsDocument14 pagesTSBK01 Optimal Source Coding Theory LimitsNada TantawyNo ratings yet
- Huffman and Lempel-Ziv-WelchDocument14 pagesHuffman and Lempel-Ziv-WelchDavid SiegfriedNo ratings yet
- Unit I Information Theory & Coding Techniques P IDocument48 pagesUnit I Information Theory & Coding Techniques P IShanmugapriyaVinodkumarNo ratings yet
- Huffman Coding: OutlineDocument12 pagesHuffman Coding: OutlineAneesh DaymaNo ratings yet
- A Huffman-Based Text Encryption Algorithm: H (X) Leads To Zero Redundancy, That Is, Has The ExactDocument7 pagesA Huffman-Based Text Encryption Algorithm: H (X) Leads To Zero Redundancy, That Is, Has The ExactMalik ImranNo ratings yet
- Ch. 3 Huffman Coding OptimizationDocument10 pagesCh. 3 Huffman Coding OptimizationHermandeep KaurNo ratings yet
- Huffman Coding: Related TermsDocument18 pagesHuffman Coding: Related TermsNuredin AbdumalikNo ratings yet
- Lecture35-37 SourceCodingDocument20 pagesLecture35-37 SourceCodingParveen SwamiNo ratings yet
- Chapter 4 - Arithmetic CodingDocument66 pagesChapter 4 - Arithmetic Codingakshay patelNo ratings yet
- Unit 2 - Part 7 Coding Information Sources: 1 Adaptive Variable-Length CodesDocument5 pagesUnit 2 - Part 7 Coding Information Sources: 1 Adaptive Variable-Length CodesfsaNo ratings yet
- Huffman-Based Text Encryption AlgorithmDocument7 pagesHuffman-Based Text Encryption AlgorithmWalter BirchmeyerNo ratings yet
- Chapter 2 Entropy and Huffman Coding TechniquesDocument22 pagesChapter 2 Entropy and Huffman Coding TechniquesDarshan ShahNo ratings yet
- L12, L13, L14, L15, L16 - Module 4 - Source CodingDocument59 pagesL12, L13, L14, L15, L16 - Module 4 - Source CodingMarkkandan ShanmugavelNo ratings yet
- Assignment - Digital CommunicationDocument6 pagesAssignment - Digital CommunicationnetsanetNo ratings yet
- Error-Free Compression: Variable Length CodingDocument13 pagesError-Free Compression: Variable Length CodingVanithaNo ratings yet
- EECS 554 hw3Document2 pagesEECS 554 hw3Fengxing ZhuNo ratings yet
- Data Compression Can Be Achieved by Assigning To of The Data Source andDocument42 pagesData Compression Can Be Achieved by Assigning To of The Data Source andSoftelgin Elijah MulizwaNo ratings yet
- Data Compression Codeword Length OptimizationDocument43 pagesData Compression Codeword Length OptimizationManoj SamarakoonNo ratings yet
- Information Theory and Coding: What You Need To Know in Today's ICE Age!Document44 pagesInformation Theory and Coding: What You Need To Know in Today's ICE Age!Vikranth VikiNo ratings yet
- MMC Module 3 Chapter 1Document32 pagesMMC Module 3 Chapter 1Sourabh dhNo ratings yet
- Chapter 5Document73 pagesChapter 5Bernard Dumoulin (dovadova71)No ratings yet
- Shannon Code Entropy Optimal Data CompressionDocument9 pagesShannon Code Entropy Optimal Data Compression123rNo ratings yet
- CSC 310, Spring 2004 - Assignment #1 SolutionsDocument4 pagesCSC 310, Spring 2004 - Assignment #1 SolutionsPintuabcNo ratings yet
- Truncated HuffmanDocument5 pagesTruncated HuffmanRui MenezesNo ratings yet
- Uniquely Decodable CodesDocument10 pagesUniquely Decodable Codesshashank guptaNo ratings yet
- ECE 154C Homework Assignment #2: Reading Assignment: Recommended: Programming AssignmentDocument8 pagesECE 154C Homework Assignment #2: Reading Assignment: Recommended: Programming AssignmentNayemNo ratings yet
