You might also like
- Ion Association in Proton Transfer Reactions: Use of ESR for the Quantitative Determination of Gas Phase Atom and Radical ConcentrationsFrom EverandIon Association in Proton Transfer Reactions: Use of ESR for the Quantitative Determination of Gas Phase Atom and Radical ConcentrationsNo ratings yet
- Progress in Reaction Kinetics: Volume 7From EverandProgress in Reaction Kinetics: Volume 7K. R. JenningsNo ratings yet
- What Can X-Ray Scattering Tell Us About The RDF of WaterDocument13 pagesWhat Can X-Ray Scattering Tell Us About The RDF of WaterFaisal AmirNo ratings yet
- Weak Interactions in Protein FoldingDocument36 pagesWeak Interactions in Protein Foldingnurul9535No ratings yet
- NRTL PDFDocument19 pagesNRTL PDFlauraNo ratings yet
- Journal of Molecular Liquids: Daniel J. Sindhikara, Norio Yoshida, Mikio Kataoka, Fumio HirataDocument3 pagesJournal of Molecular Liquids: Daniel J. Sindhikara, Norio Yoshida, Mikio Kataoka, Fumio Hirataroopra197982No ratings yet
- Role of Water Model On Ion Dissociation at Ambient ConditionsDocument14 pagesRole of Water Model On Ion Dissociation at Ambient ConditionsProficient WritersNo ratings yet
- Andrea Costen - Frontier Molecular Orbital Theory and The Role of Water in The Endo/Exo Diastereoselectivity and Regioselectivity of Intermolecular Diels-Alder ReactionsDocument13 pagesAndrea Costen - Frontier Molecular Orbital Theory and The Role of Water in The Endo/Exo Diastereoselectivity and Regioselectivity of Intermolecular Diels-Alder ReactionsElectro_LiteNo ratings yet
- Statistical Thermodynamics of Liquid Mixtures: P. J. FloryDocument6 pagesStatistical Thermodynamics of Liquid Mixtures: P. J. Floryమత్సా చంద్ర శేఖర్No ratings yet
- Development of Intermolecular Potential Models For Electrolyte Solutions Using An Electrolyte SAFT VR Mie Equation of StateDocument27 pagesDevelopment of Intermolecular Potential Models For Electrolyte Solutions Using An Electrolyte SAFT VR Mie Equation of StatemohammadNo ratings yet
- Bordi2003Document12 pagesBordi2003brouuorbNo ratings yet
- Polarizable Contributions To The Surface Tension of Liquid WaterDocument9 pagesPolarizable Contributions To The Surface Tension of Liquid WatersaeedNo ratings yet
- Modeling Phase Equilibria and Speciation in Mixed-Solvent Electrolyte Systems: II. Liquid-Liquid Equilibria and Properties of Associating Electrolyte SolutionsDocument8 pagesModeling Phase Equilibria and Speciation in Mixed-Solvent Electrolyte Systems: II. Liquid-Liquid Equilibria and Properties of Associating Electrolyte SolutionsWilfredo RuizNo ratings yet
- Quantum Chemical Tests of Water-Water Potential for Interaction Site Water ModelsDocument7 pagesQuantum Chemical Tests of Water-Water Potential for Interaction Site Water ModelsRobost KostNo ratings yet
- Signature Properties of Water: Their Molecular Electronic OriginsDocument6 pagesSignature Properties of Water: Their Molecular Electronic Origins丁竑維No ratings yet
- Wu Et Al. - 2006 - Flexible Simple Point-Charge Water Model With ImprDocument13 pagesWu Et Al. - 2006 - Flexible Simple Point-Charge Water Model With ImprOmar OrabyNo ratings yet
- LJ PotentialDocument6 pagesLJ PotentialFaustoCamachoNo ratings yet
- Kim Selfdiffusionandviscosity 2012Document7 pagesKim Selfdiffusionandviscosity 2012Jasen FerdianNo ratings yet
- Urea Effects On Protein Stability Hydrogen Bonding and The Hydrophobic EffectDocument9 pagesUrea Effects On Protein Stability Hydrogen Bonding and The Hydrophobic EffectChiara VaccaNo ratings yet
- Calculating conductivity of natural watersDocument40 pagesCalculating conductivity of natural watersWajid NizamiNo ratings yet
- 1-s2.0-S0378381224000797-mainDocument16 pages1-s2.0-S0378381224000797-mainMin KookNo ratings yet
- Mathematical Models of Distribution of Water Molecules Regarding Energies of Hydrogen BondsDocument25 pagesMathematical Models of Distribution of Water Molecules Regarding Energies of Hydrogen BondsjrNo ratings yet
