You might also like
- Big Data &iot SyDocument2 pagesBig Data &iot SyaddssdfaNo ratings yet
- Ccs341 - Data WarehousingDocument2 pagesCcs341 - Data WarehousingsilambarasanNo ratings yet
- Updated Unit-2Document55 pagesUpdated Unit-2sc0% (1)
- Module-2-MINING DATA STREAMSDocument17 pagesModule-2-MINING DATA STREAMSAswathy V S100% (3)
- Object Oriented Methodologies ComparisonDocument18 pagesObject Oriented Methodologies ComparisonLAVANYA KARTHIKEYANNo ratings yet
- r18 - Big Data Analytics - Cse (DS)Document1 pager18 - Big Data Analytics - Cse (DS)aarthi devNo ratings yet
- Cp5092 CCT - Unit1 - Part1Document2 pagesCp5092 CCT - Unit1 - Part1tamil_delhiNo ratings yet
- Se7204 Big Data Analytics L T P CDocument2 pagesSe7204 Big Data Analytics L T P CSindhuja VigneshwaranNo ratings yet
- B.Tech - AIDS - Business Analytics-CCW331-Elective-III Year AIDS StudentsDocument4 pagesB.Tech - AIDS - Business Analytics-CCW331-Elective-III Year AIDS Studentssrini durveshNo ratings yet
- BDC Previous Papers 2 MarksDocument7 pagesBDC Previous Papers 2 MarksRoshan Mallipeddi100% (1)
- Question Paper Code: Reg. No.Document2 pagesQuestion Paper Code: Reg. No.Ponraj Park100% (1)
- Question Paper Code:: (10×2 20 Marks)Document2 pagesQuestion Paper Code:: (10×2 20 Marks)Ponraj ParkNo ratings yet
- CS2032 Data Warehousing and Data Mining PPT Unit IDocument88 pagesCS2032 Data Warehousing and Data Mining PPT Unit IvdsrihariNo ratings yet
- CS8492 DBMS - Part A & Part BDocument26 pagesCS8492 DBMS - Part A & Part BRAJA.S 41No ratings yet
- Anatomy of A MapReduce JobDocument5 pagesAnatomy of A MapReduce JobkumarNo ratings yet
- Motivation of Data MiningDocument4 pagesMotivation of Data MiningHazael Estabillo LopezNo ratings yet
- CS3492 Database Management Systems Two Mark Questions 1Document38 pagesCS3492 Database Management Systems Two Mark Questions 1lekha100% (1)
- Hive Lecture NotesDocument17 pagesHive Lecture NotesYuvaraj V, Assistant Professor, BCA100% (1)
- OOSE Unitwise QuestionsDocument11 pagesOOSE Unitwise QuestionsJayaramsai Panchakarla100% (1)
- Data Mining Question BankDocument4 pagesData Mining Question Bankachaparala4499No ratings yet
- BigData Unit 2Document15 pagesBigData Unit 2Sreedhar ArikatlaNo ratings yet
- cp5293 Big Data Analytics Unit 5 PDFDocument28 pagescp5293 Big Data Analytics Unit 5 PDFGnanendra KotikamNo ratings yet
- GTU Machine Learning CourseDocument2 pagesGTU Machine Learning CourseEr Umesh ThoriyaNo ratings yet
- CS8091-BIG DATA ANALYTICS UNIT V NotesDocument31 pagesCS8091-BIG DATA ANALYTICS UNIT V Notesanu xerox100% (4)
- AI - Unit I QBDocument1 pageAI - Unit I QBNarendran MuthusamyNo ratings yet
- 4 UNIT-4 Introduction To HadoopDocument154 pages4 UNIT-4 Introduction To HadoopPrakashRameshGadekarNo ratings yet
- 391 - CS8091 Big Data Analytics - Anna University 2017 Regulation SyllabusDocument2 pages391 - CS8091 Big Data Analytics - Anna University 2017 Regulation SyllabusDhruviNo ratings yet
- Lec-1 ML IntroDocument15 pagesLec-1 ML IntroSimanta HazraNo ratings yet
- Retrieval Utilities Improve ResultsDocument19 pagesRetrieval Utilities Improve ResultsTaran RishitNo ratings yet