- Mad Unit 3-JntuworldDocument53 pagesMad Unit 3-JntuworldDilip TheLipNo ratings yet
- MIT 6.02 Lecture Notes on Source Coding AlgorithmsDocument17 pagesMIT 6.02 Lecture Notes on Source Coding Algorithmsrafael ribasNo ratings yet
- huffman-codingDocument39 pageshuffman-codingddgChrgrNo ratings yet
- INFORMATION CODING TECHNIQUES FUNDAMENTALSDocument42 pagesINFORMATION CODING TECHNIQUES FUNDAMENTALSexcitekarthikNo ratings yet
- Huffman Coding - WikipediaDocument11 pagesHuffman Coding - Wikipediarommel baldagoNo ratings yet
- 7 ITCT Huffman CodingDocument20 pages7 ITCT Huffman CodingminhvibaNo ratings yet
- Information Theory and CodingDocument12 pagesInformation Theory and CodingPrashaant YerrapragadaNo ratings yet
- Ch. 2 Source Coding-Ppt1 PDFDocument59 pagesCh. 2 Source Coding-Ppt1 PDFOsama AdlyNo ratings yet
- Notes 7 2013 - Arithmetic CodingDocument34 pagesNotes 7 2013 - Arithmetic CodingperhackerNo ratings yet
- Coding and Decoding TechniquesDocument6 pagesCoding and Decoding TechniquesDonika MarkandeNo ratings yet
- String CompressionDocument13 pagesString CompressionvatarplNo ratings yet
- Chapter ThreeDocument30 pagesChapter ThreemekuriaNo ratings yet
- Lec 3 Huffman CodingDocument9 pagesLec 3 Huffman CodingAashish MathurNo ratings yet
- ch3 Part1Document7 pagesch3 Part1hassan IQNo ratings yet
- Raptor Codes: Amin ShokrollahiDocument1 pageRaptor Codes: Amin ShokrollahiRajesh HarikrishnanNo ratings yet
- Ecs452 2Document16 pagesEcs452 2fadjrianah21No ratings yet
- Huffman source coding of discrete memoryless sourceDocument7 pagesHuffman source coding of discrete memoryless sourceManoj KumarNo ratings yet
- Image Compression (Chapter 8) : CS474/674 - Prof. BebisDocument75 pagesImage Compression (Chapter 8) : CS474/674 - Prof. BebisKoushik SupercalifragilisticNo ratings yet
- Ee5143 Pset2 PDFDocument4 pagesEe5143 Pset2 PDFSarthak VoraNo ratings yet
- Huffman Coding AssignmentDocument7 pagesHuffman Coding AssignmentMavine0% (1)
- Optimal Huffman Coding and Binary Tree ConstructionDocument6 pagesOptimal Huffman Coding and Binary Tree ConstructionjitensoftNo ratings yet
- Workshop on Digital Marketing - Day 1 Session 2 Website MarketingDocument101 pagesWorkshop on Digital Marketing - Day 1 Session 2 Website MarketingRohan BorgalliNo ratings yet
- Digital Marketing Day 2 Session 1Document85 pagesDigital Marketing Day 2 Session 1Rohan BorgalliNo ratings yet
- Flip Flop Conversions: - Srtod - Srtojk - Srtot - Jktot - Jktod - Jktosr - Dtot - Dtosr - TtodDocument23 pagesFlip Flop Conversions: - Srtod - Srtojk - Srtot - Jktot - Jktod - Jktosr - Dtot - Dtosr - TtodRohan BorgalliNo ratings yet
- Notes Data Compression and Cryptography Module 6 System SecurityDocument23 pagesNotes Data Compression and Cryptography Module 6 System SecurityRohan BorgalliNo ratings yet
- Workshop On Digital Marketing Day 2 - Session 2 Social Media Marketing - Sachin SadareDocument68 pagesWorkshop On Digital Marketing Day 2 - Session 2 Social Media Marketing - Sachin SadareRohan BorgalliNo ratings yet
- Sequential Circuits: Latches and Flip-FlopsDocument32 pagesSequential Circuits: Latches and Flip-FlopsRohan BorgalliNo ratings yet
- Audio CompressionDocument81 pagesAudio CompressionRohan BorgalliNo ratings yet
- Imc14 05 Dictionary CodesDocument31 pagesImc14 05 Dictionary CodesRohan BorgalliNo ratings yet