- Prediction of Semiconductor Band Edge Positions in Aqueous Environments From First PrinciplesDocument8 pagesPrediction of Semiconductor Band Edge Positions in Aqueous Environments From First PrinciplesDibyajyoti GhoshNo ratings yet
- A Force Field of Li+, Na+, K+, Mg2+, Ca2+, CL, and in Aqueous Solution Based On The TIP4P/2005 Water Model and Scaled Charges For The IonsDocument17 pagesA Force Field of Li+, Na+, K+, Mg2+, Ca2+, CL, and in Aqueous Solution Based On The TIP4P/2005 Water Model and Scaled Charges For The IonsSaeed AbdNo ratings yet
- Determination of Ion-Specific NRTL Parameters For Predicting Phase Equilibria in Aqueous Multielectrolyte SolutionsDocument9 pagesDetermination of Ion-Specific NRTL Parameters For Predicting Phase Equilibria in Aqueous Multielectrolyte Solutionsradouane chatitNo ratings yet
- Solubility and Partitioning (Solubility of Nonelectrolytes in Water)Document11 pagesSolubility and Partitioning (Solubility of Nonelectrolytes in Water)Clarence AG YueNo ratings yet
- JournjlDocument11 pagesJournjlJOVAN HILMANSYAHNo ratings yet
- Article Valorisation Eaux GrisesDocument12 pagesArticle Valorisation Eaux GrisesGérardNo ratings yet
- Solutesolute Interactions in Aqueous Solutions: Additional Information On J. Chem. PhysDocument17 pagesSolutesolute Interactions in Aqueous Solutions: Additional Information On J. Chem. PhysAlissiya FahruzNo ratings yet
- Re-Orientation of Water Molecules in Response To Surface Charge at Surfactant InterfacesDocument9 pagesRe-Orientation of Water Molecules in Response To Surface Charge at Surfactant InterfacesBattulga MunkhbatNo ratings yet
- IR Si RAMANDocument13 pagesIR Si RAMANsimonaNo ratings yet
- Costa 2011Document18 pagesCosta 2011reclatis14No ratings yet
- Inorganic Chemistry in Aq. SolutionsDocument196 pagesInorganic Chemistry in Aq. SolutionsShriram Nandagopal100% (3)
- A Speciation Based Model For Mixed Solvent Electrolyte SystemsDocument36 pagesA Speciation Based Model For Mixed Solvent Electrolyte SystemsYesid Tapiero MartínezNo ratings yet
- Computational and Theoretical Chemistry 2021Document8 pagesComputational and Theoretical Chemistry 2021Venkat1975No ratings yet
- Module 6: Water: Statistical Thermodynamics: Molecules To MachinesDocument7 pagesModule 6: Water: Statistical Thermodynamics: Molecules To MachineskarinaNo ratings yet
- s15 Miller Chap 2a LectureDocument19 pagess15 Miller Chap 2a LectureYannis ZoldenbergNo ratings yet
- Group-Contribution Method for Predicting Activity CoefficientsDocument14 pagesGroup-Contribution Method for Predicting Activity CoefficientsArun EbenezerNo ratings yet
- Draft 75 Applications of Inverse Gas Chromatography in The Study of Liquid Crystalline Stationary PhasesDocument36 pagesDraft 75 Applications of Inverse Gas Chromatography in The Study of Liquid Crystalline Stationary PhasesberkahNo ratings yet
- Group-Contribution Method for Predicting Activity CoefficientsDocument14 pagesGroup-Contribution Method for Predicting Activity Coefficientsm_adnane_dz3184No ratings yet
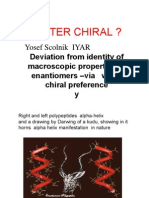
- Is Water Chiral (Experimental Evidence of Chiral Preference of Water) - Yosef ScolnikDocument58 pagesIs Water Chiral (Experimental Evidence of Chiral Preference of Water) - Yosef ScolnikCambiador de MundoNo ratings yet
- Water As The Determinant of Food Engineering Properties. A ReviewDocument13 pagesWater As The Determinant of Food Engineering Properties. A ReviewDavid ZavalaNo ratings yet
- (Jack Barret) Inorganic Chemistry in Aqueous Solut (BookFiDocument196 pages(Jack Barret) Inorganic Chemistry in Aqueous Solut (BookFiasda1997No ratings yet
- Explaining Ionic Liquid Water Solubility in Terms of Cation and Anion HydrophobicityDocument19 pagesExplaining Ionic Liquid Water Solubility in Terms of Cation and Anion HydrophobicityRisdaFitriaNo ratings yet