- DSBDa MCQDocument17 pagesDSBDa MCQnoxexNo ratings yet
- Galgotias University Datascience Lab ManualDocument39 pagesGalgotias University Datascience Lab ManualRaj SinghNo ratings yet
- Database Management Systems NotesDocument2 pagesDatabase Management Systems NotesNitin VisheNo ratings yet
- Question Bank: Subject Name: Artificial Intelligence & Machine Learning Subject Code: 18CS71 Sem: VIIDocument8 pagesQuestion Bank: Subject Name: Artificial Intelligence & Machine Learning Subject Code: 18CS71 Sem: VIIDileep KnNo ratings yet
- SRM Valliammai Engineering College (An Autonomous Institution)Document9 pagesSRM Valliammai Engineering College (An Autonomous Institution)sureshNo ratings yet
- Unit Iii Case Study: InceptionDocument92 pagesUnit Iii Case Study: InceptionLAVANYA KARTHIKEYANNo ratings yet
- HPC: High Performance Computing Course OverviewDocument2 pagesHPC: High Performance Computing Course OverviewHarish MuthyalaNo ratings yet
- Question Bank - Unit 1Document5 pagesQuestion Bank - Unit 1Saloni DalalNo ratings yet
- ME P4252-II Semester - MACHINE LEARNINGDocument48 pagesME P4252-II Semester - MACHINE LEARNINGBibsy Adlin Kumari RNo ratings yet
- Unit 5Document17 pagesUnit 5kumarNo ratings yet
- CS6703 Grid and Cloud Computing Question Paper Nov Dec 2017Document2 pagesCS6703 Grid and Cloud Computing Question Paper Nov Dec 2017Ganesh KumarNo ratings yet
- cp5293 Big Data Analytics Question BankDocument13 pagescp5293 Big Data Analytics Question BankSanguine Shereen0% (1)
- RMM Unit-I Introdution To Data MiningDocument129 pagesRMM Unit-I Introdution To Data MiningSwapnaNo ratings yet
- Big Data Analytics: By: Syed Nawaz Pasha at SR Univeristy Professional Elective-5 B.Tech Iv-Ii SemDocument31 pagesBig Data Analytics: By: Syed Nawaz Pasha at SR Univeristy Professional Elective-5 B.Tech Iv-Ii SemShushanth munna100% (1)
- Data Mining Question BankDocument3 pagesData Mining Question Bankravi3754100% (1)
- Stock Market PredictionDocument20 pagesStock Market PredictionRoopa Ram BoseNo ratings yet
- VTU Exam Question Paper With Solution of 18CS72 Big Data and Analytics Feb-2022-Dr. v. VijayalakshmiDocument25 pagesVTU Exam Question Paper With Solution of 18CS72 Big Data and Analytics Feb-2022-Dr. v. VijayalakshmiWWE ROCKERSNo ratings yet
- DSBDA ORAL Question BankDocument6 pagesDSBDA ORAL Question BankSUnny100% (1)
- Big Data Analytics NotesDocument9 pagesBig Data Analytics Notessanthosh shrinivasNo ratings yet
- cs8592 Ooad PDFDocument210 pagescs8592 Ooad PDFVjay NarainNo ratings yet
- IT6006 Data AnalyticsDocument12 pagesIT6006 Data AnalyticsbalakirubaNo ratings yet
- Multi - Core Architectures and Programming - Lecture Notes, Study Material and Important Questions, AnswersDocument49 pagesMulti - Core Architectures and Programming - Lecture Notes, Study Material and Important Questions, AnswersM.V. TV0% (1)
- Lab 4 - Introduction To SDNDocument28 pagesLab 4 - Introduction To SDNNhung HP100% (1)
- Cloud Computing 2marksDocument6 pagesCloud Computing 2marksSudharsan BalaNo ratings yet
- Module IIDocument22 pagesModule IIjohnsonjoshal5No ratings yet