- Logic - FamiliesDocument32 pagesLogic - FamiliesRohan BorgalliNo ratings yet
- Image CompressionDocument38 pagesImage CompressionRohan BorgalliNo ratings yet
- Introduction To JPEG Compression - TutorialspointDocument4 pagesIntroduction To JPEG Compression - TutorialspointRohan BorgalliNo ratings yet
- CSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesDocument93 pagesCSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesRohan BorgalliNo ratings yet
- Introduction To JPEG Compression - TutorialspointDocument4 pagesIntroduction To JPEG Compression - TutorialspointRohan BorgalliNo ratings yet
- Audio and Video CompressionDocument16 pagesAudio and Video CompressionRohan BorgalliNo ratings yet
- JPEG Image Compression: - K. M. AishwaryaDocument31 pagesJPEG Image Compression: - K. M. AishwaryaRohan BorgalliNo ratings yet
- Icsfinal 151105082643 Lva1 App6892Document38 pagesIcsfinal 151105082643 Lva1 App6892Rohan BorgalliNo ratings yet
- AICTE - ATAL FDP Program on Data Science and PythonDocument17 pagesAICTE - ATAL FDP Program on Data Science and PythonRohan BorgalliNo ratings yet
- TCOM 370: NOTES 99-10 Data CompressionDocument19 pagesTCOM 370: NOTES 99-10 Data CompressionRohan BorgalliNo ratings yet
- CSEP 590 Data Compression: Adaptive Huffman CodingDocument42 pagesCSEP 590 Data Compression: Adaptive Huffman CodingAhmed MagdyNo ratings yet
- Imc14 05 Dictionary CodesDocument31 pagesImc14 05 Dictionary CodesRohan BorgalliNo ratings yet
- An IIntroduction To Image CompressionDocument29 pagesAn IIntroduction To Image Compressionసదాశివ మద్దిగిరిNo ratings yet
- Icsfinal 151105082643 Lva1 App6892Document38 pagesIcsfinal 151105082643 Lva1 App6892Rohan BorgalliNo ratings yet
- ENTROPY & RUN LENGTH CODING TECHNIQUESDocument45 pagesENTROPY & RUN LENGTH CODING TECHNIQUESRohan BorgalliNo ratings yet
- Unit5imagecompression1 181112025157Document39 pagesUnit5imagecompression1 181112025157Rohan BorgalliNo ratings yet
- Slide9 ShortDocument30 pagesSlide9 Shortmehr66tNo ratings yet
- CSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesDocument93 pagesCSEP 590 Data Compression: Course Policies Introduction To Data Compression Entropy Variable Length CodesRohan BorgalliNo ratings yet
- Teaching SkillDocument31 pagesTeaching SkillRohan BorgalliNo ratings yet
- JPEG Image Compression: - K. M. AishwaryaDocument31 pagesJPEG Image Compression: - K. M. AishwaryaRohan BorgalliNo ratings yet
- Image CompressionDocument38 pagesImage CompressionRohan BorgalliNo ratings yet
- Cec 208 Lecture Notes 1Document9 pagesCec 208 Lecture Notes 1Zaid Habibu100% (1)
- Overview of Alignment Procedures CM12/120 Microscopes: LegendDocument49 pagesOverview of Alignment Procedures CM12/120 Microscopes: LegendManuel CasanovaNo ratings yet
- Jadual Waktu SPM 2010Document2 pagesJadual Waktu SPM 2010sallehGNo ratings yet
- Moisture Management FinishDocument4 pagesMoisture Management FinishDr. Sanket ValiaNo ratings yet
- Colorcoat HPS200 Ultra Harmoniplus DoPDocument1 pageColorcoat HPS200 Ultra Harmoniplus DoPCesar SNo ratings yet
- Contribution of Nearly-Zero Energy Buildings Standards Enforcement To Achieve Carbon Neutral in Urban Area by 2060Document10 pagesContribution of Nearly-Zero Energy Buildings Standards Enforcement To Achieve Carbon Neutral in Urban Area by 2060mercyella prasetyaNo ratings yet