- Some Theoretical Considerations Concerning Ion Hydration in The Case of Ion Transfer Between Water and 1,2-DichloroethaneDocument19 pagesSome Theoretical Considerations Concerning Ion Hydration in The Case of Ion Transfer Between Water and 1,2-Dichloroethanetestonly261No ratings yet
- Physical Organic Approach To Persistent, Cyclable, Low-Potential Electrolytes For Flow Battery ApplicationsDocument4 pagesPhysical Organic Approach To Persistent, Cyclable, Low-Potential Electrolytes For Flow Battery ApplicationsAli TunaNo ratings yet
- 03.lez 2017-03-09.IntroDrugTargets2Document15 pages03.lez 2017-03-09.IntroDrugTargets2PatriciaSvarreNo ratings yet
- Water Binding Legume Seeds: ThompsonDocument8 pagesWater Binding Legume Seeds: ThompsonAzzahraNo ratings yet
- Pit Zer 1981Document8 pagesPit Zer 1981Niraj ThakreNo ratings yet
- Mean Ionic Activity Coe Cients in Aqueous Nacl Solutions From Molecular Dynamics SimulationsDocument31 pagesMean Ionic Activity Coe Cients in Aqueous Nacl Solutions From Molecular Dynamics SimulationsDona graceNo ratings yet
- Effect of Cation On Room Temperature Ionic LiquidsDocument6 pagesEffect of Cation On Room Temperature Ionic LiquidsGRangarajanNo ratings yet
- Specific Ion Effects: Why DLVO Theory Fails For Biology and Colloid SystemsDocument4 pagesSpecific Ion Effects: Why DLVO Theory Fails For Biology and Colloid SystemslearningboxNo ratings yet
- A068 - Physiological Effect of Mret Activated Water-1Document7 pagesA068 - Physiological Effect of Mret Activated Water-1Tristan LeeNo ratings yet
- Biswas 1998Document5 pagesBiswas 1998Alissiya FahruzNo ratings yet
- Auer1969Document20 pagesAuer1969brouuorbNo ratings yet
- Ie13 2 0170Document6 pagesIe13 2 0170jnwxNo ratings yet
- C 3 RedoxDocument28 pagesC 3 RedoxRina P ShresthaNo ratings yet
- Ch.10 Distribution of Species in Aquatic Systems+Document27 pagesCh.10 Distribution of Species in Aquatic Systems+KhofaxNo ratings yet
- Hydrogen Bonds and Their Importance in PharmaceuticalsDocument12 pagesHydrogen Bonds and Their Importance in PharmaceuticalsJayed SadnanNo ratings yet
- 2D Model of Membrane-Divided Soluble Lead Flow BatteryDocument7 pages2D Model of Membrane-Divided Soluble Lead Flow BatteryJoão PedroNo ratings yet
- Lapara2010.supresion de La Respuesta Inflamatoria LeishmaniaDocument9 pagesLapara2010.supresion de La Respuesta Inflamatoria LeishmaniaLaura GarciaNo ratings yet
- Bailey2019. LC y DepresionDocument22 pagesBailey2019. LC y DepresionLaura GarciaNo ratings yet
- Kingsmore - 2006 - Multiplexed Protein Measurement Technologies andDocument11 pagesKingsmore - 2006 - Multiplexed Protein Measurement Technologies andLaura GarciaNo ratings yet
- Dayakar2015. Evaluacion Del Efecto Inmunomodulador in Vitro e in VivoDocument10 pagesDayakar2015. Evaluacion Del Efecto Inmunomodulador in Vitro e in VivoLaura GarciaNo ratings yet
- Khademvatan2011. iNOS e IFNy en J774 InfectadasDocument8 pagesKhademvatan2011. iNOS e IFNy en J774 InfectadasLaura GarciaNo ratings yet
- Formas de Usar VinaDocument13 pagesFormas de Usar VinaLaura GarciaNo ratings yet
- Deassissouza2013.citoquinas y NO en LCDocument6 pagesDeassissouza2013.citoquinas y NO en LCLaura GarciaNo ratings yet
- Operating/Safety Instructions Consignes D'utilisation/de Sécurité Instrucciones de Funcionamiento y SeguridadDocument52 pagesOperating/Safety Instructions Consignes D'utilisation/de Sécurité Instrucciones de Funcionamiento y SeguridadLaura GarciaNo ratings yet
- Scoring para Predecir SinergismoDocument12 pagesScoring para Predecir SinergismoLaura GarciaNo ratings yet
- Molecules 21 00006Document26 pagesMolecules 21 00006Laura GarciaNo ratings yet
- Ucalgary 2019 Ramezanpour Mohsen PDFDocument451 pagesUcalgary 2019 Ramezanpour Mohsen PDFLaura GarciaNo ratings yet
- Zac2913, Screening de Alto Rendimiento Amastigotes Axenicos Vs Intracelulares ResaltadoDocument10 pagesZac2913, Screening de Alto Rendimiento Amastigotes Axenicos Vs Intracelulares ResaltadoLaura GarciaNo ratings yet