- Data Mining Lab ManualDocument2 pagesData Mining Lab Manualakbar2694No ratings yet
- Anna University OOPS Question Bank Unit 2Document6 pagesAnna University OOPS Question Bank Unit 2Karthic SundaramNo ratings yet
- Introduction to Machine Learning FundamentalsDocument112 pagesIntroduction to Machine Learning FundamentalsAanchal Padmavat100% (4)
- Handwritten Digit Recognition Using Convolutional Neural NetworksDocument6 pagesHandwritten Digit Recognition Using Convolutional Neural NetworkssososNo ratings yet
- Unit 2 - BD - Big Data Technology FoundationsDocument76 pagesUnit 2 - BD - Big Data Technology FoundationsRAHUL KUMARNo ratings yet
- SLIDE - 1 - Communication Network SecurityDocument30 pagesSLIDE - 1 - Communication Network SecurityRAHUL KUMARNo ratings yet
- AI Agent PDFDocument9 pagesAI Agent PDFRAHUL KUMARNo ratings yet
- Unit 2 - BD - Big Data Technology FoundationsDocument76 pagesUnit 2 - BD - Big Data Technology FoundationsRAHUL KUMARNo ratings yet
- Unit 3 - BD - Big Data ToolsDocument145 pagesUnit 3 - BD - Big Data ToolsRAHUL KUMARNo ratings yet
- AP Lab Assignment 4Document34 pagesAP Lab Assignment 4RAHUL KUMAR100% (1)
- Big Data Tools and Visualization TechniquesDocument32 pagesBig Data Tools and Visualization TechniquesRAHUL KUMARNo ratings yet
- AP Lab Assignment 1Document30 pagesAP Lab Assignment 1Ahmad AlsharefNo ratings yet
- 6th Semester, B.Tech & B.Tech Dual Degree, Object Oriented System Design, IT-3004 (For 2017 (L.E) &2016 & Previous Admitted Batch) - Spring End Semester Examination 2019Document3 pages6th Semester, B.Tech & B.Tech Dual Degree, Object Oriented System Design, IT-3004 (For 2017 (L.E) &2016 & Previous Admitted Batch) - Spring End Semester Examination 2019RAHUL KUMARNo ratings yet
- 4th Semester, B.tech & Dual Degree, Engineering Economics, HS-2002, (2017 L.E.,2016 & Previously Admitted Batch) - Spring End Sem 2018Document5 pages4th Semester, B.tech & Dual Degree, Engineering Economics, HS-2002, (2017 L.E.,2016 & Previously Admitted Batch) - Spring End Sem 2018RAHUL KUMARNo ratings yet
- 5th Semester-CS-B.techB - Tech Dual Degree - (COACS-505) - Computer Organization & Architecture - Regular-2012 & Back of Previous Admitted Batches-Autumn End Semester-2014Document3 pages5th Semester-CS-B.techB - Tech Dual Degree - (COACS-505) - Computer Organization & Architecture - Regular-2012 & Back of Previous Admitted Batches-Autumn End Semester-2014RAHUL KUMARNo ratings yet
- 4th Semester, B.tech & Dual Degree, Computer Organization & Architecture, CS-2006, (2017 L.E.,2016 & 2015 Admitted Batch) - Spring End Sem 2018Document4 pages4th Semester, B.tech & Dual Degree, Computer Organization & Architecture, CS-2006, (2017 L.E.,2016 & 2015 Admitted Batch) - Spring End Sem 2018RAHUL KUMARNo ratings yet
- Studies of Land Restoration On Spoil Heaps From Brown Coal MiningDocument11 pagesStudies of Land Restoration On Spoil Heaps From Brown Coal MiningeftychidisNo ratings yet
- Acoustic Emission InspectionDocument7 pagesAcoustic Emission InspectionAntonio PerezNo ratings yet
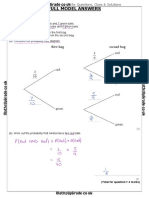