- Soal Reading 1Document4 pagesSoal Reading 1محمد فرحان رزق اللهNo ratings yet
- Fundamentals of Research Methodology For Healthcare Professionals by Gisela Hildegard Van Rensburg Christa Van Der Walt Hilla BrinkDocument225 pagesFundamentals of Research Methodology For Healthcare Professionals by Gisela Hildegard Van Rensburg Christa Van Der Walt Hilla BrinkLeila RKNo ratings yet
- Chi-Square Test of IndependenceDocument15 pagesChi-Square Test of IndependenceGaming AccountNo ratings yet
- Ogre Classic CountersDocument6 pagesOgre Classic Countersgianduja100% (1)
- Interpersonal Communication Self Reflection #1Document5 pagesInterpersonal Communication Self Reflection #1monicawoods705No ratings yet
- Office PoliticsDocument17 pagesOffice Politicsnasif al islamNo ratings yet
- Group 7 - English For TOEFL PreparationDocument26 pagesGroup 7 - English For TOEFL PreparationNindySJaNo ratings yet
- 2019-10-01 Kitchen Garden PDFDocument110 pages2019-10-01 Kitchen Garden PDFLaura GrėbliauskaitėNo ratings yet
- 4.sisgp Eligible Master Programmes 2024 2025-UaDocument74 pages4.sisgp Eligible Master Programmes 2024 2025-UaRuddro IslamNo ratings yet
- Supergene Mineralisation of The Boyongan Porphyry Copper-Gold Deposit, Surigao Del Norte, PhilippinesDocument176 pagesSupergene Mineralisation of The Boyongan Porphyry Copper-Gold Deposit, Surigao Del Norte, PhilippinesGuillermo Hermoza MedinaNo ratings yet
- Effect of Halal Awareness, Halal Logo and Attitude On Foreign Consumers' Purchase IntentionDocument19 pagesEffect of Halal Awareness, Halal Logo and Attitude On Foreign Consumers' Purchase IntentionandiahmadabrarNo ratings yet
- Definition of FamilyDocument6 pagesDefinition of FamilyKeana DacayanaNo ratings yet
- Pa2 MS G10 Math PDFDocument3 pagesPa2 MS G10 Math PDFsidharthNo ratings yet
- Essence of Indian Traditional KnowledgeDocument2 pagesEssence of Indian Traditional KnowledgePavan KocherlakotaNo ratings yet
- Bolted Flanged Joint Creep/Relaxation Results at High TemperaturesDocument7 pagesBolted Flanged Joint Creep/Relaxation Results at High TemperaturesjlbarretoaNo ratings yet
- PS 5.1.2 Enthalpy CalculationsDocument3 pagesPS 5.1.2 Enthalpy Calculationsrichard.gross62No ratings yet
- AStudyof Planning Designand Constructionof Buildingsin Hilly Regionsof IndiaDocument11 pagesAStudyof Planning Designand Constructionof Buildingsin Hilly Regionsof IndiaRiddhi AggarwalNo ratings yet
- GR 12 Notes On Audit Reports Eng AfrDocument2 pagesGR 12 Notes On Audit Reports Eng AfrmvelonhlemsimangoNo ratings yet
- Test of Infant Motor Performance (TIMP)Document6 pagesTest of Infant Motor Performance (TIMP)Juan Pablo NavarroNo ratings yet
- Sales Territory Design & ManagementDocument20 pagesSales Territory Design & Managementsrijit vermaNo ratings yet
- API 579 FFS in CodeCalc/PVEliteDocument4 pagesAPI 579 FFS in CodeCalc/PVEliteSajal Kulshrestha100% (1)
- 2NS SEMESTER Self Instructured Module in Community EngagementDocument31 pages2NS SEMESTER Self Instructured Module in Community EngagementEditha FernandezNo ratings yet
- (Form GNQ 15B) FrickCompPrestartChecklistDocument2 pages(Form GNQ 15B) FrickCompPrestartChecklisteugene mejidanaNo ratings yet
- How to Write a Resume for a Job ApplicationDocument4 pagesHow to Write a Resume for a Job ApplicationPhuong Dang AnhNo ratings yet