- Falla Terapeutica LeishmaniasisDocument24 pagesFalla Terapeutica LeishmaniasisLaura GarciaNo ratings yet
- PHY1004L. - Lab 7 - Investigating Static and Kinetic FrictionsDocument4 pagesPHY1004L. - Lab 7 - Investigating Static and Kinetic Frictionsdiegocely70061533% (3)
- S TN HNG 001 PDFDocument11 pagesS TN HNG 001 PDFIhab El AghouryNo ratings yet
- Protein Solubility and Stability KitsDocument30 pagesProtein Solubility and Stability KitsSoluble BioScienceNo ratings yet
- Pds Na Gts65hpDocument2 pagesPds Na Gts65hpRahadianLabigaAmidarmoNo ratings yet
- REACTION PATHWAYSDocument28 pagesREACTION PATHWAYSkonstantas100% (2)
- Equilibrium Separation ColumnsDocument18 pagesEquilibrium Separation ColumnsWade ColemanNo ratings yet
- B.Tech ITDocument42 pagesB.Tech ITHemanth DhanasekaranNo ratings yet
- Antibiotics For Research Applications - BioFiles Issue 4.3Document24 pagesAntibiotics For Research Applications - BioFiles Issue 4.3Sigma-AldrichNo ratings yet
- Chemical Reaction Engineering Lab Manuals PDFDocument47 pagesChemical Reaction Engineering Lab Manuals PDFHasan AkhuamariNo ratings yet
- API ISO definitions of gross net total volumesDocument2 pagesAPI ISO definitions of gross net total volumesVu TuanNo ratings yet
- Lecture 9 - Quality AssuranceDocument41 pagesLecture 9 - Quality AssuranceLindaNo ratings yet
- Acid Phosphatase Procedure Brief OverviewDocument3 pagesAcid Phosphatase Procedure Brief OverviewRochellane Ramos PlasabasNo ratings yet
- DNA Sequencing TechniquesDocument16 pagesDNA Sequencing TechniquesAaron CzikNo ratings yet
- Hestcraft Catalog 6-22-10Document44 pagesHestcraft Catalog 6-22-10johnpotterNo ratings yet
- XOMOXDocument16 pagesXOMOXjkpothabathula4581No ratings yet
- Design of Vibrating TableDocument7 pagesDesign of Vibrating Tablesri7877No ratings yet
- Torchshield Quotation KadapaDocument2 pagesTorchshield Quotation KadapaYellaturi Siva Kishore Reddy100% (1)
- Jurassic Au-Skarn and Porphyry Cu Deposits in Ecuador Imply Extensive Metallogenic BeltDocument17 pagesJurassic Au-Skarn and Porphyry Cu Deposits in Ecuador Imply Extensive Metallogenic BeltMichael AltamiranoNo ratings yet
- Man Ci 056enDocument4 pagesMan Ci 056enRicardo AzevedoNo ratings yet
- Simplified Melc-Based Budget of Lessons in General Biology 2Document3 pagesSimplified Melc-Based Budget of Lessons in General Biology 2irene belle dableolesiguesNo ratings yet
- Petrologic Evidence For Boiling To Dryness in The Karaha-Telaga Bodas Geothermal System, IndonesiaDocument10 pagesPetrologic Evidence For Boiling To Dryness in The Karaha-Telaga Bodas Geothermal System, IndonesiaTampan NauliNo ratings yet
- Full TextDocument26 pagesFull TextLucas Felippini RossettiNo ratings yet
- ChromatographyDocument33 pagesChromatographyBhat SaqibNo ratings yet
- Computer Pred I CT Ions For Axiaiiy-Loaded Piies With Non I Near SupportsDocument14 pagesComputer Pred I CT Ions For Axiaiiy-Loaded Piies With Non I Near SupportscmkohNo ratings yet
- Water in Crude Oil by Distillation: Standard Test Method ForDocument11 pagesWater in Crude Oil by Distillation: Standard Test Method ForcfgrdNo ratings yet
- Fluorescence Flow Cytometry: Frequently Asked QuestionsDocument2 pagesFluorescence Flow Cytometry: Frequently Asked Questionsuber6791No ratings yet
- Potentials of Rice-Husk Ash As A Soil StabilizerDocument9 pagesPotentials of Rice-Husk Ash As A Soil StabilizerInternational Journal of Latest Research in Engineering and TechnologyNo ratings yet
- Saep 1146Document8 pagesSaep 1146Ronanki RaviNo ratings yet
- Calculate the cooling capacity of a precooled air handling unitDocument4 pagesCalculate the cooling capacity of a precooled air handling unitPradeep Sukumaran100% (1)
- Measurement of Level in A Tank Using Capacitive Type Level ProbeDocument13 pagesMeasurement of Level in A Tank Using Capacitive Type Level ProbeChandra Sekar100% (1)