- Probability Tree Diagrams Solutions Mathsupgrade Co UkDocument10 pagesProbability Tree Diagrams Solutions Mathsupgrade Co UknatsNo ratings yet
- Document Revision TableDocument11 pagesDocument Revision Tableseva1969No ratings yet
- CN Assignment 1 COE-540Document5 pagesCN Assignment 1 COE-540Ghazanfar LatifNo ratings yet
- Chen2019 PDFDocument5 pagesChen2019 PDFPriya VeerNo ratings yet
- Pharmacy Perspective on Improving Patient SafetyDocument44 pagesPharmacy Perspective on Improving Patient SafetydicodrNo ratings yet
- Dispersion of Carbon Nanotubes in Water and Non-Aqueous SolventsDocument41 pagesDispersion of Carbon Nanotubes in Water and Non-Aqueous SolventsSantiago OrtizNo ratings yet
- V200 User ManualDocument171 pagesV200 User ManualuriahskyNo ratings yet
- Literature Review On Waste Management in NigeriaDocument9 pagesLiterature Review On Waste Management in NigeriajzneaqwgfNo ratings yet
- TQM 2 MARKSDocument12 pagesTQM 2 MARKSMARIYAPPANNo ratings yet
- Gender Essay Outline Eng102Document3 pagesGender Essay Outline Eng102Ella BobsNo ratings yet
- Gujrat Newspaper IndustryDocument14 pagesGujrat Newspaper IndustryAlok MahajanNo ratings yet
- PV380 Operations ManualDocument20 pagesPV380 Operations ManualCarlosNo ratings yet
- WEG Low Voltage Motor Control Center ccm03 50044030 Brochure English PDFDocument12 pagesWEG Low Voltage Motor Control Center ccm03 50044030 Brochure English PDFRitaban222No ratings yet
- Beef Steaks: MethodDocument2 pagesBeef Steaks: MethodGoshigoshi AkhtarNo ratings yet
- XFARDocument14 pagesXFARRIZA SAMPAGANo ratings yet
- The Behaviour ContinuumDocument2 pagesThe Behaviour Continuumapi-459326447No ratings yet
- Delays in Endoscope Reprocessing and The Biofilms WithinDocument12 pagesDelays in Endoscope Reprocessing and The Biofilms WithinHAITHM MURSHEDNo ratings yet
- Understanding Income Statements EPS CalculationsDocument39 pagesUnderstanding Income Statements EPS CalculationsKeshav KaplushNo ratings yet
- Particle Physics Brick by Brick - Atomic and Subatomic Physics Explained... in LEGO - Dr. Ben Still (Firefly Books 2018 9781844039340 Eng)Document177 pagesParticle Physics Brick by Brick - Atomic and Subatomic Physics Explained... in LEGO - Dr. Ben Still (Firefly Books 2018 9781844039340 Eng)KonstantineNo ratings yet
- 3ms Squence 3 (Summary)Document3 pages3ms Squence 3 (Summary)toumi khadidjaNo ratings yet
- RSG 303Document196 pagesRSG 303Makinde TimiNo ratings yet
- Chemists 12-2023Document7 pagesChemists 12-2023PRC BaguioNo ratings yet
- Video Conferencing Lesson PlanDocument6 pagesVideo Conferencing Lesson PlanANN JILLIAN JOYCE MONDONEDO100% (1)
- Falling Weight Deflectometer (FWD) Projects in IndiaDocument13 pagesFalling Weight Deflectometer (FWD) Projects in IndiaKaran Dave100% (1)
- Perlis V. Composer's Voices From Ives To Ellington PDFDocument506 pagesPerlis V. Composer's Voices From Ives To Ellington PDFOleksii Ternovii100% (1)
- Chapter 6 Physics LabDocument3 pagesChapter 6 Physics Labraquelloveswow0% (1)
- Taxation Management AssignmentDocument11 pagesTaxation Management AssignmentniraliNo ratings yet
- 01 - Narmada M PhilDocument200 pages01 - Narmada M PhilafaceanNo ratings yet